黄佳《零基础学机器学习》chap1笔记
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了黄佳《零基础学机器学习》chap1笔记相关的知识,希望对你有一定的参考价值。
黄佳 《零基础学机器学习》 chap1笔记
这本书实在是让我眼前一亮!!! 感觉写的真的太棒了!
文章目录
- 黄佳 《零基础学机器学习》 chap1笔记
- 第1课 机器学习快速上手路径—— 唯有实战
- 1.1 机器学习族谱
- 1.2 云环境
- 1.3 基本的机器学习术语
- 1.4 python和机器学习框架
- 1.5 机器学习项目实战架构
- 1.6 小结
- 1.7 练习
第1课 机器学习快速上手路径—— 唯有实战
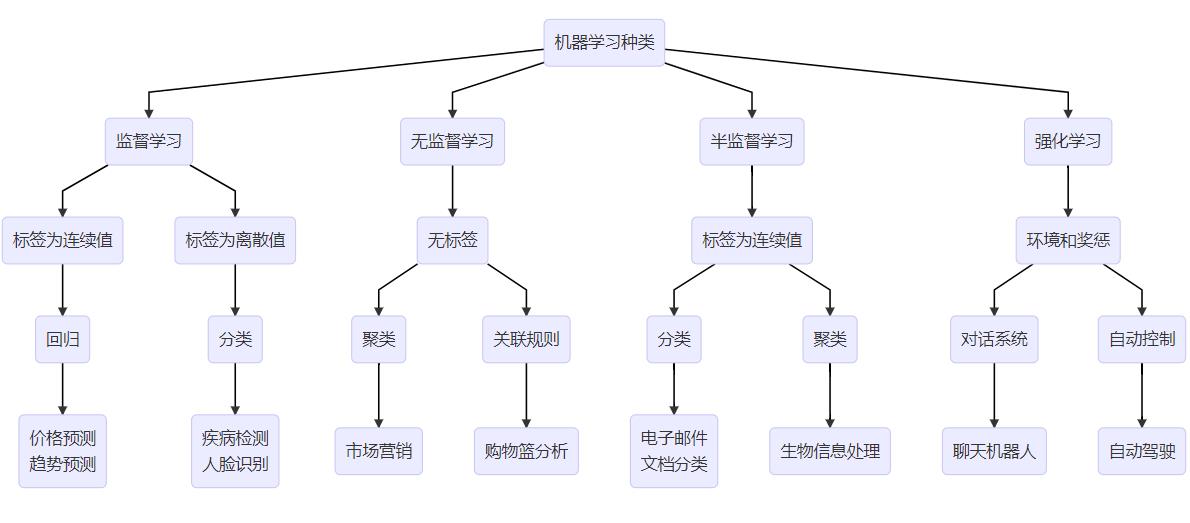
1.1 机器学习族谱
- 下图使用mermaid在typora中绘制
- 一些常见的机器学习应用场景和机器学习模型
1.2 云环境
- Kaggle 和 Colab 都挺好用的
入门实践:推断加州房价
-
读取数据
Kaggle的话注意打开Internet On的按钮
import pandas as pd #导入Pandas,用于数据读取和处理 # 读入房价数据,示例代码中的文件地址为internet链接,读者也可以下载该文件到本机进行读取 # 如,当数据集和代码文件位于相同本地目录,路径名应为"./house.csv",或直接放"house.csv"亦可 df_housing = pd.read_csv("https://raw.githubusercontent.com/huangjia2019/house/master/house.csv") df_housing.head() #显示加州房价数据

-
这是加州各地区房价的整体统计信息(不是 一套套房子的价格信息),是1990年的人口普查结果之一,共包含17 000个样本。其中包含每一个具体地区的经度(longitude)、纬度 (latitude)、房屋的平均年龄(housing_median_age)、房屋数量 (total_rooms)、家庭收入中位数(median_income)等信息,这些信息都是加州地区房价的特征。数据集最后一列“房价中位数” (median_house_value)是标签。
-
这个机器学习项目的目标,就是根据已有的数据样本,对其特征进行推理归纳,得到一个函数模型后,就可以用它推断加州其他地区的房价中位数。
-
构建特征集和标签集
X = df_housing.drop("median_house_value",axis = 1) #构建特征集X y = df_housing.median_house_value #构建标签集y- 上面的代码使用drop方法,把最后一列median_house_value字段去 掉,其他所有字段都保留下来作为特征集X,而这个median_house_value 字段就单独赋给标签集y
-
划分数据集
from sklearn.model_selection import train_test_split #导入数据集拆分工具 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) #以80%/20%的比例进行数据集的拆分- 现在要把数据集一分为二,80%用于机器训练(训练数据集),剩下的留着做测试(测试数据集)如下段代码所示。这也就是告诉机器:你看,拥有这些特征的地方,房价是这样的,等一会儿你想个办法给我猜猜另外20%的地区的房价。
- 其实,另外20%的地区的房价数据,本来就有了,但是我们假装不知道,故意让机器用自己学到的模型去预测。所以,之后通过比较预测值和真值,才知道机器“猜”得准不准,给模型打分
-
选定模型,训练机器,拟合函数,确定参数
from sklearn.linear_model import LinearRegression #导入线性回归算法模型 model = LinearRegression() #使用线性回归算法 model.fit(X_train, y_train) #用训练集数据,训练机器,拟合函数,确定参数- 首先选择LinearRegression(线性回归)作为这个机器学习的模型,这是选定了模型的类型,也就是算法;
- 然后通过其中的fit方法来训练机器,进行函数的拟合。拟合意味着找到最优的函数去模拟训练集中的输入(特征)和目标(标签)的关系,这是确定模型的参数。
-
利用模型进行预测
y_pred = model.predict(X_test) #预测测试集的Y值 print ('房价的真值(测试集)',y_test) print ('预测的房价(测试集)',y_pred) -
给预测打分
print("给预测评分:", model.score(X_test, y_test)) #评估预测结果Sklearn线性回归模型的score属性给出的是R2分数, 它是一个机器学习模型的评估指标,给出的是预测值的方差与总体方 差之间的差异

-
可视化
import matplotlib.pyplot as plt #导入matplotlib画图库 #用散点图显示家庭收入中位数和房价中位数的分布 plt.scatter(X_test.median_income, y_test, color='brown') #画出回归函数(从特征到预测标签) plt.plot(X_test.median_income, y_pred, color='green', linewidth=1) plt.xlabel('Median Income') #X轴-家庭收入中位数 plt.ylabel('Median House Value') #Y轴-房价中位数 plt.show() #显示房价分布和机器习得的函数图形
- 轴的特征太多,无法全部展示,选择了与房价关系最密切的 “家庭收入中位数”median_income作为代表特征来显示散点图。
- 图中的点就是家庭收入/房价分布,而绿色线就是机器学习到的函数模 型,很粗放,都是一条一条的线段拼接而成,但是仍然不难看出,这 个函数模型大概拟合了一种线性关系。
1.3 基本的机器学习术语
| 术语 | 定义 | 数学描述 | 示例 |
|---|---|---|---|
| 数据集 | 数据的集合 | ( X 1 , y 1 ) , ⋯ . ( X n , y n ) \\(X_1,y_1),\\cdots.(X_n,y_n)\\ (X1,y1),⋯.(Xn,yn) | 1000个北京市房屋的面积、楼层、位置、朝向,以及部分房价信息的数据集 |
| 样本 | 数据集中的一条具体记录 | ( X 1 , y 1 ) \\(X_1,y_1)\\ (X1,y1) | 一个房屋的数据记录 |
| 特征 | 用于描述数据的输入变量 | x 1 , x 2 , ⋯ . x n \\x_1,x_2,\\cdots.x_n\\ x1,x2,⋯.xn也是一个向量 | 面积( x 1 x_1 x1)、楼层( x 2 x_2 x2)、位置( x 3 x_3 |