Scala配置和Spark配置以及Scala一些函数的用法(附带词频统计实例)
Posted Icy Hunter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scala配置和Spark配置以及Scala一些函数的用法(附带词频统计实例)相关的知识,希望对你有一定的参考价值。
文章目录
先给出spark和Scala的下载地址,这是我用的版本
https://pan.baidu.com/s/1rcG1xckk3zmp9BLmf74hsg?pwd=1111
也可以自己去官网下载。
配置Spark
解压文件到software文件夹中
tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz
验证:进入spark软件目录下的bin:执行./spark-shell
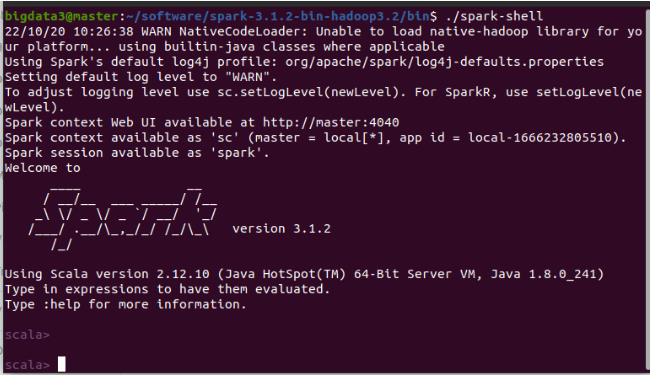
在家目录下,编辑.bashrc,添加如下内容:
export SPARK_HOME=/home/bigdata3/software/spark-3.1.2-bin-hadoop3.2/
export PATH=$SPARK_HOME/bin:$PATH
保存退出后,重开一个终端,直接执行:spark-shell
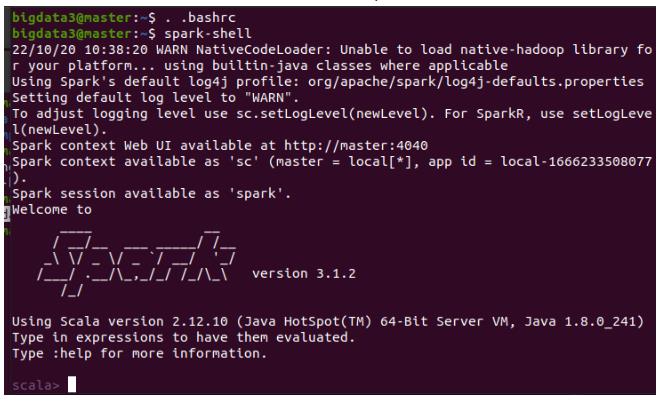
配置成功
配置Scala
下载,解压缩,编辑.bashrc,添加如下内容:
export SCALA_HOME=/home/bigdata3/software/scala-2.12.15
export PATH=$SCALA_HOME/bin:$PATH
保存退出后,重开一个终端,直接执行:scale

配置成功
生成RDD
1)从本地文本文件生成RDD
命令:textFile(URI)
例如:
val myRdd=sc.textFile("file:///home/bigdata3/Desktop/a1.txt")
// 协议 路径
myRdd.collect()

2)从hdfs文本文件生成RDD
val hdfsRdd=sc.textFile("hdfs://172.21.6.156:9000/0126/a.txt")
//namenode 路径
hdfsRdd.collect()

filter过滤器
Rdd数据过滤:
object spark1
def main(args: Array[String]): Unit =
val conf = new SparkConf().setAppName("spark1").setAppName("icy hunter").setMaster("local[*]")
val sc = new SparkContext(conf)
val myRdd = sc.textFile("file:///home/bigdata3/Desktop/a1.txt")
val filterRdd = myRdd.filter(x=>x.contains("AABB"))
val out1 = filterRdd.collect()
out1.foreach(println)
Thread.sleep(1000 * 60 * 5)
这样能够对文件的内容进行过滤,只输出含有“AABB”的内容。
map方法
将Rdd中的每个元素,送入到参数function处理。
使用map将文本文件中的每个单词分开,效果不理想。

因为当分词后,会自动生成一个array,不方便后续解析。
flatMap方法
使用flatMap将文本文件中的每个单词分开:
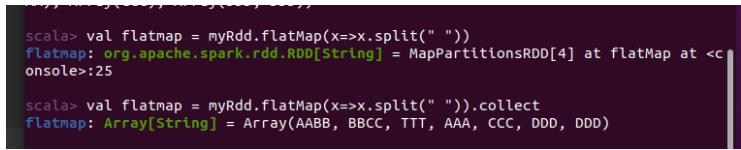
reduceByKey
将(k, v)对按照参数函数进行处理
spark下wordcount程序
分词,构造键值对(词,1),键值对相加
(a, 1)+ (a, 1) = (a, 2)
程序:非链式写法:
def main(args: Array[String]): Unit =
val conf = new SparkConf().setAppName("spark1").setAppName("icy hunter").setMaster("local[*]")
val sc = new SparkContext(conf)
val myRdd = sc.textFile("file:///home/bigdata3/Desktop/a1.txt", 3) //定义Rdd
val flatmap1 = myRdd.flatMap(_.split(" ")) //按空格分词
val mapKV = flatmap1.map((_ ,1))// 创建键值对
val reduce1 = mapKV.reduceByKey(_+_) //将相同键值的键值对相加
reduce1.foreach(println) //输出
Thread.sleep(1000 * 60 * 5)
程序:链式写法:
def main(args: Array[String]): Unit =
val conf = new SparkConf().setAppName("spark1").setAppName("icy hunter").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.textFile("file:///home/bigdata3/Desktop/a1.txt", 3).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).foreach(println)
Thread.sleep(1000 * 60 * 5)
可以想想,如果用java来写,得多麻烦,所以Scala确实轻巧很多。
参考
大数据课的笔记。
以上是关于Scala配置和Spark配置以及Scala一些函数的用法(附带词频统计实例)的主要内容,如果未能解决你的问题,请参考以下文章