深度学习之Python,OpenCV中的卷积
Posted 程序媛一枚~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习之Python,OpenCV中的卷积相关的知识,希望对你有一定的参考价值。
这篇博客将介绍图像内核和卷积。如果将图像视为一个大矩阵,那么图像内核只是一个位于图像顶部的微小矩阵。从左到右和从上到下滑动内核,计算输入图像和内核之间的元素乘法总和——称这个值为内核输出。内核输出存储在与输入图像相同 (x, y) 坐标的输出图像中(在考虑任何填充以确保输出图像具有与输入相同的尺寸后)。
鉴于对卷积的新了解,定义了一个OpenCV和Python函数来将一系列内核应用于图像。包括平滑模糊图像、锐化图像、拉普拉斯内核并检测边缘,sobel_x,y内核查找图像的梯度变化等操作。
最后,简要讨论了核/卷积在深度学习中扮演的角色,特别是卷积神经网络,以及如何自动学习这些过滤器,而不是需要先手动定义它们。手动实现卷积函数是为了明白卷积是怎么计算的,以及opencv自带的卷积函数cv2.filter2D。
1. 效果图
将图像视为大矩阵,将内核视为小矩阵(至少相对于原始的“大矩阵”图像):
内核是一个小矩阵,在较大的图像上从左到右和从上到下滑动。在输入图像中的每个像素处,图像的邻域与内核卷积并存储输出。
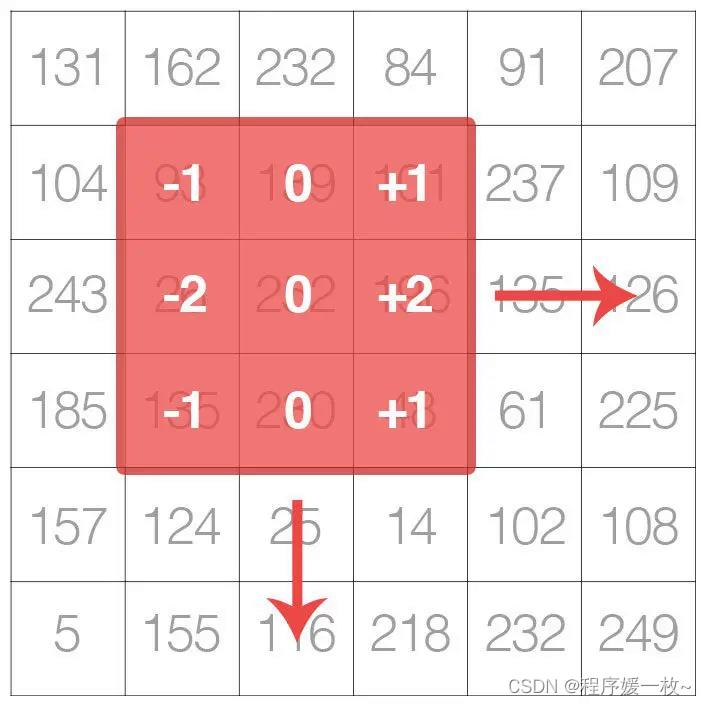
卷积运算符可以应用于 RGB(或其他多通道图像),但为简单起见,这篇博客中仅将过滤器应用于灰度图像。调用 cv2.filter2D将内核应用于灰色图像。cv2.filter2D 函数是opencv自带的,自定义卷积函数的更优化版本
小内核平滑效果图如下:原始图 VS 自己实现的卷积函数效果 VS opencv卷积效果
**大内核平滑如下,随着平均内核大小的增加,输出图像中的模糊量也会增加。
**
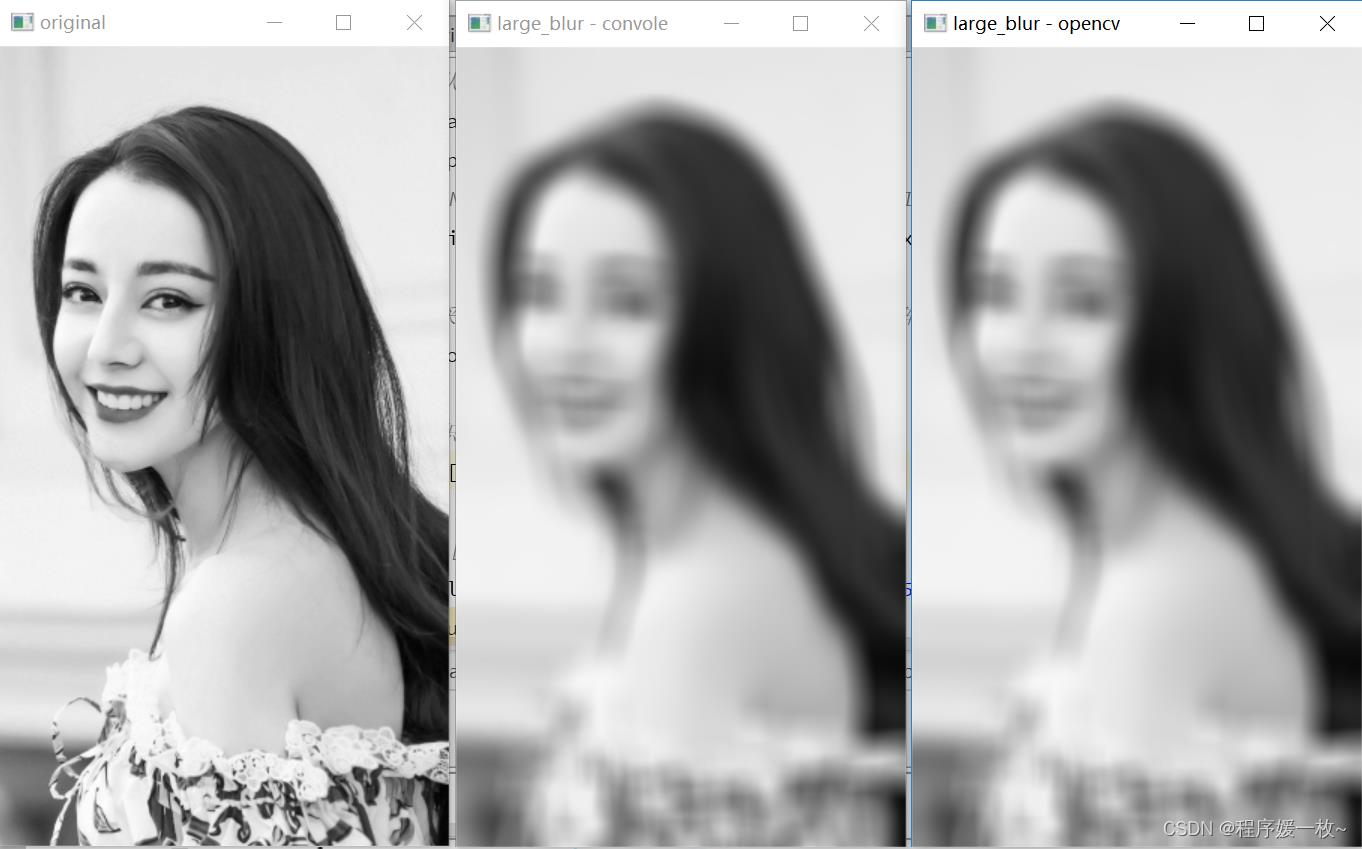
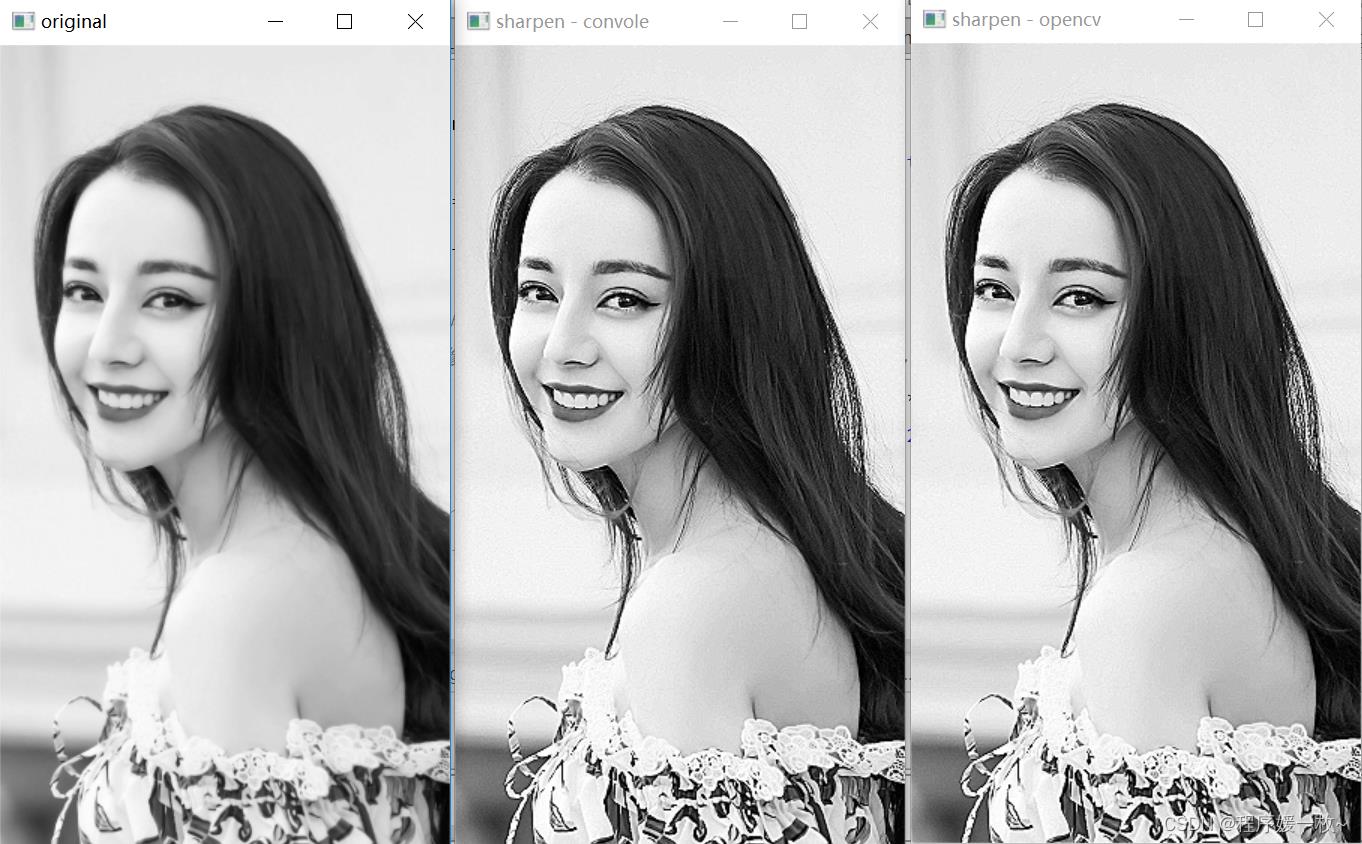
锐化效果如图:
锐化内核强调相邻像素值的差异。这使图像看起来更加生动。
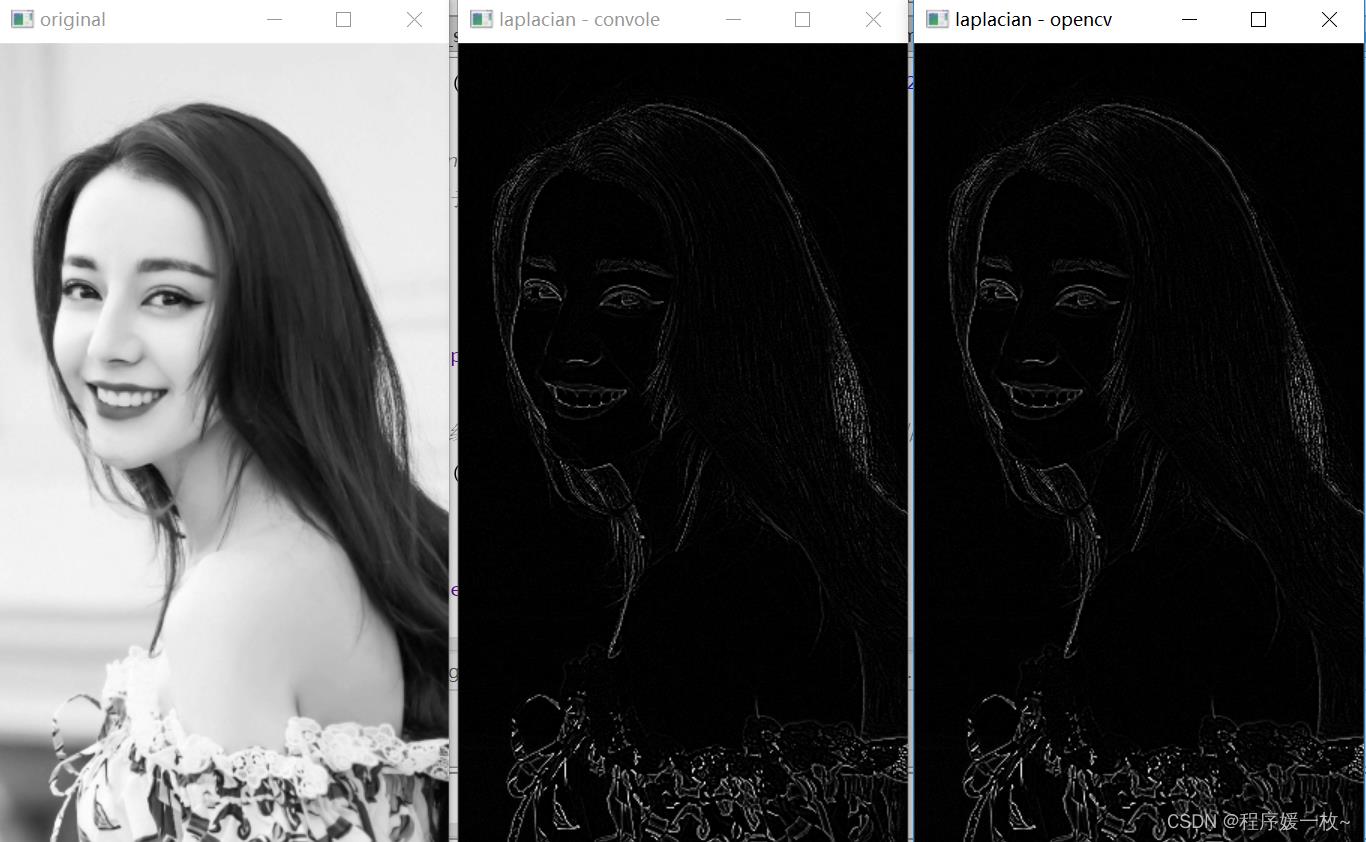
拉普拉斯边缘检测如图,使用拉普拉斯运算符检测边缘
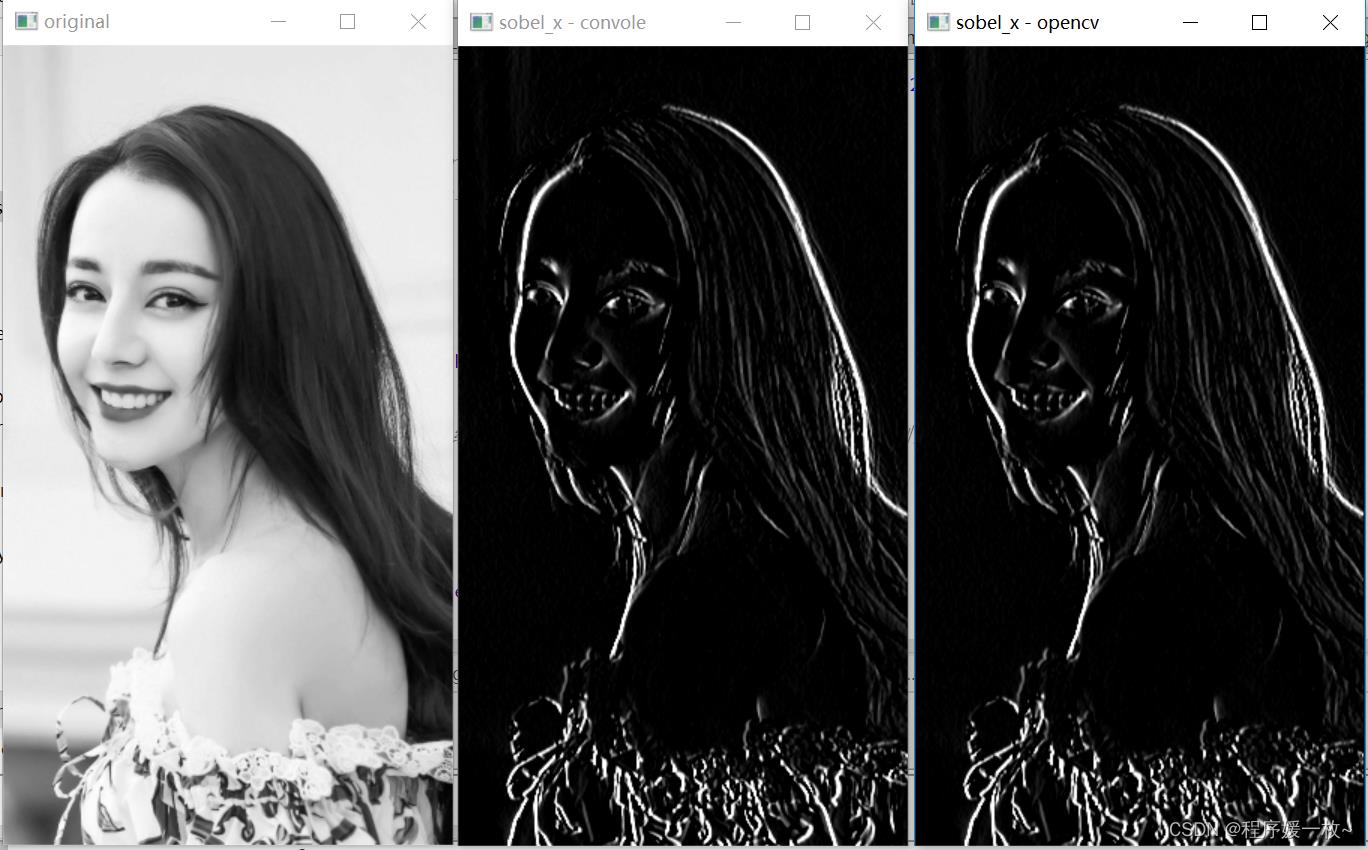
sobel x检测图像垂直方向的梯度如图,使用 Sobel 运算符查找垂直边缘
sobel y检测图像水平方向的梯度如图,使用 Sobel 运算符查找水平边缘

2. 原理
pip install -U scikit-image
深度学习算法能够在计算机视觉任务中获得前所未有的准确性,包括图像分类、对象检测、分割等。
卷积神经网络依赖于称为卷积 Convolution 的计算机视觉/图像处理技术。CNN 会自动学习在训练过程中应用于输入图像的内核 Kernel。
卷积是计算机视觉和图像处理中最关键、最基本的构建块之一。 实际上(图像)卷积只是两个矩阵的逐元素乘法,后跟一个总和。如之前的平滑、模糊,边缘检测都是卷积。
即卷积是:
- 取两个矩阵(它们都具有相同的维度)。
- 逐个元素地将它们相乘(即,不是点积,只是简单的乘法)。
- 将元素相加。
图像是一个多维矩阵。有宽度,高度,深度——图像中的通道数。对于标准的RGB 图像深度为 3 — 红色、绿色和蓝色通道各对应一个通道。可以将图像视为大矩阵,将核或卷积矩阵视为用于模糊(平均平滑、高斯平滑、中值平滑等)、边缘检测(拉普拉斯、Sobel、Scharr、Prewitt 等)和锐化、边缘检测和其他图像处理功能的微小矩阵。所有这些操作都是专门设计用于执行特定功能的手动定义内核的形式。
从本质上讲,这个微小的内核位于大图像的顶部,从左到右和从上到下滑动,在原始图像的每个(x,y)坐标处应用数学运算(即卷积)。卷积只是内核和内核覆盖的输入图像的邻域之间的逐元素矩阵乘法的总和。。
内核可以是 M x N 像素的任意大小,前提是 M 和 N 都是奇数。通常看到的大多数内核是正方形 N x N 矩阵。使用奇数核大小来确保图像中心有一个有效的整数 (x, y) 坐标。
图像内核是一个小矩阵,用于应用在 Photoshop 或 Gimp 中可能找到的效果,例如模糊、锐化、轮廓或压花(blurring, sharpening, outlining or embossing)。还用于机器学习中的“特征提取”,这是一种确定图像最重要部分的技术。在这种情况下,该过程通常被称为“卷积”
3. 卷积神经网络CNN
上边都是自定义卷积内核,有没有可能定义一种机器学习算法来查看图像并最终学习这些类型的运算符?
事实上,这些类型的算法是神经网络的一种子类型,称为卷积神经网络(Convolutional Neural Networks CNNs)。通过应用卷积滤波器、非线性激活函数、池化和反向传播(nonlinear activation functions, pooling, and backpropagation),CNN 能够学习可以检测网络较低层中的边缘和类似斑点结构的过滤器,然后使用边缘和结构作为构建块,最终检测网络更深层中的更高级别的对象(即面部、猫、狗、杯子等)。
4. 源码
# 将卷积应用于图像
# USAGE
# python convolutions --image images/rb.jpeg
# 导入必要的包
import argparse
import cv2
import imutils
import numpy as np
from skimage.exposure import rescale_intensity # 应用 scikit-image 的rescale_intensity函数使得输出图像像素位于[0,255]
# 重要的是要了解在图像上“滑动”卷积矩阵,应用卷积,然后存储输出的过程实际上会减少输出图像的空间维度。
# 落在图像边界上的像素没有“中心”像素,空间维度的减小只是对图像应用卷积的副作用。通常希望输出图像与输入图像具有相同的尺寸。
# 为了确保这一点,应用填充。
def convolve(image, kernel):
# 获取图像的空间维度,及内核的维度
(iH, iW) = image.shape[:2]
(kH, kW) = kernel.shape[:2]
# 为输出图像开辟空间,注意“填充”输入图像的边框,以便空间大小(即宽度和高度)不减小
pad = (kW - 1) // 2
# 存在其他填充方法,包括零填充(用零填充边框或复制)和环绕(其中边界像素通过检查图像的另一端来确定)。
image = cv2.copyMakeBorder(image, pad, pad, pad, pad,
cv2.BORDER_REPLICATE)
output = np.zeros((iH, iW), dtype="float32")
# 遍历输入图像,从上到下从左到右滑动内核
for y in np.arange(pad, iH + pad):
for x in np.arange(pad, iW + pad):
# 使用 NumPy 数组切片从图像中提取感兴趣区域 (ROI)。ROI是(当前坐标区域的中心)
roi = image[y - pad:y + pad + 1, x - pad:x + pad + 1]
# 通过采取在ROI和内核之间逐元素相乘内核,然后对矩阵求和
k = (roi * kernel).sum()
# 将卷积值存储在输出图像中
output[y - pad, x - pad] = k
# 缩放输出图像到 [0, 255]
output = rescale_intensity(output, in_range=(0, 255))
output = (output * 255).astype("uint8")
# 返回输出图像
return output
# 构建命令行参数及解析
# --image 输入图像路径
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=False, default='images/rb.jpeg',
help="path to the input image")
args = vars(ap.parse_args())
# 构建平均模糊内核以平滑图像,
# 定义了用于模糊/平滑图像的 7 x 7 内核和 21 x 21 内核。内核越大,图像就越模糊。
smallBlur = np.ones((7, 7), dtype="float") * (1.0 / (7 * 7))
largeBlur = np.ones((21, 21), dtype="float") * (1.0 / (21 * 21))
# 使用锐化滤镜sharpening filter
# 定义了一个锐化内核,用于增强图像的线条结构和其他细节。
sharpen = np.array((
[0, -1, 0],
[-1, 5, -1],
[0, -1, 0]), dtype="int")
# 定义拉普拉斯内核执行边缘检测Laplacian kernel,拉普拉斯对于检测图像中的模糊也非常有用。
laplacian = np.array((
[0, 1, 0],
[1, -4, 1],
[0, 1, 0]), dtype="int")
# 定义Sobel x-axis kernel,用于检测图像梯度的垂直变化
sobelX = np.array((
[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]), dtype="int")
# 定义Sobel y-axis kernel,用于检测图像梯度的水平变化
sobelY = np.array((
[-1, -2, -1],
[0, 0, 0],
[1, 2, 1]), dtype="int")
# 构建内核库列表
kernelBank = (
("small_blur", smallBlur),
("large_blur", largeBlur),
("sharpen", sharpen),
("laplacian", laplacian),
("sobel_x", sobelX),
("sobel_y", sobelY)
)
# 加载原始图像,转换为灰度图
image = cv2.imread(args["image"])
image = imutils.resize(image, width=300)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 遍历内核并展示结果
for (kernelName, kernel) in kernelBank:
# 卷积运算符当然可以应用于 RGB(或其他多通道图像),但为了简单起见,在此博客文章中仅将过滤器应用于灰度图像
# 调用 cv2.filter2D将内核应用于灰色图像。cv2.filter2D 函数是上边自定义卷积函数的更优化版本
print("[INFO] applying kernel".format(kernelName))
convoleOutput = convolve(gray, kernel)
opencvOutput = cv2.filter2D(gray, -1, kernel)
# 展示输出图像
cv2.imshow("original", gray)
cv2.imshow(" - convole".format(kernelName), convoleOutput)
cv2.imshow(" - opencv".format(kernelName), opencvOutput)
cv2.waitKey(0)
cv2.destroyAllWindows()
参考
- https://pyimagesearch.com/2016/07/25/convolutions-with-opencv-and-python/
- https://setosa.io/ev/image-kernels/
以上是关于深度学习之Python,OpenCV中的卷积的主要内容,如果未能解决你的问题,请参考以下文章