Java十九个技术栈常见面试题分享(附答案解析)
Posted JavaCaiy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java十九个技术栈常见面试题分享(附答案解析)相关的知识,希望对你有一定的参考价值。
Java 基础: 两个对象的 hashCode()相同,则 equals()也一定为 true,对吗?
不对,两个对象的 hashCode()相同,equals()不一定 true。
代码示例:
String str1 = "通话";
String str2 = "重地";
System.out.println(String.format("str1:%d | str2:%d", str1.hashCode(),str2.hashCode())); System.out.println(str1.equals(str2));
执行的结果:
str1:1179395 | str2:1179395
false
**代码解读:**很显然“通话”和“重地”的 hashCode() 相同,然而 equals() 则为 false,因为在散列表中,hashCode()相等即两个键值对的哈希值相等,然而哈希值相等,并不一定能得出键值对相等。
Java容器:Iterator 怎么使用?有什么特点?
Java中的Iterator功能比较简单,并且只能单向移动:
- 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
- 使用next()获得序列中的下一个元素。
- 使用hasNext()检查序列中是否还有元素。
- 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历 List,也可以从List中插入和删除元素。
多线程:线程有哪些状态?
线程通常都有五种状态,创建、就绪、运行、阻塞和死亡。
- 创建状态。在生成线程对象,并没有调用该对象的start方法,这是线程处于创建状态。
- 就绪状态。当调用了线程对象的start方法之后,该线程就进入了就绪状态,但是此时线程调度程序还没有把该线程设置为当前线程,此时处于就绪状态。在线程运行之后,从等待或者睡眠中回来之后,也会处于就绪状态。
- 运行状态。线程调度程序将处于就绪状态的线程设置为当前线程,此时线程就进入了运行状态,开始运行run函数当中的代码。
- 阻塞状态。线程正在运行的时候,被暂停,通常是为了等待某个时间的发生(比如说某项资源就绪)之后再继续运行。sleep,suspend,wait等方法都可以导致线程阻塞。
- 死亡状态。如果一个线程的run方法执行结束或者调用stop方法后,该线程就会死亡。对于已经死亡的线程,无法再使用start方法令其进入就绪
反射:动态代理是什么?有哪些应用?
动态代理:
当想要给实现了某个接口的类中的方法,加一些额外的处理。比如说加日志,加事务等。可以给这个类创建一个代理,故名思议就是创建一个新的类,这个类不仅包含原来类方法的功能,而且还在原来的基础上添加了额外处理的新类。这个代理类并不是定义好的,是动态生成的。具有解耦意义,灵活,扩展性强。
动态代理的应用:
- Spring的AOP
- 加事务
- 加权限
- 加日志
对象拷贝:如何实现对象克隆?
有两种方式:
- 实现Cloneable接口并重写Object类中的clone()方法;
- 实现Serializable接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆,代码如下:
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class MyUtil
private MyUtil()
throw new AssertionError();
@SuppressWarnings("unchecked")
public static <T extends Serializable> T clone(T obj) throws Exception
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bout);
oos.writeObject(obj);
ByteArrayInputStream bin = new ByteArrayInputStream(bout.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bin);
return (T) ois.readObject();
// 说明:调用ByteArrayInputStream或ByteArrayOutputStream对象的close方法没有任何意义
// 这两个基于内存的流只要垃圾回收器清理对象就能够释放资源,这一点不同于对外部资源(如文件流)的释放
下面是测试代码:
import java.io.Serializable;
/**
* 人类
* @author nnngu
*
*/
class Person implements Serializable
private static final long serialVersionUID = -9102017020286042305L;
private String name; // 姓名
private int age; // 年龄
private Car car; // 座驾
public Person(String name, int age, Car car)
this.name = name;
this.age = age;
this.car = car;
public String getName()
return name;
public void setName(String name)
this.name = name;
public int getAge()
return age;
public void setAge(int age)
this.age = age;
public Car getCar()
return car;
public void setCar(Car car)
this.car = car;
@Override
public String toString()
return "Person [name=" + name + ", age=" + age + ", car=" + car + "]";
/**
* 小汽车类
* @author nnngu
*
*/
class Car implements Serializable
private static final long serialVersionUID = -5713945027627603702L;
private String brand; // 品牌
private int maxSpeed; // 最高时速
public Car(String brand, int maxSpeed)
this.brand = brand;
this.maxSpeed = maxSpeed;
public String getBrand()
return brand;
public void setBrand(String brand)
this.brand = brand;
public int getMaxSpeed()
return maxSpeed;
public void setMaxSpeed(int maxSpeed)
this.maxSpeed = maxSpeed;
@Override
public String toString()
return "Car [brand=" + brand + ", maxSpeed=" + maxSpeed + "]";
class CloneTest
public static void main(String[] args)
try
Person p1 = new Person("郭靖", 33, new Car("Benz", 300));
Person p2 = MyUtil.clone(p1); // 深度克隆
p2.getCar().setBrand("BYD");
// 修改克隆的Person对象p2关联的汽车对象的品牌属性
// 原来的Person对象p1关联的汽车不会受到任何影响
// 因为在克隆Person对象时其关联的汽车对象也被克隆了
System.out.println(p1);
catch (Exception e)
e.printStackTrace();
注意:基于序列化和反序列化实现的克隆不仅仅是深度克隆,更重要的是通过泛型限定,可以检查出要
克隆的对象是否支持序列化,这项检查是编译器完成的,不是在运行时抛出异常,这种是方案明显优于
使用Object类的clone方法克隆对象。让问题在编译的时候暴露出来总是好过把问题留到运行时。
Java Web:session 和 cookie 有什么区别?
- 由于HTTP协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是Session.典型的场景比如购物车,当你点击下单按钮时,由于HTTP协议无状态,所以并不知道是哪个用户操作的,所以服务端要为特定的用户创建了特定的Session,用用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。这个Session是保存在服务端的,有一个唯一标识。在服务端保存Session的方法很多,内存、数据库、文件都有。集群的时候也要考虑Session的转移,在大型的网站,一般会有专门的Session服务器集群,用来保存用户会话,这个时候 Session 信息都是放在内存的,使用一些缓存服务比如Memcached之类的来放 Session。
- 思考一下服务端如何识别特定的客户?这个时候Cookie就登场了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie 来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在 Cookie 里面记录一个Session ID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。有人问,如果客户端的浏览器禁用了 Cookie 怎么办?一般这种情况下,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
- Cookie其实还可以用在一些方便用户的场景下,设想你某次登陆过一个网站,下次登录的时候不想再次输入账号了,怎么办?这个信息可以写到Cookie里面,访问网站的时候,网站页面的脚本可以读取这个信息,就自动帮你把用户名给填了,能够方便一下用户。这也是Cookie名称的由来,给用户的一点甜头。所以,总结一下:Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
异常:try-catch-finally 中哪个部分可以省略?
答:catch 可以省略
原因:
更为严格的说法其实是:try只适合处理运行时异常,try+catch适合处理运行时异常+普通异常。也就是说,如果你只用try去处理普通异常却不加以catch处理,编译是通不过的,因为编译器硬性规定,普通异常如果选择捕获,则必须用catch显示声明以便进一步处理。而运行时异常在编译时没有如此规定,所以catch可以省略,你加上catch编译器也觉得无可厚非。
理论上,编译器看任何代码都不顺眼,都觉得可能有潜在的问题,所以你即使对所有代码加上try,代码在运行期时也只不过是在正常运行的基础上加一层皮。但是你一旦对一段代码加上try,就等于显示地承诺编译器,对这段代码可能抛出的异常进行捕获而非向上抛出处理。如果是普通异常,编译器要求必须用catch捕获以便进一步处理;如果运行时异常,捕获然后丢弃并且+finally扫尾处理,或者加上catch捕获以便进一步处理。
至于加上finally,则是在不管有没捕获异常,都要进行的“扫尾”处理。
网络:forward 和 redirect 的区别?
Forward和Redirect代表了两种请求转发方式:直接转发和间接转发。
直接转发方式(Forward),客户端和浏览器只发出一次请求,Servlet、html、JSP或其它信息资源,由第二个信息资源响应该请求,在请求对象request中,保存的对象对于每个信息资源是共享的。
**间接转发方式(Redirect)**实际是两次HTTP请求,服务器端在响应第一次请求的时候,让浏览器再向另外一个URL发出请求,从而达到转发的目的。
举个通俗的例子:
直接转发就相当于:“A找B借钱,B说没有,B去找C借,借到借不到都会把消息传递给A”;
间接转发就相当于:“A找B借钱,B说没有,让A去找C借”。
设计模式:简单工厂和抽象工厂有什么区别?
简单工厂模式:
这个模式本身很简单而且使用在业务较简单的情况下。一般用于小项目或者具体产品很少扩展的情况(这样工厂类才不用经常更改)。
它由三种角色组成:
- 工厂类角色:这是本模式的核心,含有一定的商业逻辑和判断逻辑,根据逻辑不同,产生具体的工厂产品。如例子中的Driver类。
- 抽象产品角色:它一般是具体产品继承的父类或者实现的接口。由接口或者抽象类来实现。如例中的Car接口。
- 具体产品角色:工厂类所创建的对象就是此角色的实例。在java中由一个具体类实现,如例子中的Benz、Bmw类。
来用类图来清晰的表示下的它们之间的关系:

抽象工厂模式:
先来认识下什么是产品族: 位于不同产品等级结构中,功能相关联的产品组成的家族。

图中的BmwCar和BenzCar就是两个产品树(产品层次结构);而如图所示的BenzSportsCar和BmwSportsCar就是一个产品族。他们都可以放到跑车家族中,因此功能有所关联。同理BmwBussinessCar和BenzBusinessCar也是一个产品族。
可以这么说,它和工厂方法模式的区别就在于需要创建对象的复杂程度上。而且抽象工厂模式是三个里面最为抽象、最具一般性的。抽象工厂模式的用意为:给客户端提供一个接口,可以创建多个产品族中的产品对象。
而且使用抽象工厂模式还要满足一下条件:
- 系统中有多个产品族,而系统一次只可能消费其中一族产品
- 同属于同一个产品族的产品以其使用。
来看看抽象工厂模式的各个角色(和工厂方法的如出一辙):
- 抽象工厂角色: 这是工厂方法模式的核心,它与应用程序无关。是具体工厂角色必须实现的接口或者必须继承的父类。在java中它由抽象类或者接口来实现。
- 具体工厂角色:它含有和具体业务逻辑有关的代码。由应用程序调用以创建对应的具体产品的对象。在java中它由具体的类来实现。
- 抽象产品角色:它是具体产品继承的父类或者是实现的接口。在java中一般有抽象类或者接口来实现。
- 具体产品角色:具体工厂角色所创建的对象就是此角色的实例。在java中由具体的类来实现。
Spring / Spring MVC:解释一下什么是 ioc?
IOC是Inversion of Control的缩写,多数书籍翻译成“控制反转”。
1996年,Michael Mattson在一篇有关探讨面向对象框架的文章中,首先提出了IOC 这个概念。对于面向对象设计及编程的基本思想,前面我们已经讲了很多了,不再赘述,简单来说就是把复杂系统分解成相互合作的对象,这些对象类通过封装以后,内部实现对外部是透明的,从而降低了解决问题的复杂度,而且可以灵活地被重用和扩展。
IOC理论提出的观点大体是这样的:借助于“第三方”实现具有依赖关系的对象之间的解耦。如下图:
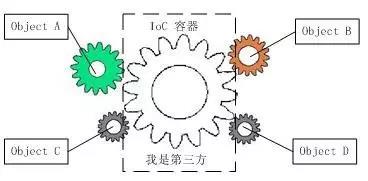
大家看到了吧,由于引进了中间位置的“第三方”,也就是IOC容器,使得A、B、C、D这4个对象没有了耦合关系,齿轮之间的传动全部依靠“第三方”了,全部对象的控制权全部上缴给“第三方”IOC容器,所以, IOC容器成了整个系统的关键核心,它起到了一种类似“粘合剂”的作用,把系统中的所有对象粘合在一起发挥作用,如果没有这个“粘合剂”,对象与对象之间会彼此失去联系,这就是有人把IOC容器比喻成“粘合剂”的由来。
我们再来做个试验:把上图中间的IOC容器拿掉,然后再来看看这套系统:

我们现在看到的画面,就是我们要实现整个系统所需要完成的全部内容。这时候,A、B、C、D这4个对象之间已经没有了耦合关系,彼此毫无联系,这样的话,当你在实现A的时候,根本无须再去考虑B、C和D了,对象之间的依赖关系已经降低到了最低程度。所以,如果真能实现IOC容器,对于系统开发而言,这将是一件多么美好的事情,参与开发的每一成员只要实现自己的类就可以了,跟别人没有任何关系!
我们再来看看,控制反转(IOC)到底为什么要起这么个名字?我们来对比一下:
软件系统在没有引入IOC容器之前,如图1所示,对象A依赖于对象B,那么对象A在初始化或者运行到某一点的时候,自己必须主动去创建对象B或者使用已经创建的对象B。无论是创建还是使用对象B,控制权都在自己手上。
软件系统在引入IOC容器之后,这种情形就完全改变了,如图3所示,由于IOC容器的加入,对象A与对象B之间失去了直接联系,所以,当对象A运行到需要对象B的时候,IOC容器会主动创建一个对象B注入到对象A需要的地方。
通过前后的对比,我们不难看出来:对象A获得依赖对象B的过程,由主动行为变为了被动行为,控制权颠倒过来了,这就是“控制反转”这个名称的由来。
Spring Boot / Spring Cloud:jpa 和 hibernate 有什么区别?
- JPA Java Persistence API,是Java EE 5的标准ORM接口,也是ejb3规范的一部分。
- Hibernate,当今很流行的ORM框架,是JPA的一个实现,但是其功能是JPA的超集。
- JPA和Hibernate之间的关系,可以简单的理解为JPA是标准接口,Hibernate是实现。那么Hibernate是如何实现与JPA的这种关系的呢。Hibernate主要是通过三个组件来实现的,及hibernate-annotation、hibernate-entitymanager和hibernate-core。
- hibernate-annotation是Hibernate支持annotation方式配置的基础,它包括了标准的JPA annotation以及Hibernate自身特殊功能的annotation。
- hibernate-core是Hibernate的核心实现,提供了Hibernate所有的核心功能。
- hibernate-entitymanager实现了标准的JPA,可以把它看成hibernate-core和JPA之间的适配器,它并不直接提供ORM的功能,而是对hibernate-core进行封装,使得Hibernate符合JPA的规范。
Hibernate:什么是 ORM 框架?
对象-关系映射(Object-Relational Mapping,简称ORM),面向对象的开发方法是当今企业级应用开发环境中的主流开发方法,关系数据库是企业级应用环境中永久存放数据的主流数据存储系统。对象和关系数据是业务实体的两种表现形式,业务实体在内存中表现为对象,在数据库中表现为关系数据。内存中的对象之间存在关联和继承关系,而在数据库中,关系数据无法直接表达多对多关联和继承关系。因此,对象-关系映射(ORM)系统一般以中间件的形式存在,主要实现程序对象到关系数据库数据的映射。
Mybatis:说一下 mybatis 的一级缓存和二级缓存?
一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存。
二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置 ;
对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear。
RabbitMQ:rabbitmq 有哪些重要的组件?
- ConnectionFactory(连接管理器):应用程序与Rabbit之间建立连接的管理器,程序代码中使用。
- Channel(信道):消息推送使用的通道。
- Exchange(交换器):用于接受、分配消息。
- Queue(队列):用于存储生产者的消息。
- RoutingKey(路由键):用于把生成者的数据分配到交换器上。
- BindingKey(绑定键):用于把交换器的消息绑定到队列上。
Kafka:使用 kafka 集群需要注意什么?
- 集群的数量不是越多越好,最好不要超过 7 个,因为节点越多,消息复制需要的时间就越长,整个群组的吞吐量就越低。
- 集群数量最好是单数,因为超过一半故障集群就不能用了,设置为单数容错率更高。
Zookeeper:zookeeper 都有哪些功能?
- 集群管理:监控节点存活状态、运行请求等。
- 主节点选举:主节点挂掉了之后可以从备用的节点开始新一轮选主,主节点选举说的就是这个选举的过程,使用 zookeeper 可以协助完成这个过程。
- 分布式锁:zookeeper 提供两种锁:独占锁、共享锁。独占锁即一次只能有一个线程使用资源,共享锁是读锁共享,读写互斥,即可以有多线线程同时读同一个资源,如果要使用写锁也只能有一个线程使用。zookeeper可以对分布式锁进行控制。
- 命名服务:在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。
mysql:char 和 varchar 的区别是什么?
char(n) :固定长度类型,比如订阅 char(10),当你输入"abc"三个字符的时候,它们占的空间还是 10个字节,其他 7 个是空字节。
chat 优点:效率高;缺点:占用空间;适用场景:存储密码的 md5 值,固定长度的,使用 char 非常合适。
varchar(n) :可变长度,存储的值是每个值占用的字节再加上一个用来记录其长度的字节的长度。
所以,从空间上考虑 varcahr 比较合适;从效率上考虑 char 比较合适,二者使用需要权衡。
Redis:redis 淘汰策略有哪些?
- volatile-lru:从已设置过期时间的数据集(server. db[i]. expires)中挑选最近最少使用的数据淘汰。
- volatile-ttl:从已设置过期时间的数据集(server. db[i]. expires)中挑选将要过期的数据淘汰。
- volatile-random:从已设置过期时间的数据集(server. db[i]. expires)中任意选择数据淘汰。
- allkeys-lru:从数据集(server. db[i]. dict)中挑选最近最少使用的数据淘汰。
- allkeys-random:从数据集(server. db[i]. dict)中任意选择数据淘汰。
- no-enviction(驱逐):禁止驱逐数据。
JVM:说一下 jvm 运行时数据区?
- 程序计数器
- 虚拟机栈
- 本地方法栈
- 堆
- 方法区
有的区域随着虚拟机进程的启动而存在,有的区域则依赖用户进程的启动和结束而创建和销毁。

内容节选
以上是关于Java十九个技术栈常见面试题分享(附答案解析)的主要内容,如果未能解决你的问题,请参考以下文章