capsules系列Investigating Capsule Networks with Dynamic Routing for Text Classification
Posted AI蜗牛之家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了capsules系列Investigating Capsule Networks with Dynamic Routing for Text Classification相关的知识,希望对你有一定的参考价值。
文章目录
1.背景介绍
早期对文本建模的成果,已经在文本分类方面取得了一些成功,使用简单的词袋子分类器(Joachims,1998;McCallum等,1998),意味着理解独立单词或N-gram词组的含义是研究复杂模型的必要步骤。因此,这也不奇怪出现了分布式的词语表示法,也就是词嵌入/词向量,已经得到NLP社区的高度关注,解决了在基本层面上应该对什么(词义)建模的疑问(Mikolov等,2013;Pennington等,2014).。为了对文本中的更高层次的概念和事实建模,NLP研究人员必须思考这个问题:除了词义实际上还需要对什么建模。这个问题的一个常见方法是将文本视为序列并关注其空间模式,其代表包括卷积神经网络(CNN)(Kim,2014;Zhang等,2015;Conneau等,2017)和长短记忆网络(LSTM)(Taietal,2015;Mousa与Schuller,2017)另一种常见的方法是完全忽略单词的顺序,而将这些单词作为一个集合,其代表包括概率主题模型(Blei等,2003;Mcauliffe与Blei,2008)和Earth Mover的基于距离的建模(Kusner等,2015; Ye等,2017)。
作为一种空间敏感模型,CNN为网格上复制特征探测器的低效性付出了代价。正如在(Sabour等,2017)中所论述的,人们必须在大小随维数增加指数增长的复制检测器和以类似指数方式增加标记训练集的体积之间进行选择。另一方面,空间不敏感的方法在判断的场景中是完全有效的,而不管任何单词或局部模式的顺序如何。
传统的分类问题一般采用CNN或者RNN,并采取hierarchical的方式提取特征,但是这两种基础的结构都存在各自的问题:
- CNN在运用feature detectors提取特征后往往会通过max-pooling的方式选择prominent feature,这种方式用Hinton的话来说带来的后果是disastrous的。另外CNN的特征抽取和泛化能力也存在一定问题,可以详细参考之前的文章:capsule系列之Dynamic Routing Between Capsules
- RNN由于是一个序列模型,而我的实验和经验觉得分类问题本身对时序语义没有那么强烈,再加上RNN本身训练时间较为漫长。
2.模型特色
继capsule在图像处理上的应用,capsule首次运用在了nlp领域,也显示出了其在分类问题(我觉得更准确来说是在特征提取)上的良好结果。
本文模型特点:
- 采用传统模型思想(cnn中low level用feature detectors的方式提取特征并max-pooling,并逐层提取特征),通过两层capsules的结构,第一层提取local feature,第二层提取fully feature;
- 修改routing策略:
- 引入Orphan Category的理念,具体是:增加一个最终分类的种类,这个向量可以捕捉到“back-ground”信息(这种信息具体在文本中是停用词或者一些其他的无用词)
- 在capsule中,预测向量的权重
C
i
j
C_ij
Cij的计算时,使用了Leaky-Softmax替换softmax,在不增加计算量的同时,来处理
l
l
l和
l
+
1
l+1
l+1层的noise child capsules的问题,具体可思路如下(代替softmax):
leak = tf.zeros_like(b, optimize=True) leak = tf.reduce_sum(leak, axis=1, keep_dims=True) leaky_logits = tf.concat([leak, b], axis=1) leaky_routing = tf.nn.softmax(leaky_logits, dim=1) c = tf.split(leaky_routing, [1, output_capsule_num], axis=1)[1] - 在leaky-softmax 的基础上添加Coefficients Amendment参数修正,具体操作如下图,(这部分没在源码里面找到,原因也不是很清楚,望大佬告知)

3.模型详述
3.1.基本结构
基本的模型过程是这样的:
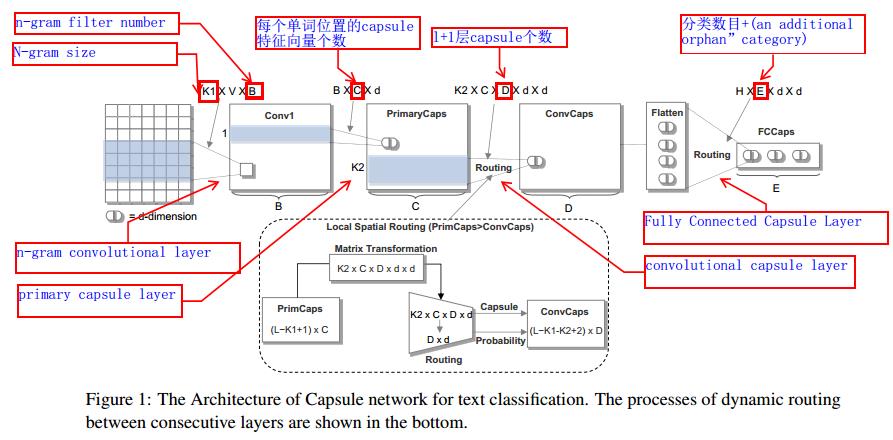
在撸源码时自己手画了一个,根据源码来的:

2019.9.3更新:
其实这两层的rooting过程分别获得的是每个词级别的语义向量和整个passage的向量表示
- 第一层的输入是[ b a t c h batch batch, l e n len len, c a p _ i n cap\\_in cap_in, p o s e pose pose],也就是输入每个位置用 c a p _ i n cap\\_in cap_in个长度为 p o s e pose pose的向量表示 w o r d i word_i wordi,并在此基础上每个位置用相邻的三个词来表示当前位置向量,也就是进一步的,每个位置用3* c a p _ i n cap\\_in cap_in个长度为 p o s e pose pose的向量表示,从而输入是[ b a t c h batch batch, l e n len len,3* c a p _ i n cap\\_in cap_in, p o s e pose pose],输出是一个[ b a t c h batch batch* l e n len len, c a p _ o u t cap\\_out cap_out, p o s e pose pose]也就是每个位置都用cap_out个长度为pose的向量表示 w o r d i word_i wordi,
- 接下来再transpose成[ b a t c h batch batch, l e n len len* c a p _ o u t cap\\_out cap_out, p o s e pose pose]作为输入进行整个篇章的rooting,从而获得篇章级的表示,也就是得到最终分类结果
3.2.模型结构
上面作为一个细节思路,文章同时给出了两种模型结构:

源码:zsweet/capsule_text_classification
其他实现源码以及其他任务源码:
AidenHuen/Capsule-Text-Classification
JerrikEph/Capsule4TextClassification
3.3.损失函数
使用的依旧是margin-loss,详情如下图:

源码中其他几个可选的loss:
def spread_loss(labels, activations, margin):
activations_shape = activations.get_shape().as_list()
mask_t = tf.equal(labels, 1)
mask_i = tf.equal(labels, 0)
activations_t = tf.reshape(
tf.boolean_mask(activations, mask_t), [activations_shape[0], 1]
)
activations_i = tf.reshape(
tf.boolean_mask(activations, mask_i), [activations_shape[0], activations_shape[1] - 1]
)
gap_mit = tf.reduce_sum(tf.square(tf.nn.relu(margin - (activations_t - activations_i))))
return gap_mit
def cross_entropy(y, preds):
y = tf.argmax(y, axis=1)
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=preds, labels=y)
loss = tf.reduce_mean(loss)
return loss
def margin_loss(y, preds):
y = tf.cast(y,tf.float32)
loss = y * tf.square(tf.maximum(0., 0.9 - preds)) + \\
0.25 * (1.0 - y) * tf.square(tf.maximum(0., preds - 0.1))
loss = tf.reduce_mean(tf.reduce_sum(loss, axis=1))
# loss = tf.reduce_mean(loss)
return loss
4.小结
模型整体上做了一些创新,也在routing的时候增加了一些trick,但是在Capsule-B中时,最后使用了max-pooling,这和capsule的初衷是相违背的,但是其特征抽取能力是不错的,所以关于capsule在nlp相关的任务上如何使用我觉得是现在一个很好的研究点。
更新(2019.5.13):一篇很不错的文章:基于动态路由的胶囊网络在文本分类上的探索
5.新趋势
ICLR2020-Capsules with Inverted Dot-Product Attention Routing-Yao-Hung Tsai
参考
本文只列出了自己的部分观点和认识,原文有更多的相关细节描述
- Investigating Capsule Networks with Dynamic Routing for Text Classification.pdf
- 基于动态路由的胶囊网络在文本分类上的探索
- 基于Capsule Networks的文本分类
以上是关于capsules系列Investigating Capsule Networks with Dynamic Routing for Text Classification的主要内容,如果未能解决你的问题,请参考以下文章