Storm Trident API总结-1
Posted 真诚的程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Storm Trident API总结-1相关的知识,希望对你有一定的参考价值。
-
Trident API目前的现状
Storm原语基本的API其实都很好理解,即使是之前介绍的Transactional相关的API也还好理解,最难理解的API是Trident的。Trident API的困难有如下几个方面的原因:
- Trident本身是一种更高层的抽象,它完全封装了Bolt以及Topology,你很难利用之前Storm API来理解。
- Trident中的概念在官方文档中解释得不是很充分,例如partition的概念
- Trident,以及Storm的JavaDoc文档很多都只有简单的接口定义,没有接口描述以及解释。
- 现在出版的一些书籍对API的介绍也不是很深入,例如Stream的parallellismHint方法。
-
partition的概念介绍
partition中文意思是分区,有人将partition理解为Storm里面的task,即并发的基本执行单位。我理解应该是像数据库里面的分区,是将一个batch的数据分区,分成多个partition,或者可以理解为多个子batch,然后多个partition可以并发处理。这里关键的区别是:partition是数据,不是执行的代码。你把数据(tuple)分区以后,如果你没有多个task(并发度)来处理这些分区后的数据,那分区也是没有作用的。
所以这里的关系是这样的:先有batch,因为Trident内部是基于batch来实现的;然后有partition;分区后再分配并发度,然后才能进行并发处理。并发度的分配是利用parallelismHint来实现的。这个后面还会讲到。
-
repartition操作
既然有partition的概念,那么也就有partition的操作。Trident提供的分区操作,类似于Storm里面讲的grouping。分区操作有:shuffle(),broadcast(),global(),patitionBy(),batchGlobal(),自己实现CustomStreamGrouping接口。注意,除了这里明确提出来的分区操作,Trident里面还有aggregate()函数隐含有分区的操作,它用的是global()操作,这个在后面接收聚合操作的时候还会再介绍。
-
function,filter,projection
这几个概念都比较简单,只要记住,这些操作都是针对单个tuple的就可以了。
-
aggregation的介绍
聚合操作是Trident中比较容易混乱的一个内容。
首先聚合操作分两种:partitionAggregate(),以及aggregate()。
partitionAggregate()的操作是在partition上,一个batch被分成多个partition后,每个partition都会单独运行partitionAggregate中指定的聚合操作。
aggregate()隐含了一个global分区操作,也就是它做的是全局聚合操作。它针对的是整个batch的聚合计算。
这两种聚合操作,都可以传入不同的aggregator实现具体的聚合任务,注意:这里用的是“tor",是名词。Trident中有三种aggregator接口,分别为:ReducerAggregator,CombinerAggregator,Aggregator。
最重要的区别是CombinerAggregator,它是先在partition上做partial aggregate,然后再将这些部分聚合结果通过global分区到一个总的分区,在这个总的分区上对结果进行汇总。
-
groupBy()分组操作
分组又是Trident中的一个坑。
官方文档中关于groupBy的介绍是:
The groupBy operation repartitions the stream by doing a partitionBy on the specified fields, and then within each partition groups tuples together whose group fields are equal.
翻译为:groupBy通过partitionBy来分区,然后对于每个分区,将值相等的tuple分成一个组。
而《Learning Storm》上说:
The groupBy operation doesn't involve any repartitioning. The groupBy operation
converts the input stream into a grouped stream. The main function of the groupBy
operation is to modify the behavior of the subsequent aggregate function.
翻译为:groupBy不包含任何分区操作。它只是将输入的流转换为一个grouped流,它的主要作用是修改在它之后的aggregation操作的行为。
A practical Storm’s Trident API Overview这篇文章也是和《Learning Storm》上的观点一致:
Keep in mind, however, that groupBy() is not a repartitioning operation per se. groupBy() followed by aggregation() is, but groupBy() followed by partitionAggregation() is not.
翻译为:groupBy本身不是分区操作,如果它后面跟着aggregate()就是,如果后面跟着的是partitionAggregate()就不是。
到底哪个对?笔者经过实验总结:应该是Learning Storm的说法对。而且groupBy应该这样来理解:首先它包含两个操作,一个是分区操作,一个是分组操作。
如果后面是partitionAggregate()的话,就只有分组操作:在每个partition上分组,分完组后,在每个分组上进行聚合;
如果后面是aggregate()的话,先根据partitionBy分区,在每个partition上分组,,分完组后,在每个分组上进行聚合。
-
parallelismHint并发度的介绍
parallelismHint又是一个很难理解的坑,参考A practical Storm’s Trident API Overview这篇文章的解释为:
we can clarify the previous definition of parallelismHint(): it applies a certain degree of parallelism to all operations before it until there’s a repartitioning of some sort.
也就是说:它设置它前面所有操作的并发度,直到遇到某个repartition操作为止。
例如它给了一个例子:
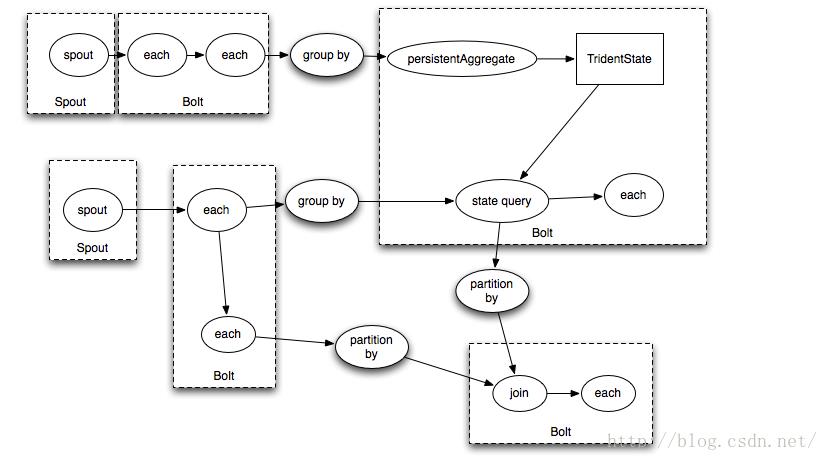
topology.newStream("spout", spout) .each(new Fields("actor", "text"), new PerActorTweetsFilter("dave")) .parallelismHint(5) .each(new Fields("actor", "text"), new Utils.PrintFilter());意味着:parallelismHit之前的spout,each都是5个相同的操作一起并发,对,一共有5个spout同时发射数据,其实parallelismHint后面的each操作,也是5个并发。其实这样说还不是很清楚,要把这个Trident转换成Storm的Spout和Bolt就清楚了,因为我们说的并发,最后一定是转换成Bolt的运行单位Task来实现的。如何转换?可以参考官方文档中的下面的图,根据这个图,我们可以知道,分区操作是作为Bolt划分的分界点的。我们可以想象上面的代码应该转换成了一个Spout连接一个Bolt,设置并发度后,一共有5个Spout Task和5个Bolt Task在并发运行。
如果想单独设置Spout怎么办?要在Spout之后,Bolt之前增加一个ParallelismHint,并且还要增加一个分区操作:
topology.newStream("spout", spout) .parallelismHint(2) .shuffle() .each(new Fields("actor", "text"), new PerActorTweetsFilter("dave")) .parallelismHint(5) .each(new Fields("actor", "text"), new Utils.PrintFilter());
很多人只是设置了Spout的并发度,而没有调用分区操作,这样是达不到效果的,因为Trident是不会自动进行分区操作的。像我之前介绍的,先分区,再设置并发度。如果Spout不设置并发度,只设置shuffle,默认是1个并发度,这样后面设置5个并发度不会影响到Spout,因为并发度的影响到shuffle分区操作就停止了。
-
把之前所有东西都加在一起
- groupBy+aggregate+parallelismHint
public static StormTopology buildTopology(LocalDRPC drpc) throws IOException FakeTweetsBatchSpout spout = new FakeTweetsBatchSpout(5); TridentTopology topology = new TridentTopology(); topology.newStream("spout", spout) .shuffle() .groupBy(new Fields("location")) .aggregate(new Fields("location"), new Count(), new Fields("count")) .parallelismHint(5) .each(new Fields("location","count"), new Utils.PrintFilter()); return topology.build();输出是这样的:
[UK, 1],partitionIndex = 1, num = 5
[USA, 2],partitionIndex = 4, num = 5
[Spain, 1],partitionIndex = 3, num = 5
[France, 1],partitionIndex = 2, num = 5
[France, 2],partitionIndex = 2, num = 5
[USA, 2],partitionIndex = 4, num = 5
[UK, 1],partitionIndex = 1, num = 5
[UK, 1],partitionIndex = 1, num = 5
[France, 2],partitionIndex = 2, num = 5
[USA, 2],partitionIndex = 4, num = 5
说明:上面输出相同颜色的表示同一个Batch的聚合。
把代码改成这样:
- groupBy+partitionAggregate+parallelismHint
public static StormTopology buildTopology(LocalDRPC drpc) throws IOException FakeTweetsBatchSpout spout = new FakeTweetsBatchSpout(5); TridentTopology topology = new TridentTopology(); topology.newStream("spout", spout) .shuffle() .groupBy(new Fields("location")) .partitionAggregate(new Fields("location"), new MyCount(), new Fields("count")) .toStream() .parallelismHint(5) .each(new Fields("count"), new Utils.PrintFilter()); return topology.build();
输出是这样的:
batchid = 1:0
batchid = 1:0
batchid = 1:0
batchid = 1:0
batchid = 1:0
[1],partitionIndex = 0, num = 5
[1],partitionIndex = 2, num = 5
[1],partitionIndex = 4, num = 5
[1],partitionIndex = 1, num = 5
[1],partitionIndex = 3, num = 5
batchid = 2:0
[1],partitionIndex = 2, num = 5
batchid = 2:0
[1],partitionIndex = 4, num = 5
batchid = 2:0
[1],partitionIndex = 0, num = 5
batchid = 2:0
[1],partitionIndex = 1, num = 5
batchid = 2:0
[1],partitionIndex = 3, num = 5
说明:上面输出相同颜色的表示同一个Batch的聚合。batchid是输出来确定batch的。由于shuffle已经把tuple平均分配 给5个partition了,用groupBy+partitionAggregate来聚合又没有partitionBy分区的作用,所以,直接在5个分区上进行聚合,结果就是每个分区各有一个tuple。而用groupBy+aggregate,虽然也是shuffle,但是由于具有partitiononBy分区的作用,值相同的tuple都分配到同一个分区,结果就是每个分区根据不同的值来做汇聚。
- aggregate+parallelismHint(没有groupBy)
public static StormTopology buildTopology(LocalDRPC drpc) throws IOException FakeTweetsBatchSpout spout = new FakeTweetsBatchSpout(5); TridentTopology topology = new TridentTopology(); topology.newStream("spout", spout) .shuffle() .aggregate(new Fields("location"), new Count(), new Fields("count")) .parallelismHint(5) .each(new Fields("count"), new Utils.PrintFilter()); return topology.build();
输出为:
[5],partitionIndex = 1, num = 5
[5],partitionIndex = 2, num = 5
[5],partitionIndex = 3, num = 5
[5],partitionIndex = 4, num = 5
[5],partitionIndex = 0, num = 5
[5],partitionIndex = 1, num = 5我们可以看到,aggregate做的是全局聚合,也就是做了一次global()分区操作,对于不同的batch,选择的分区都是不同的(我们设置了5个并发度,那么就有5个分区)。
- partitionAggregate+parallelismHint(没有groupBy操作)
输出为:public static StormTopology buildTopology(LocalDRPC drpc) throws IOException FakeTweetsBatchSpout spout = new FakeTweetsBatchSpout(5); TridentTopology topology = new TridentTopology(); topology.newStream("spout", spout) .shuffle() .partitionAggregate(new Fields("location"), new MyCount(), new Fields("count")) .toStream() .parallelismHint(5) .each(new Fields("count"), new Utils.PrintFilter()); return topology.build();batchid = 1:0
batchid = 1:0
batchid = 1:0
batchid = 1:0
[1],partitionIndex = 3, num = 5
[1],partitionIndex = 4, num = 5
batchid = 1:0
[1],partitionIndex = 0, num = 5
[1],partitionIndex = 2, num = 5
[1],partitionIndex = 1, num = 5
batchid = 2:0
batchid = 2:0
[1],partitionIndex = 0, num = 5
[1],partitionIndex = 1, num = 5
batchid = 2:0
[1],partitionIndex = 3, num = 5
batchid = 2:0
[1],partitionIndex = 4, num = 5
batchid = 2:0
[1],partitionIndex = 2, num = 5
我们可以发现,partitionAggregate加上groupBy,或者不加上groupBy,对结果都一样:groupBy对于partitionAggregate没有影响。但是对于aggregate来说,加上groupBy,就不是做全局聚合了,而是对分组做聚合;不加上groupBy,就是做全局聚合。
-
参考的文章
以上是关于Storm Trident API总结-1的主要内容,如果未能解决你的问题,请参考以下文章