python 朴素贝叶斯
Posted 阳光玻璃杯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 朴素贝叶斯相关的知识,希望对你有一定的参考价值。
这里的代码应该是学习《统计学习方法》的实验练习吧。代码实现的是《统计学习方法》中第四章朴素贝叶斯法的一个实例,实例如下:
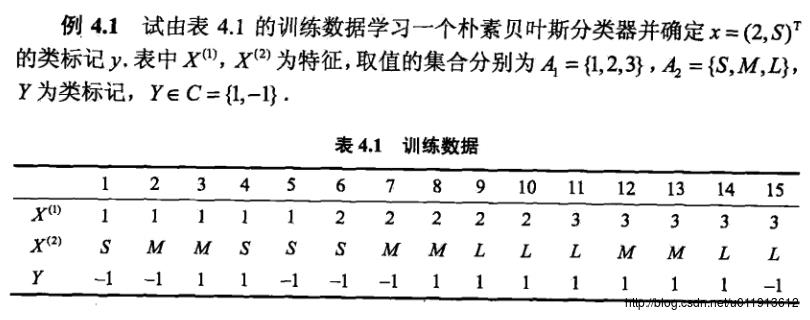 、
、
实现的步骤也是按照书中的步骤,如有问题,谢谢指正。

import numpy as np
import pickle
import os
def creatDataAndLebels():
Xa = [1,1,1,1,1, 2,2,2,2,2, 3,3,3,3,3]
Xb = ['S','M','M','S','S', 'S','M','M','L','L' ,'L','M','M','L','L']
X = [Xa,Xb]
Y = [-1,-1,1,1,-1, -1,-1,1,1,1, 1,1,1,1,-1]
return X,Y
def countFeatureCount(Xi,Y,x,y):
count = 0
for i in range(len(Xi)):
if(Xi[i]==x and Y[i] == y):
count += 1
return count
def trainNB(X,Y):
sizeY = len(Y)
#计算Y中的类别,这里只有-1,和1,但是我们假装不知道,然后去统计Y中所有制
YClass = set(Y)
print(YClass)#1, -1
#然后我们要计算每一种类别的数目。在这里也就是-1的个数和1的个数。
PY =
PYClass =
for y in YClass:
i=0
for yy in Y:
if y == yy:
i += 1
PY.setdefault(str(y),i/sizeY)
PYClass.setdefault(str(y),i) #这个方便后面计算条件概率
print(PY)#1: 0.6, -1: 0.4
print(PYClass)#1: 9, -1: 6
#到这里,计算出了P(Y=ci)
#接下来计算条件概率
conditionP =
for Xi in X:
XiClass = set(Xi)
for x in XiClass:
for y in YClass:
count = countFeatureCount(Xi,Y,x,y)
conditionP.setdefault(str(x)+str(y),count/PYClass[str(y)])
print(conditionP)
# '2-1': 0.3333333333333333, 'L1': 0.4444444444444444, 'L-1': 0.16666666666666666, '3-1': 0.16666666666666666, '31':0.4444444444444444,
# 'M-1': 0.3333333333333333, 'S1': 0.1111111111111111, '11': 0.2222222222222222, '1-1': 0.5, 'M1': 0.4444444444444444, 'S-1': 0.5, '21': 0.3333333333333333
#统计数所有特征的数目后,计算对应的概率
#计算出条件概率后,学习结束,然后就可以预测了
parameter = [PY,conditionP]
fd = open("test.txt",'wb')
pickle.dump(parameter,fd)
fd.close()
def predictNB(parameter,inputdata):
#print(parameter)
PY = parameter[0]
conditionP = parameter[1]
result =
for y in PY:
mul = PY[y]
for x in inputdata:
mul = mul * conditionP[str(x)+str(y)]
result.setdefault(str(y),mul)
best = 'bestLabel':'1','bestValue':0
for y in result:
if result[y] > best['bestValue']:
best['bestLabel'] = y
best['bestValue'] = result[y]
#print(best)
return best
def testTrain():
X,Y = creatDataAndLebels()
trainNB(X,Y)
return None
def testPredict():
fd = open("test.txt",'rb')
parameter = pickle.load(fd)
fd.close()
a=[2,'M']
#print(parameter[0])
result = predictNB(parameter,a)
return result['bestLabel']
result = testPredict()
print(result)
实验是这样的,必须首先执行testTrain方法学习训练数据,学习完成后,会将训练的结果写入文件。测试的时候,先从文件读取数据,然后根据数据的特征向量,计算输出。此处的程序并没有调用testTrain方法学习训练数据,因为之前已经训练过了。
测试结果如下:
输入[2,’M’],输出1
输入[1,’S’],输出-1
以上是关于python 朴素贝叶斯的主要内容,如果未能解决你的问题,请参考以下文章