ThreadPoolExecutor源码分析
Posted miaomiaoLoveCode
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ThreadPoolExecutor源码分析相关的知识,希望对你有一定的参考价值。
引言
为什么引入线程池技术?
对于服务端的程序,经常面对的是执行时间较短、工作内容较为单一的任务,需要服务端快速处理并返回接口。假若服务端每次接收到一个任务,就创建一个线程,然后执行,这种方式在原型阶段是不错的选择,但是面对成千上万的任务提交进服务器时,这个时候将会创建数以万记的线程,这很明显不是一个好的选择。为什么呢?
- 第一,频繁的线程切换会使操作系统频繁的进行上下文切换,增加了系统的负载;
- 第二,线程的创建和销毁是需要耗费系统资源的,这样子很明显浪费了系统资源。
线程池技术很好的解决了这个问题,它预先创建一定数量的线程,用户不能直接控制线程的创建和销毁,重复使用固定或者较为固定数目的线程来完成任务的执行。这样做的好处:
- 消除了频繁创建和销毁线程的系统资源开销;
- 面对过量任务的提交能够平缓劣化。
ThreadPoolExcutor源码解析
在看具体的源码之前,先给一个线程池使用案例

- 创建线程池对象;
executor.submit(Runnable task)提交10个任务;executor.submit(Callable<T> task)提交5个任务;- 所有线程的管理都由线程池来原理,程序员不需要关注线程的创建销毁。
构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler)
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), handler);核心参数:
- corePoolSize:核心线程数,线程池里一直不会被销毁的线程数量;
- maximumPoolSize:最大线程数量;
- keepAliveTime:非核心线程空闲时的存活时间,该参数只有在线程数量 > corePoolSize情况下才有用;
- unit:keepAlive时间单位;
- workQueue:工作队列,JDK提供这几种工作队列:
ArrayBlockingQueue:基于数组的有界阻塞队列,任务以FIFO顺序排序;LinkedBlockingQueue:基于链表的阻塞队列,任务以FIFO顺序排列,吞吐量优于ArrayBlockingQueue,在使用时需要注意,此阻塞队列在不设置大小的时候,默认的长度是Integer.MAX_VALUE;PriorityBlockingQueue:类似于LinkedBlockQueue,但其所含任务的排序不是FIFO,而是依据任务的自然排序顺序或者是构造函数的Comparator决定的顺序;SynchronousQueue:特殊的BlockingQueue,对其的操作必须是放和取交替完成的,典型的生产者-消费者模型,它不存储元素,每一次的插入必须要等另一个线程的移除操作完成。
threadFactory:创建线程工厂,可以自定义线程工厂给线程池里的线程设置一个自定义线程名。
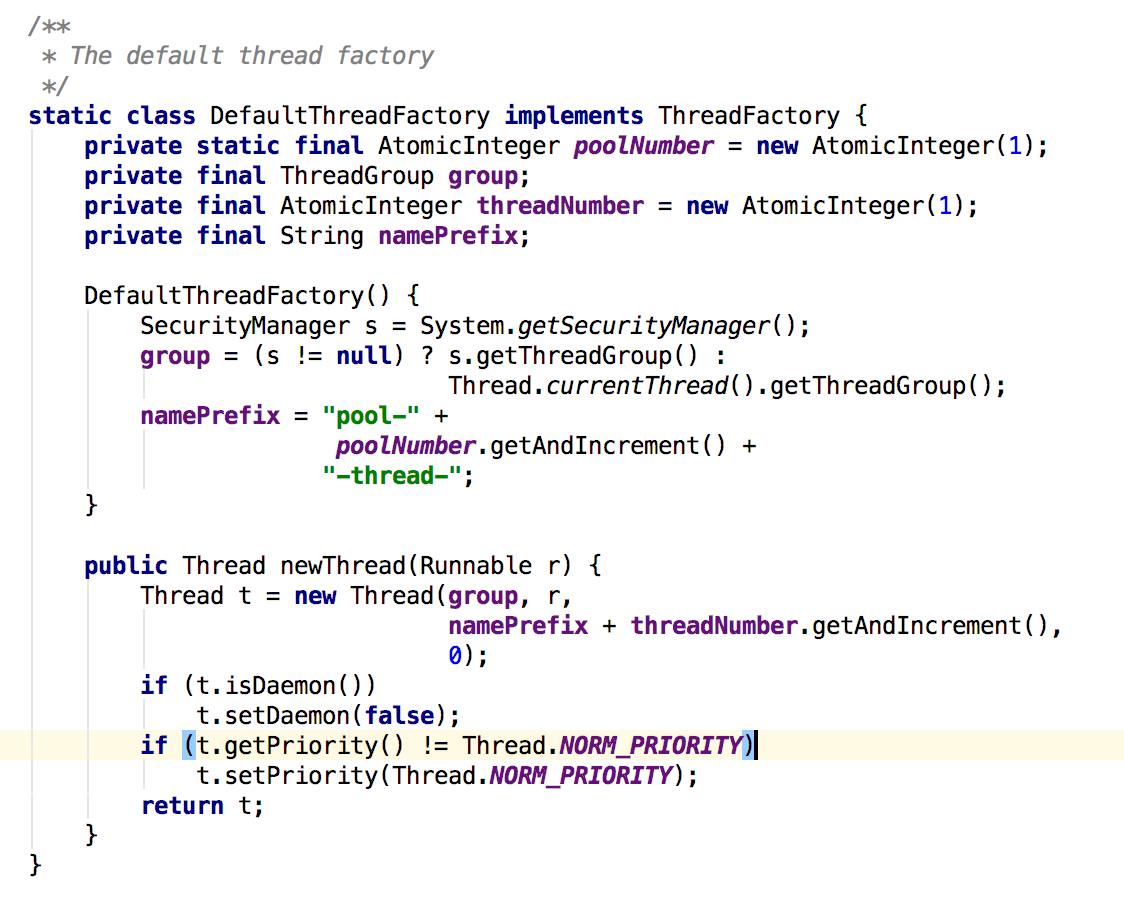
handler:饱和策略,假如线程池已满,并且没有空闲的线程,这个时候不再允许提交任务到线程池,线程池提供了4中策略,至于具体采用哪种策略还是自定义策略,具体情况具体分析。
AbortPolicy:拒绝提交,直接抛出异常,也是默认的饱和策略;CallerRunsPolicy:线程池还未关闭时,用调用者的线程执行任务;DiscardPolicy:丢掉提交任务;DiscardOldestPolicy:线程池还未关闭时,丢掉阻塞队列最久为处理的任务,并且执行当前任务。
线程池内部状态
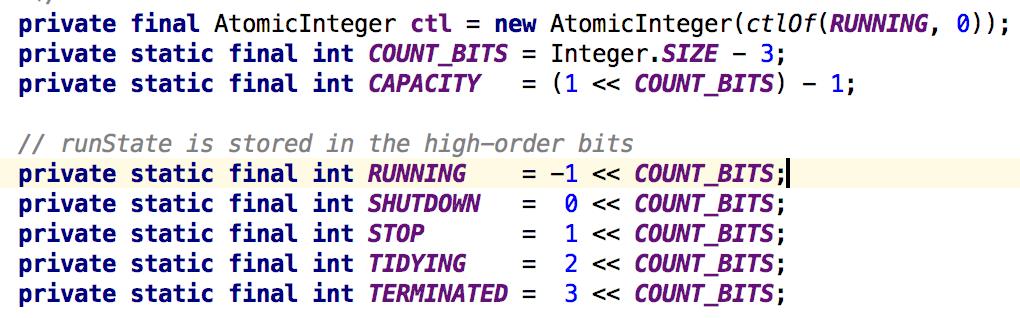
线程池用ctl的低29位表示线程池中的线程数,高3位表示当前线程状态,后续假如想要增大这个值,可以将AtomicInteger改成AtomicLong。
- RUNNING:运行状态,高3位为111;
- SHUTDOWN:关闭状态,高3位为000,在此状态下,线程池不再接受新任务,但是仍然处理阻塞队列中的任务;
- STOP:停止状态,高3位为001,在此状态下,线程池不再接受新任务,也不会处理阻塞队列中的任务,正在运行的任务也会停止;
- TIDYING:高3位为010;
- TERMINATED:终止状态,高3位为011。
接下来就以submit方法入手,分析一下相关源码。
submit任务提交
public Future<?> submit(Runnable task)
//提交的task为null,抛出空指针异常
if (task == null)
throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
//执行任务
execute(ftask);
return ftask;
整个任务的提交核心都在任务执行这部分,执行任务,拿到返回值。
任务执行execute
public void execute(Runnable command)
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize)
if (addWorker(command, true))
return;
c = ctl.get();
if (isRunning(c) && workQueue.offer(command))
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
else if (!addWorker(command, false))
reject(command);
具体的执行流程如下:
- 通过workerCountOf计算出当前线程池的线程数,如果线程数小于corePoolSize,执行addWork方法创建新的线程执行任务;
- 如果当前线程池线程数大于coreSize,向队列里添加task,不继续增加线程;
- 当workQueue.offer失败时,也就是说现在队列已满,不能再向队列里放,此时工作线程大于等于corePoolSize,创建新的线程执行该task;
- 执行addWork失败,执行reject方法处理该任务。
总结一下,对于使用线程池的外部来说,线程池的机制是这样的:
1. 如果正在运行的线程数 < coreSize,马上创建线程执行该task,不排队等待;
2. 如果正在运行的线程数 >= coreSize,把该task放入队列;
3. 如果队列已满 && 正在运行的线程数 < maximumPoolSize,创建新的线程执行该task;
4. 如果队列已满 && 正在运行的线程数 >= maximumPoolSize,线程池调用handler的reject方法拒绝本次提交。
addWorker实现
从全局来看,ThreadPoolExcutor一定维护一个池:

addWorker的实质是向该HashSet里add一个worker,worker有一个线程,这个线程执行完成时,会从该HashSet里remove掉。
看一下addWorker的具体代码实现:
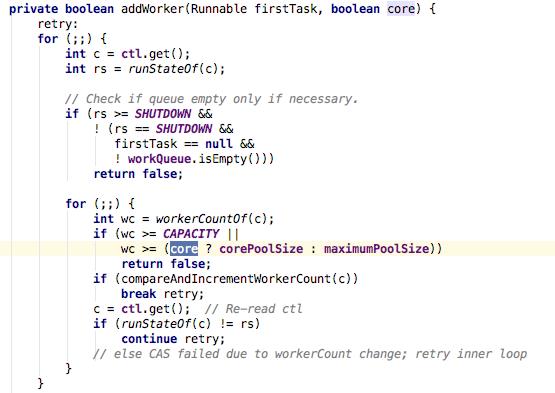
这只是addWorker的前半部分代码,首先,判断当前线程的状态是否符合条件,不符合条件不做处理直接返回;通过参数core判断当前线程是否为核心线程,如果是核心线程,跳出循环创建新的线程来执行该task,在break retry的时候会执行compareAndIncrementWorkerCount(c),利用CAS原则,将线程数量+1。
看看创建线程部分(addWorker的后半部分)代码实现:

创建线程部分最核心的操作就是:new一个新的worker,add进HashSet,然后启动woker里的Thread。
从源码可以看到,在执行add之前先活取了mainLock锁,该锁是一个公用的可重入锁:
private final ReentrantLock mainLock = new ReentrantLock();addWorker的4种调用方式
addWorker(command, true)
线程数 < coreSize时,将task放入workers,如果线程数 >= coreSize,返回false;addWorker(command, false)
当阻塞对列已满,尝试将新的task放入workers,如果线程数 >= maximumPoolSize,返回false;addWorker(null, false)
放入一个空的task到workers,此时线程数的限制是maximumPoolSize,相当于创建一个新的线程,没立马分配任务;addWorker(null, true)
放入一个空的task到workers,线程数 < coreSize。实际的使用是在prestartCoreThread()等方法,有兴趣的读者可以自行阅读,在此不做详细赘述。
Worker具体实现
在addWorker中,t.start()使线程就绪,我们来看看Worker类的具体设计。
- Worker继承AbstractQueuedSynchronizer,方便实现工作线程的中止等操作;
- Worker实现Runnable接口,将自身作为一个task在工作线程中执行;
addWoker中的t.start()实质上是执行Worker的run()方法:
public void run()
runWorker(this);
run方法主要干了一件事,调用runWorker(this),接下来我们来看看runWorker的具体实现。
runWorker具体实现
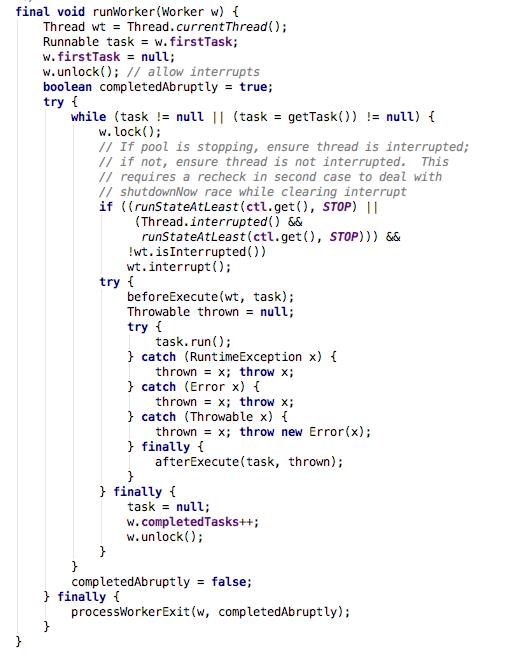
- 线程启动后,释放锁,设AQS状态为0;
- 获取firstTask任务并执行,执行任务前后可定制
beforeExecute和afterExecute; - 如果worker自己的task为null,调用getTask从阻塞队列获取等待任务执行,否则,阻塞该方法。
getTask具体实现
private Runnable getTask()
boolean timedOut = false;
for (;;)
int c = ctl.get();
int rs = runStateOf(c);
//必要情况下需要检查workQueue是否为空
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty()))
decrementWorkerCount();
return null;
int wc = workerCountOf(c);
//如果线程池允许线程超时或者当前线程数大于核心线程数,则会进行超时处理
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty()))
if (compareAndDecrementWorkerCount(c))
return null;
continue;
try
Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();
if (r != null)
return r;
timedOut = true;
catch (InterruptedException retry)
timedOut = false;
整个getTask循环实现:
- workQueue.poll:如果在keepAliveTime时间内阻塞队列有任务,返回该任务并执行;
- workQueue.take:如果阻塞队列为空,当前线程阻塞,当队列有任务时,线程被唤醒,执行take返回的任务。
以上是关于ThreadPoolExecutor源码分析的主要内容,如果未能解决你的问题,请参考以下文章
java多线程系列:ThreadPoolExecutor源码分析
ThreadPoolExecutor的应用和实现分析(中)—— 任务处理相关源码分析