深入分析MySQL行锁加锁规则
Posted 胡玉洋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入分析MySQL行锁加锁规则相关的知识,希望对你有一定的参考价值。
深入分析mysql行锁加锁规则
之前的一篇文章 《深入理解MySQL的MVCC原理》中总结了一下MySQL中的MVCC,它主要利用隐藏字段、版本链、ReadView来实现,可以用来更好地解决多个事务的并发【读+写】问题,但是如果在多个事务并发【写+写】的情况下,就必须要用到锁了,一般情况下,数据库的锁都是在有数据库操作的过程中自动添加的。
MySQL提供了很多种锁:
-
Server层实现了全局锁和元数据锁。
-
数据引擎中,MyISAM、Memory等存储引擎实现了表锁(且只支持表锁),BerkeleyDB存储引擎实现了页级锁,InnoDB实现了行锁和表锁。
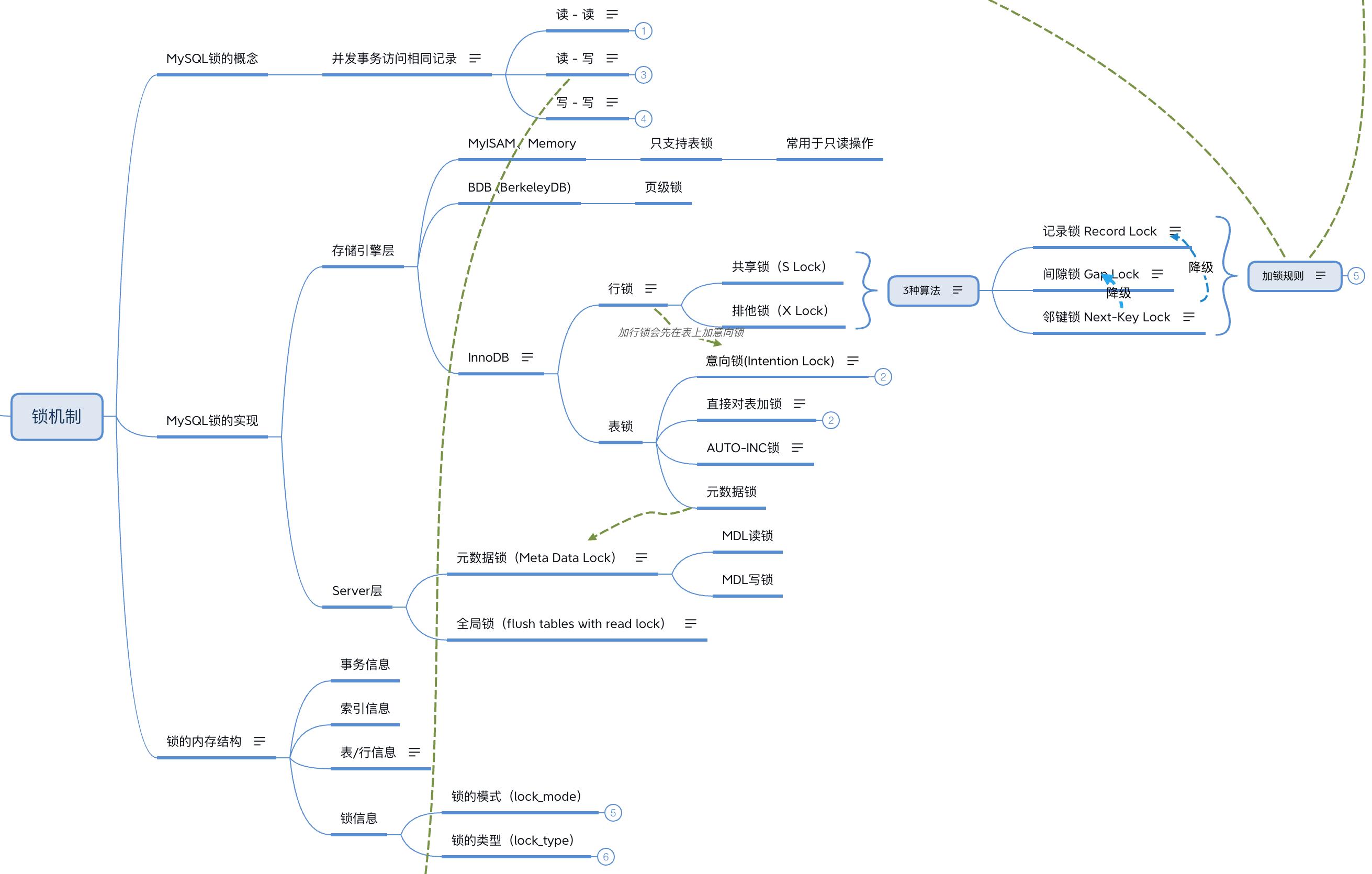
平时最常见、最常用的就是InnoDB的行锁,所以在这里主要来探索一下InnoDB的行锁。
顾名思义,行锁就是给数据库表中每行数据加锁,行锁是加在索引上的,比如某个表中id字段是主键,如果给id=2这条记录加锁,那这把锁是加在主键索引(聚簇索引)上的。如果为某个没有索引的字段加锁,最终会在主键索引上锁住所有的记录。在InnoDB的实现中,行锁有3中主要的算法:
-
Record Lock:对单个行记录上锁,这里我们称为记录锁。
-
Gap Lock:对不包含真实存在记录的某一个间隙/范围加锁,这里我们称它为间隙锁,间隙锁只有一个目的就是在RR、SERIALIZABLE隔离级别下为了防止其他事务插入数据。假如一个索引有2、4、5、9、12 五个值,那该索引可能被间隙锁锁的范围为(-∞ , 2),(2 , 4),(4 , 5),(5 , 9),(9 , 12),(12 , +∞)。
-
Next-Key Lock:相当于Record Lock+Gap Lock,对【某一个行记录】和【这条记录与它前一条记录之间的范围/间隙】都上锁,这里我们称它为邻键锁。假如一个索引有2、4、5、9、12 五个值,那该索引可能被邻键锁锁的范围为(-∞ , 2],(2 , 4],(4 , 5],(5 , 9],(9 , 12],(12 , +∞)。在InnoDB中,加锁的基本单位是Next-Key Lock,只不过在某些特殊情况下会退化为 Record Lock 或者 Gap Lock。
有些同学都会问:“这个sql语句会加什么锁”,其实这是一个伪命题,因为一个语句需要加什么锁受到很多方面的影响。在实际场景中,行级锁加锁规则比较复杂,不同的查询条件,不同的索引,不同的隔离级别,加锁的情况可能不同,甚至不同版本的MySQL加锁规则也可能会稍有差异。
这里我们围绕下面两个问题,记录一下MySQL在默认的RR隔离级别下的行锁加锁情况(在RC隔离级别下加锁的情况跟在RR隔离级别下差不多,不同的是RC隔离级别下只会对记录加Record Lock,不会加Gap Lock 和 Next-Key Lock),暂时不考虑任何操作对表加的意向锁。当前mysql版本:8.0.27。
-
查询条件为主键索引、唯一索引、普通索引对应的字段时,会在哪些索引上加锁?
-
当查询条件是等值查询或范围查询,查询结果存在或不存在时,分别会给索引上的哪些记录加锁(锁住了哪些范围的数据)?
当前MySQL版本:8.0.27,创建和初始化表:
CREATE TABLE `t_lock_test` (
`id` int NOT NULL,
`mobile` varchar(255) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`age` int DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_mobile` (`mobile`) USING BTREE,
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `t_lock_test` VALUES (2, '17118168721', 'Bob', 31);
INSERT INTO `t_lock_test` VALUES (4, '15373838350', 'Bob', 30);
INSERT INTO `t_lock_test` VALUES (5, '13785078432', 'Kara', 20);
INSERT INTO `t_lock_test` VALUES (9, '18901970832', 'Anna', 30);
INSERT INTO `t_lock_test` VALUES (12, '17837938413', 'Kara', 25);
我们创建了一张名为t_lock_test的表,id为主键,mobile为唯一索引,name为非唯一索引,age没有索引。并且插入了5条记录:

这张表对应的3个索引树为:

下面为了简洁,只画出索引的叶子结点,比如主键索引简画为:

这里说明一点:任何情况下的行锁,只会对实际存在的记录(比如上面主键索引中id=12、4、5、9、12的记录)和supremum pseudo-record(最大界限伪记录,下面会说到)加锁。
1 查询条件为主键索引
1.1 等值查询记录存在时,在索引的什么位置加什么锁?为什么?
例1:事务5564执行 select * from t_lock_test where id=5 for update;,通过performance_schema.data_locks表查看MySQL事务获取锁的情况,发现在主键索引上对id=5的记录加上了记录锁:

在索引上锁的范围如下:

此时另一个事务5565执行 select * from t_lock_test where id=5 for update;被阻塞了,等待锁失败:

因为这个事务5565也要获取主键索引上id=5的记录锁:

这里可以得出结论:查询条件为主键索引时,如果查询条件是等值查询且记录存在,只对符合条件的记录加记录锁(只锁符合条件的记录)。
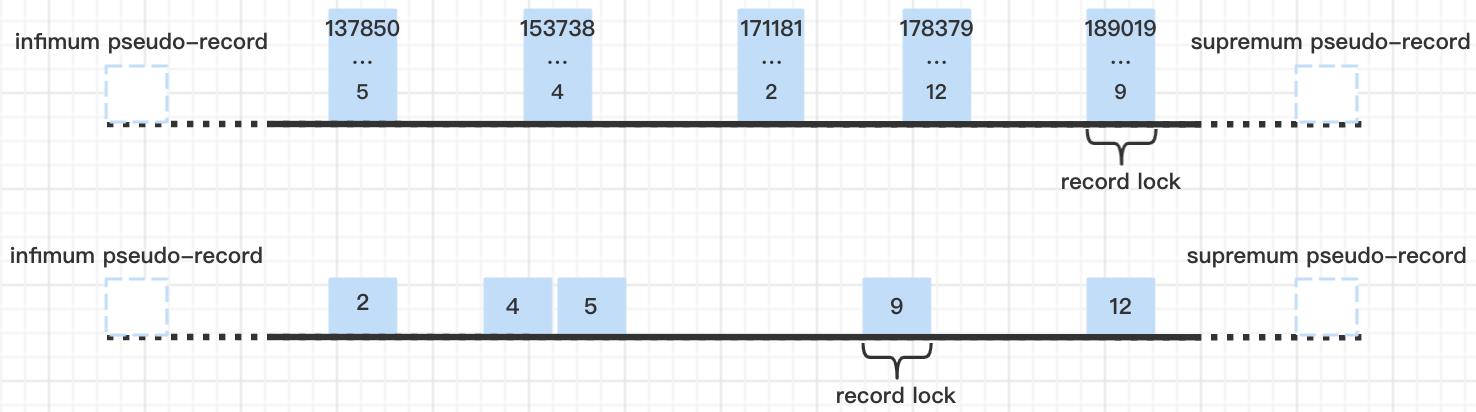
1.2 等值查询记录不存在时,在索引的什么位置加什么锁?为什么?
例1:事务5566执行 select * from t_lock_test where id=7 for update;,加锁情况如下:

在主键索引对id=9的记录加间隙锁(包含7的“间隙”为(5,9),加锁的基本单位是next-key lock,所以对id=9的记录加next-key lock,因为查询条件不包含9,所以退化为gap锁):

此时其他事务执行insert into t_lock_test values(8,'13118161267','Bob',31);也会被阻塞,因为区间(5,9)已经被锁住了,所以此时插入id为6、7、8的记录都会被阻塞。和RC隔离级别不同的是,在RC隔离级别下,不会对id=9的记录加间隙锁。
这里可以得出结论:查询条件为主键索引时,如果查询条件是等值查询且记录不存在,会对查询条件所在间隙的下一条记录加间隙锁(相当于锁的范围就是查询条件所在间隙)。
例2:这里扩展一个例子,当事务执行select * from t_lock_test where id=13 for update;时,加锁情况如下:

发现对supremum pseudo-record这条记录加了邻键锁,supremum pseudo-record 是最大界限伪记录(相当于正无穷+∞), 对应的还有最小界限伪记录infimum pseudo-record(相当于负无穷-∞)。因为supremum pseudo-record的值是最大正无穷,因此它的间隙锁和邻键锁可以看做是一样的(在t_lock_test表中supremum pseudo-record的间隙锁和邻键锁锁的范围都是(12,+∞) ),加锁的基本单位是邻键锁,因此就无需降级了,所以后面只要给supremum pseudo-record加锁,基本上都是邻键锁。
1.3 范围查询记录存在时,在索引的什么位置加什么锁?为什么?
例1:当事务5682分别执行 select * from t_lock_test where id>4 and id <8 for update;、 select * from t_lock_test where id>4 and id <=8 for update;、select * from t_lock_test where id>4 and id <9 for update;时,加锁的情况是一样的:

因为id=5的记录存在于查询条件中(id>4 and id <8、id>4 and id <=8、id>4 and id <9),所以先对id=5的记录加邻键锁;除此之外还要对查询条件的其他部分(id>5 and id<9)加锁,也就是需要对id=9的记录加锁,因为查询条件不包含id=9,所以退化为间隙锁。

例2:当事务执行5681执行select * from t_lock_test where id>4 and id <=9 for update;时,加锁的情况如下:

对id=5的记录加邻键锁,对id=9的记录加邻键锁,不同于例子1的是该查询条件包含id=9的记录,因此id=9上的锁不会退化为间隙锁。
这里可以得出结论:查询条件为主键索引时,如果查询条件是范围查询且记录存在,会对符合条件的记录加邻键锁,对剩余未加锁的间隙的下一条记录加间隙锁(相当于锁的范围就是查询条件对应的区间)。
再来看一种特殊情况,当事务5680执行 select * from t_lock_test where id>7 and id <=12 for update;时,正常逻辑我们猜想的是应该给id=9的记录加邻键锁,给id=12的记录加邻键锁就行了,但实际上还给 supremum pseudo-record 加了邻键锁:

在《MySQL实战45讲》中作者给行锁加锁规则总结了“两个原则”、“两个优化”和“一个bug”(MySQL版本:5.x系列<=5.7.24,8.0系列 <=8.0.13),其中的“一个bug”就是唯一索引上的范围查询会访问到不满足条件的第一个值为止,也就是在上面的例子中虽然扫描到了id=12的索引,还要继续向后扫描,所以还要对supremum pseudo-record加邻键锁。
但是按照上面说的这个“bug”,在例子2中还应该给id=12的记录加间隙锁,但实际上并没有对id=12的记录加间隙锁,所以对于上面说的那个bug,在8.0.27这个版本中,需要加个条件:唯一索引上的范围查询,如果记录中的最大值在查询范围内,会访问到不满足条件的第一个值(这个值其实就是supremum pseudo-record)为止。
我在8.0.13的MySQL中验证了一下,在例子2中当事务执行select * from t_lock_test where id>4 and id <=9 for update;时,加锁情况如下:

这一块的情况可能比较复杂,出现了不同MySQL版本对锁实现不同的情况,建议读者一定要动手实践,
1.4 范围查询记录不存在时,在索引的什么位置加什么锁?为什么?
例1:当事务执行select * from t_lock_test where id>5 and id <9 for update;时,给id=9的索引加间隙锁:

例1:当事务执行select * from t_lock_test where (id>6 and id <9) or id>12 for update;时,给id=9的记录加间隙锁,给supremum pseudo-record加邻键锁:

这里可以得出结论:查询条件为主键索引时,如果查询条件是范围查询且记录不存在,会对查询条件所在范围的下一条记录加间隙锁(相当于锁的范围还是查询条件对应的区间)。
2 查询条件为唯一索引
2.1 等值查询记录存在时,在索引的什么位置加什么锁?为什么?
例1:当事务执行select * from t_lock_test where mobile='18901970832' for update;时,加锁的情况如下:

先在唯一索引idx_mobile上给mobile='18901970832’的记录加记录锁,再在主键索引上对对应的id=9的记录加记录锁。为什么要给主键索引的记录也加一个记录锁呢?如果这时有个并发的事务执行【delete from t_lock_test where id=9】或者【delete from t_lock_test where name=‘Anna’】,最终都需要查找、更新主键索引上id=9的记录,如果不对主键索引加锁,并发操作就能通过除了mobile之外的条件修改mobile='18901970832’的记录。那在前面第一种情况查询条件为主键索引时,为什么没在非主键索引上(唯一索引、非唯一索引)加锁呢?因为即使当修改数据的条件是非主键索引,最终也得查找主键索引(真正要修改的数据页都是主键索引的叶节点~);但是当修改数据的条件是主键索引,是不需要去查找其他索引的。
说到这里有个坑需要注意一下,如果事务执行select * from t_lock_test where mobile=18901970832 for update;,因为mobile字段是varchar类型,但是sql中查询条件是数值型,MySQL为了避免直接报错会尝试进行隐式转换,把数据库中的mobile列使用函数转换为和sql中的类型一致的数据再进行等值判断,而对索引列使用函数时查询不走索引,所以可能会导致经常说的“锁表”(其实锁的不是表,是对所有主键索引中所有的记录加邻键锁),事务执行这条语句加锁的情况如下,对主键索引上的每一条记录都加了邻键锁:

这里可以得出结论:查询条件是唯一索引时,如果查询条件是等值查询且记录存在,除了会在唯一索引上对查到的记录加记录锁,也会在主键索引上对那些记录的主键对应位置上加记录锁。
2.2 等值查询记录不存在时,在索引的什么位置加什么锁?为什么?
例1:当事务5575执行select * from t_lock_test where mobile='15933661689' for update;时,跟上面说的等值查询主键索引记录不存在的情况差不多,会对查询条件所在的间隙的下一条记录加间隙锁:

因为在唯一索引idx_mobile上,mobile='15933661689'的这条记录在mobile='15373838350'和mobile='17118168721'这两条记录中间,所以会对mobile='17118168721'这条记录加间隙锁。

跟上面2.1等值查询记录存在时不一样的是,这种情况没在主键索引加锁,为什么呢?因为在这里加间隙锁的目的就是为了禁止其他事务插入mobile='17118168721'的记录(也就是禁止其他事务执行insert into t_lock_test values(id,’15933661689’,name,age);),具体插入时的id可以使任意和已有id不重复的值,所以就【禁止其他事务插入mobile='17118168721'的记录】这件事来说,和主键索引毫无关系。
这里可以得出结论:查询条件是唯一索引时,如果查询条件是等值查询且记录不存在,在唯一索引上,只会在查询条件所在间隙的下一条记录加间隙锁;在主键索引上不加锁。
2.3 范围查询记录存在时,在索引的什么位置加什么锁?为什么?
例1:当事务6682执行select * from t_lock_test where mobile>'13931766909' and mobile<'17041965526' for update;时,加锁情况如下:

在idx_mobile索引上给mobile='15373838350'和mobile='17118168721'的记录加邻键锁,并且因为mobile='15373838350'这条记录在查询范围内并且存在真实的记录,所以给这条记录对应在主键索引的位置(id=4的记录)也加上了记录锁。
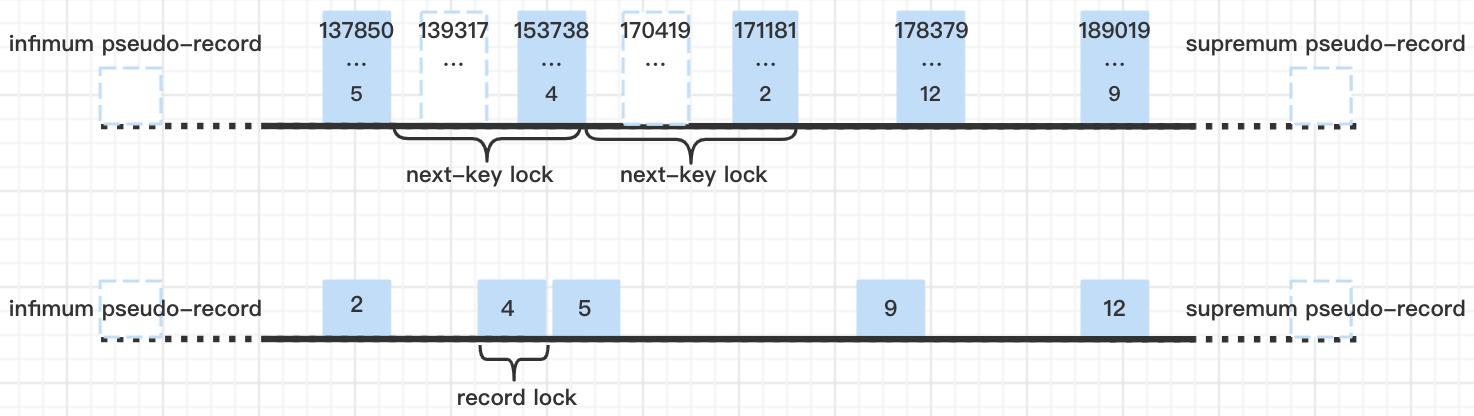
咦?在idx_mobile索引上给mobile='15373838350’的记录加邻键锁没问题,因为mobile='15373838350’的记录在查询条件范围内,但是为什么给mobile='17118168721’的记录也是加邻键锁而不是间隙锁呢(‘17041965526’ 明明小于 ‘17118168721’ 呀)?
此时其他事务6683执行select * from t_lock_test where mobile='17118168721' for update;会被阻塞,在idx_mobile唯一索引上获取mobile='17118168721’的记录锁的状态为WAITING:

但另一个事务6690事务执行select * from t_lock_test where id=2 for update;不会被阻塞,在主键索引上获取id=2的记录锁的状态为GRANTED:

这种情况只是在唯一索引上对查询条件所在区间的下一条记录加了邻键锁,但是没在对应主键索引上加记录锁。
前面提到过《MySQL实战45讲》中作者给行锁加锁规则总结的那“一个bug”——唯一索引上的范围查询会访问到不满足条件的第一个值为止,所以可以理解为这种情况也是属于那个“bug”吧,在唯一索引idx_mobile上访问到’17041965526’时(因为它不存在),继续向后直到访问到’17118168721’这条记录并给它加锁。
这里可以得出结论:查询条件是唯一索引时,如果查询条件是范围查询且记录存在,在唯一索引上,会对查询到的记录加邻键锁,对剩余未加锁的间隙的下一条记录加邻键锁(这里和上面1.3不太一样,不会退化成间隙锁);在主键索引上,会对在查询范围内的记录在主键索引上对应的位置加记录锁。
2.4 范围查询记录不存在时,在索引的什么位置加什么锁?为什么?
事务执行select * from t_lock_test where mobile>'13931766909' and mobile<'15101965526' for update;时,加锁情况如下:

对mobile='15373838350’的记录加邻键锁,正常来说查询条件不包含mobile='15373838350’这条记录,应该退化成间隙锁的,但是和2.4一样,也算是个bug吧~

这里可以得出结论:查询条件是唯一索引时,如果查询条件是范围查询且记录不存在,在唯一索引上,会对查询条件所在间隙的下一条记录加邻键锁;在主键索引上不加锁。
3 查询条件为非唯一索引
3.1 等值查询记录存在时,在索引的什么位置加什么锁?为什么?
事务执行select * from t_lock_test where name='Bob' for update;时,加锁情况如下:

在非唯一索引idx_name上,对name='Bob’的两条记录都加了邻键锁,对name='Bob’记录后面name='Kara’的那条记录加了间隙锁,目的是为了防止在Anna-9至Bob-2、Bob-2至Bob-4、Bob-4至Kara-5这三个间隙中插入name='Bob’的记录;在主键索引上,对对应的id=2、id=4的记录加记录锁:
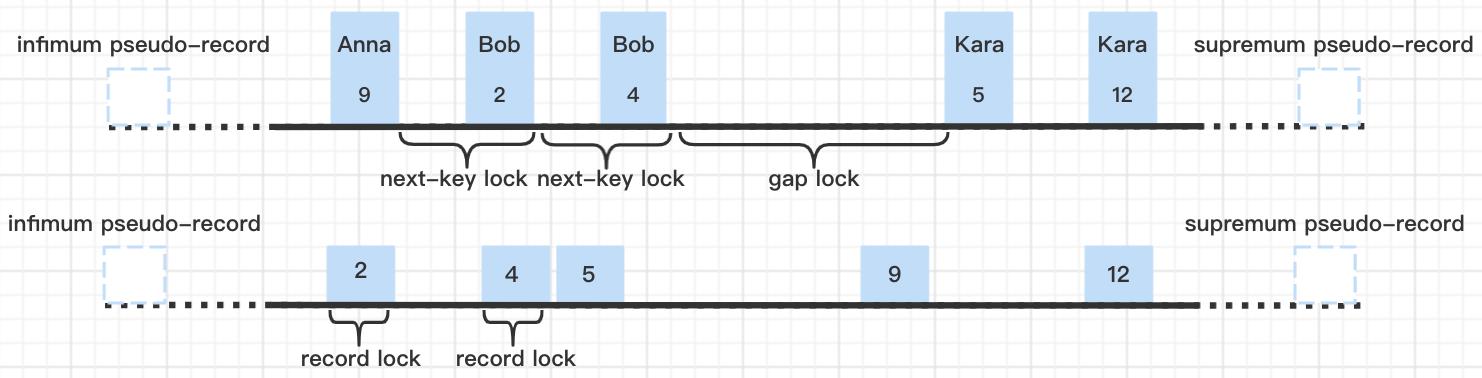
这里可以得出结论:查询条件是非唯一索引时,如果查询条件是等值查询且记录存在,在非唯一索引上,会对符合查询条件的记录加邻键锁,对剩余未加锁的间隙的下一条记录加间隙锁;在主键索引上,对符合查询条件的记录在主键索引对应的位置上加记录锁。
3.2 等值查询记录不存在时,在索引的什么位置加什么锁?为什么?
事务执行select * from t_lock_test where name='Danny' for update;时,加锁情况如下:

对查询条件所在间隙的下一条记录也就是’Kara’=5的记录加了间隙锁,目的是为了禁止其他事务再Bob-4至Kara-5之间插入name='Danny’的记录。

这里可以得出结论:查询条件是非唯一索引时,如果查询条件是等值查询且记录不存在,在非唯一索引上,会对符合查询条件所在间隙的下一条记录加间隙锁;在主键索引上不加锁。
3.3 范围查询记录存在时,在索引的什么位置加什么锁?为什么?
事务执行select * from t_lock_test where name > 'Anna' and name < 'Danny' for update;时,加锁情况如下:

在非唯一索引idx_name上,对name='Bob’的两条记录都加了邻键锁(因为这两条记录都在查询范围之间),对name='Bob’记录后面name=‘Kara’的那条记录加了邻键锁,目的是为了防止在Bob-4至Kara-5的间隙中插入’Bob’ <= name <'Danny’的记录,正常来说对name='Kara’的记录加间隙锁就行了,那个bug又出现了~;在主键索引上,对对应的id=2、id=4的记录加记录锁:

这里可以得出结论:查询条件是非唯一索引时,如果查询条件是范围查询且记录存在,在非唯一索引上,会对符合查询条件的记录加邻键锁,对剩余未加锁的间隙的下一条记录加邻键锁(实际上加间隙锁就可以了);在主键索引上,对符合查询条件的记录在主键索引对应的位置上加记录锁。
3.4 范围查询记录不存在时,在索引的什么位置加什么锁?为什么?
当事务执行select * from t_lock_test where name > 'Danny' and name < 'Ella' for update;时,加锁情况如下:

对name=‘Kara’的记录加邻键锁,目的是为了防止在Bob-4至Kara-5的间隙中插入’Danny’ <= name <'Ella’的记录,正常来说对name='Kara’的记录加间隙锁就行了,bug again ~

这里可以得出结论:查询条件是非唯一索引时,如果查询条件是范围查询且记录不存在,在非唯一索引上,会对查询条件所在间隙的下一条记录加邻键锁(实际上加间隙锁就可以了);在主键索引上不加锁。
4. 查询条件为非索引
当事务执行select * from t_lock_test where age=20 for update;、select * from t_lock_test where age=21 for update;、select * from t_lock_test where age>21 and age<=25 for update;、select * from t_lock_test where age>25 and age<30 for update;时,加锁的情况都是一样的:

对表中的每一条记录包括最大界限伪记录supremum pseudo-record都加了邻键锁。
这里可以得出结论:当查询条件为非索引时,无论是等值查询还是范围查询,无论是否存在查询结果,都会对表中所有的记录加邻键锁,也就是我们常说的“锁表”。
转载请注明出处——胡玉洋 《深入分析MySQL行锁加锁规则》
以上是关于深入分析MySQL行锁加锁规则的主要内容,如果未能解决你的问题,请参考以下文章