Hadoop之生态体系
Posted wanmeilingdu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop之生态体系相关的知识,希望对你有一定的参考价值。
一、Hadoop起源:Google的集群系统
Google的数据中心使用廉价的LinuxPC机组成集群,在上面运行各种应用。即使是分布式开发的新手也可以迅速使用Google的基础设施。核心组件是3个:
1、GFS(GoogleFileSystem):一个分布式文件系统,隐藏下层负载均衡,冗余复制等细节,对上层程序提供一个统一的文件系统API接口。Google根据自己的需求对它进行了特别优化,包括:超大文件的访问,读操作比例远超过写操作,PC机极易发生故障造成节点失效等。GFS把文件分成64MB的块,分布在集群的机器上,使用Linux的文件系统存放。同时每块文件至少有3份以上的冗余。中心是一个Master节点,根据文件索引,找寻文件块。详见Google的工程师发布的GFS论文。
2、MapReduce:Google发现大多数分布式运算可以抽象为MapReduce操作。Map是把输入Input分解成中间的Key/Value对,Reduce把Key/Value合成最终输出Output。这两个函数由程序员提供给系统,下层设施把Map和Reduce操作分布在集群上运行,并把结果存储在GFS上。
3、BigTable:一个大型的分布式数据库,这个数据库不是关系式的数据库。像它的名字一样,就是一个巨大的表格,用来存储结构化的数据。
二、Hadoop生态体系介绍
Hadoop是一个能够对大量数据进行分布式处理的软件框架。具有高可靠性、高扩展性和高吞吐率的特点。
Hadoop的核心是HDFS和Mapreduce,hadoop2.0还包括YARN。
下图为hadoop的生态系统:
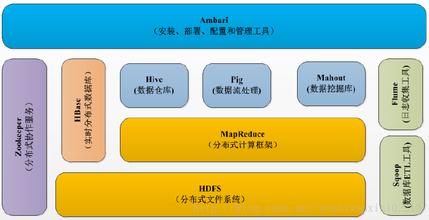
三、HDFS分布式文件系统
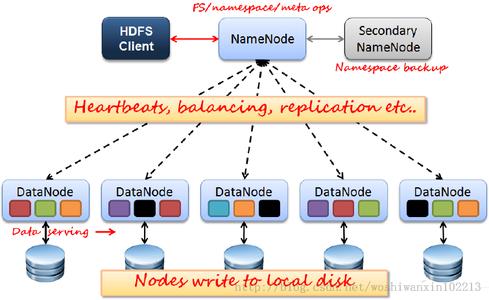
HDFS是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。下图是HDFS架构图:
四、MapReduce分布式计算框架
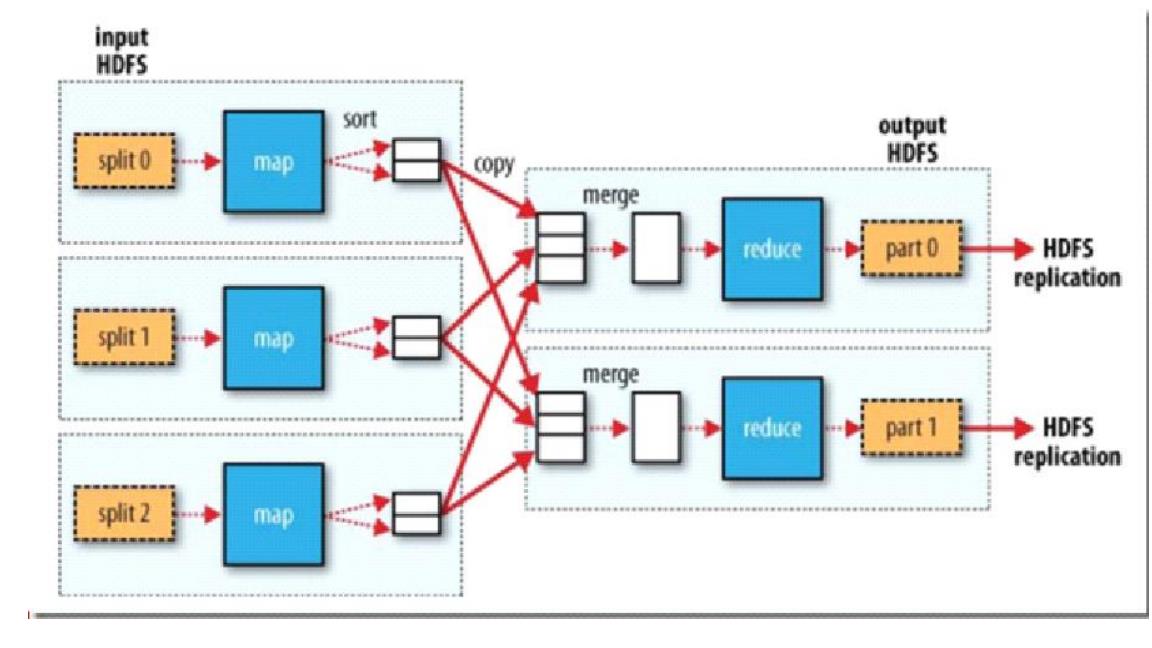
MapReduce是一种计算模型,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对对map阶段的结果进行汇总,以得到最终结果。MapReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。下图是MapReduce的架构图:
五、Zookeeper分布式协作服务
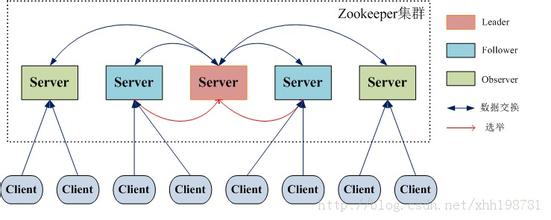
Zookeeper 是 Google 的 Chubby一个开源的实现,是 Hadoop 的分布式协调服务;它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。
六、HBase分布式列存储数据库
类似Google BigTable的分布式NoSQL列数据库。
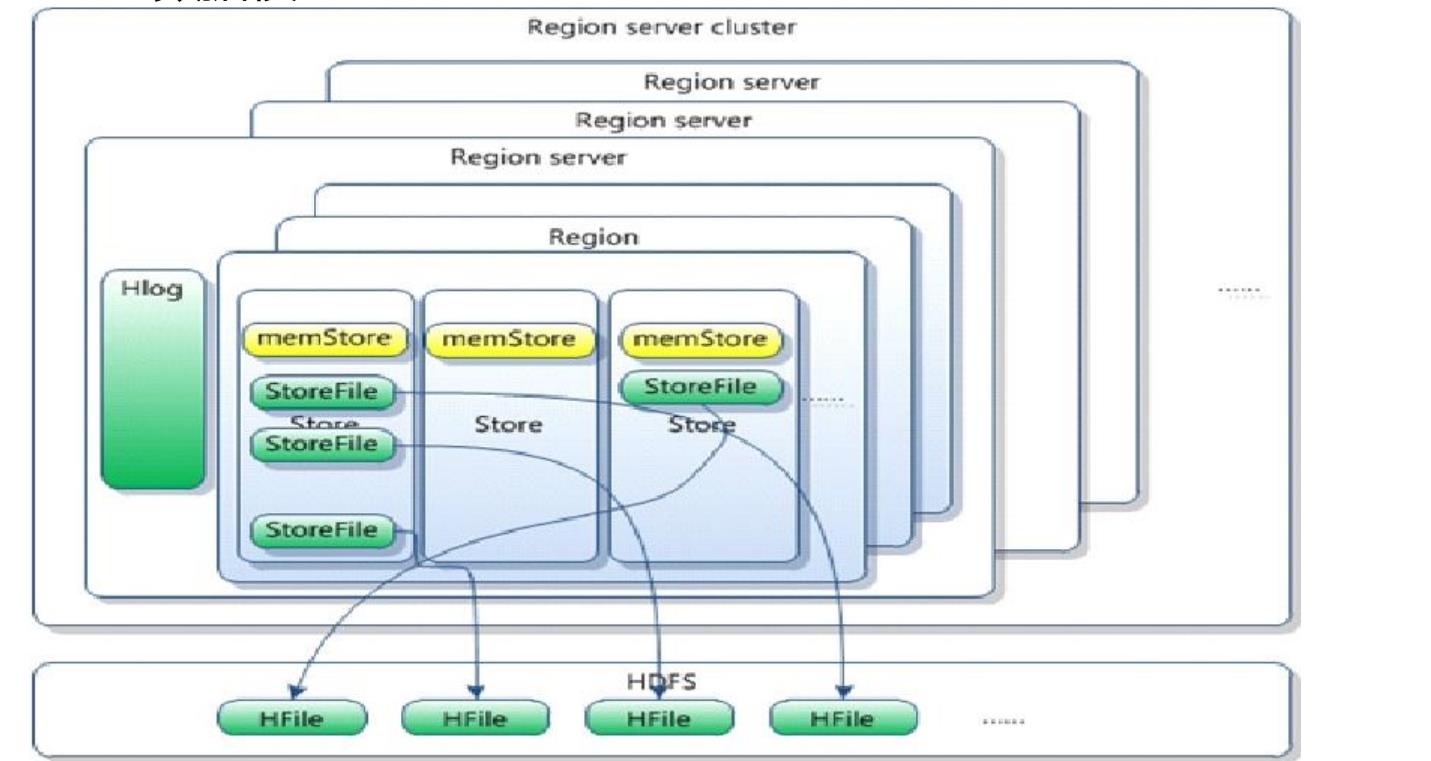
HBase是一个高可靠性、高性能、面向列、可伸缩、实时读写的分布式数据库;利用Hadoop HDFS作为其文件存储系统;利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为其分布式协同服务;主要用来存储非结构化和半结构化的松散数据(列存 NoSQL 数据库)。下图是HBase体系架构图和数据模型图:

七、Hive数据仓库
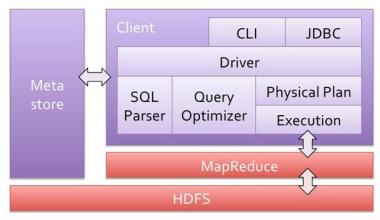
Hive的产生是针对非java编程者对HDFS的数据做mapreduce操作。Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。下图为Hive的架构图:
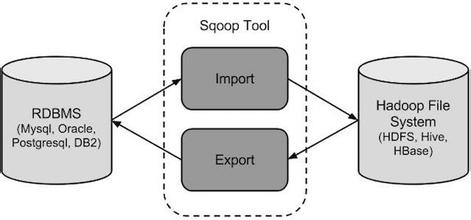
八、Sqoop数据同步工具
用于在HADOOP与传统的数据库间进行数据的传递,数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。
九、Mahout数据挖掘算法库
Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或Cassandra)集成等数据挖掘支持架构。
十、Pig:数据流系统
是一种基于MapReduce的ad-hoc数据分析工具定义的一种数据流语言Pig Latin,将脚本转换为MapReduce任务在Hadoop上执行,用于大数据分析平台,为用户提供多种接口。
十一、Avro数据序列化的系统
数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。
十二、Flume日志收集工具
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
以上是关于Hadoop之生态体系的主要内容,如果未能解决你的问题,请参考以下文章