客快物流大数据项目(八十六):ClickHouse的深入了解
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了客快物流大数据项目(八十六):ClickHouse的深入了解相关的知识,希望对你有一定的参考价值。

文章目录
ClickHouse的深入了解
一、介绍
- ClickHouse是俄罗斯的Yandex于2016年开源的面向OLAP列式数据库管理系统(DBMS)
- ClickHouse采用 C++ 语言开发,以卓越的查询性能著称,在基准测试中超过了目前很多主流的列式数据库
- ClickHouse集群的每台服务器每秒能处理数亿到十亿多行和数十千兆字节的数据
- ClickHouse会充分利用所有可用的硬件,以尽可能快地处理每个查询
- 单个查询(解压缩后,仅使用的列)的峰值处理性能超过每秒2TB
- 允许使用类SQL实时查询生成分析数据报告,具有速度快、线性可扩展、硬件高效、容错、功能丰富、高度可靠、简单易用和支持跨数据中心部署等特性,号称在内存数据库领域是最快的
- ClickHouse提供了丰富的数据类型、数据库引擎和表引擎,它所存储的表类似于关系型数据库中的表,默认情况下使用结构化方式在节点本地存储表的数据,同时支持多种数据压缩方式
- ClickHouse独立于Hadoop生态系统,不依赖Hadoop的HDFS,但可以扩展HDFS进行数据查询,ClickHouse还支持查询Kafka和mysql中的数据
- ClickHouse目前已经在很多大型企业中得到了充分的生产验证,其在存储PB级别的数据规模时仍能很好的提供稳健的实时OLAP服务。
二、特性
- 真正面向列的DBMS
ClickHouse是一个真真正正的列式数据库,同时也是一个完美的数据库管理系统;因为它允许在运行的时候创建数据库和表,同时加载数据和运行查询,而且无需重新配置和重启服务。
目前市面上的列式存储数据库也有很多,比如Hbase、BigTable、Cassandra等,拿Hbase来说,Hbase存储数据的同时,每个Cell都存储了一份rowkey、columnFamily、timestamp的数据,导致了吞吐量的显著差异:
| ClickHouse | Hbase | |
| 吞吐量 | 几亿行/s | 数十万行/s |
- 支持压缩
在一些列式数据库管理系统中(例如:InfiniDB CE 和 MonetDB) 并没有使用数据压缩。但是, 若想达到比较优异的性能,数据压缩确实起到了至关重要的作用;
- 支持普通硬盘存储
很多列式数据库只支持在内存中工作,如Google PowerDrill、SAP HANA等,但是ClickHouse支持廉价的传统磁盘存储(TIDB只对SSD固态硬盘比较友好),在底层磁盘物理存储的方式上按照primary-key进行排序,可以实现ms级别的按照特定的范围或者单个primarykey进行快速查询,而且提供了每GB更低的存储成本,如果可以使用SSD和内存,那么它也会很好的利用资源,实现更好的服务效果。
- 支持多核并行处理
ClickHouse可以将数据存储在不同的shard(分片)上,每一个shard都由一组容错的replica组成,这个其实GreenPlum也可以做到,TIDB也可以做到,查询操作可以被分布到每个shard中进行处理,对用户来说是透明的,就好像Hbase的查询实际上是被分布到了不同的region中通过regionscanner进行处理。
- 支持SQL
Hbase原生不支持SQL,需要借助Kylin或者Pheonix,因为系统组件越多稳定性越低,维护成本越高;
ClickHouse支持SQL查询,GROUP BY,JOIN ,IN,ORDER BY等;
ClickHouse不支持窗口函数和相关的子查询,所以一些逻辑需要开发者另想办法;
- 支持矢量引擎
ClickHouse不仅支持列存储,支持向量引擎,当查询大量row的时候,按列的存储顺序往下查找,大量减少了CPU的等待时间,从而高效实用CPU资源;
- 支持实时数据更新
ClickHouse在使用Merge tree引擎的时候,插入数据的时候按照数据的primary-key进行递增排序进行磁盘存储,所以数据能被持续的添加到表中,而且在插入新数据的时候是没有lock的,减少了sycn校验的时间。
- 支持索引
ClickHouse支持创建主键primarykey,这将帮助ClickHouse在几十ms的情况下对特定的数据范围进行查询并展示到页面;
- 支持在线查询
- 支持近似计算
ClickHouse提供各种各样在允许牺牲数据精度的情况下对查询进行加速的方法:
- 用于近似计算的各类聚合函数,如:distinct values, medians, quantiles
- 基于数据的部分样本进行近似查询。这时,仅会从磁盘检索少部分比例的数据。
- 不使用全部的聚合条件,通过随机选择有限个数据聚合条件进行聚合。这在数据聚合条件满足某些分布条件下,在提供相当准确的聚合结果的同时降低了计算资源的使用。
- 支持数据辅助和数据完整性
ClickHouse实用async的多主复制技术,当数据被写入任何一个可用的副本后,系统会在后台将数据分发给其它的副本,以保证系统在不同副本上保持相同的数据;
三、优势
- 高性能
- 线性可扩展
- 硬件高效
- 容错
- 高度可靠
- 简单易用
四、劣势
- 缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据。
- 没有完整的事务支持
- 有限的SQL支持,join实现与众不同
- 不支持二级索引
- 不支持窗口功能
- 元数据管理需要人工干预维护
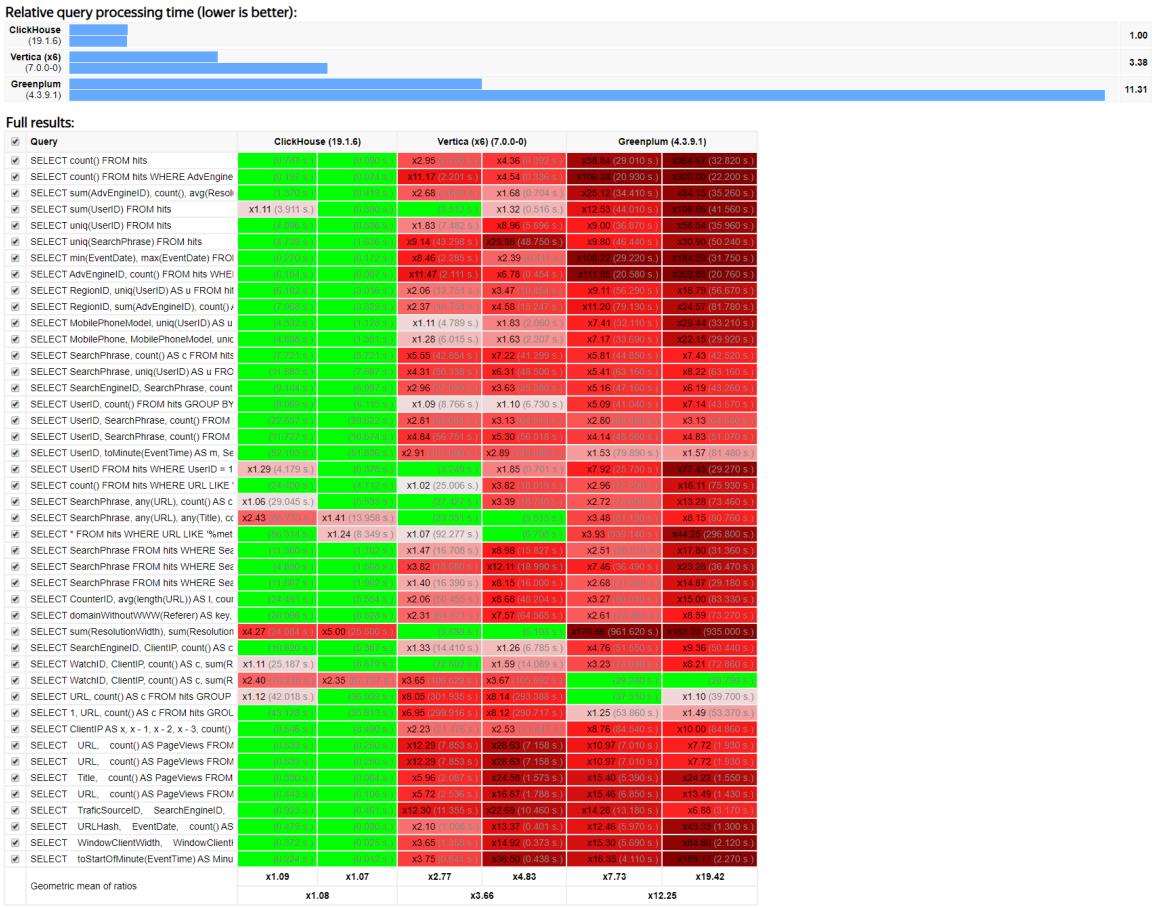
五、基准测试
ClickHouse提供了一个与其他列式数据库的基准测试,这个基准测试大多数是在单台服务器进行测试,该服务器的配置是:
- 双CPU(Intel(R) Xeon(R) CPU E5-2650 v2@2.60GHZ)
- 内存128GB
- 在8个6TB SATA硬盘上安装MD RAID-5
- 文件系统为Ext4
这个测试中,有些结果可能是过时的,如图:
六 、应用场景
- 绝大多数请求都是用于读访问的
- 数据需要以大批量(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作
- 数据只是添加到数据库,没有必要修改
- 读取数据时,会从数据库中提取出大量的行,但只用到一小部分列
- 表很“宽”,即表中包含大量的列
- 查询频率相对较低(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许大约50毫秒的延迟
- 列的值是比较小的数值和短字符串(例如,每个URL只有60个字节)
- 在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)
- 不需要事务
- 数据一致性要求较低
- 每次查询中只会查询一个大表。除了一个大表,其余都是小表
- 查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于客快物流大数据项目(八十六):ClickHouse的深入了解的主要内容,如果未能解决你的问题,请参考以下文章
客快物流大数据项目(八十九):ClickHouse的数据类型支持
客快物流大数据项目(九十六):ClickHouse的VersionedCollapsingMergeTree深入了解