自动驾驶激光点云 3D 目标检测 PointPillar 论文简述
Posted frank909
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动驾驶激光点云 3D 目标检测 PointPillar 论文简述相关的知识,希望对你有一定的参考价值。
之前有针对 VoxelNet 这篇论文做过简述,今天的主题是 PointPillar。
PointPillar 是 2019 年提出来的模型,相比于之前的点云处理模型,它有 3 个要点:
- 提出 Pillar 这个概念,将类 PointNets 模型能够以 Pillar 为基础单位学习点云特征
- 运用标准化的 2D 卷积进行后续处理
- 快,满足实时要求,最快的版本到达 105 Hz
PointPillar 和前辈
处理点云最先需要大量的手工作业,后来 VoxelNet 第一次引入了真正的端到端的特征学习。
但 VoxelNet 又是基于 PointNet 的基础上做了进行的模型设计。
VoxelNet 很优秀,但有 2 个不足的地方:
- 运用了 3D 卷积,这个对 GPU 不友好
- 慢,只有 4.4 Hz
因为,VoxelNet 慢,所以,后面又有了新的网络 SECOND.
SECOND 将速度提升到了 20Hz,但是仍然保留了 3D 卷积。
好了,轮到 PointPillar 出场了。
在它的前辈
PointNet
VoxelNet
SECOND
基础上,它有一些显著的特性:
- 端到端的网络模型
- Pillar 和 2D 卷积贡献的极速推理速度
- 在当时 KITTI 数据集上 SOTA 表现
PointPillar 细节
PointPillar 处理点云到结果分 3 个步骤。
- 点云到伪图像的转换
- 2D backbone 网络学习高层次表征
- 检测头进行 3D Box 的检测和回归

点云到伪图像
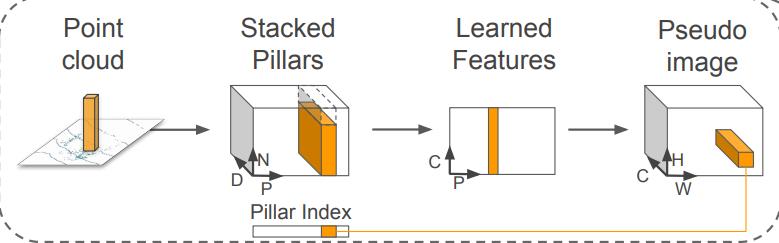
在 VoxelNet 当中会将所有的点云切割成一个一个 Grid 称为 Voxel。
PointPillar 也这样做,但是在 z 轴上它不进行切割,相当于精简版本的 Voxel,也可以看成 z 轴上的 Voxel 合成一个 Pillar。
在一个 Pillar 中单个点云可以被如下表示:
x , y , z , r , x c , y c , z c , x p , y p x,y,z,r,x_c,y_c,z_c,x_p,y_p x,y,z,r,xc,yc,zc,xp,yp
这是个 9 维的增广向量,维度用 D 表示,这里 D = 9。
其中
x,y,z 是物理位置
r 是点云反射率
下标 c 是指代一个 Pillar的质心,在这里需要求出一个点云 xyz 相对质心的偏移量
下标 p 指代 Pillar 的物理中心,同样要求 x,y 的相对偏移量
为了把稀疏的点云形成稠密的数据,PointPillar 运用了 2 个手段:截取和补齐
- 截取体现在:
非空的 Pillar 数量超过 P 个则截取,单个 Pillar 点云数量超过 N 个就随机采样 N 个 - 相反的,补齐体现在:
如果 Pillar 数量过少,或者单个 Pillar 点云过少则用 0 补齐
最终所有的点云会聚集到一个稠密的尺寸为 (DxNxP) 的 Tensor 上。
然后对于每一个点云运用一个简化版本的 PointNet,之后再跟着一个简单的线性层
BN
ReLu
这个线性层等效于 1x1 的卷积。
最终能够学习到点云特征,产生了尺寸为 (CxPxN) 的 Tensor。
现在,还需要做一步工作,将点云根据索引移动回来原来的位置,产生伪图像(pseudo-image),尺寸是 (CxHxW),HW是画布的高和宽.
backbone
和 2D 目标检测一样,3D 目标检测网络中也有 backbone 模块。
PointPillar 中的 backbone 长这样。

backbone 的处理流程有 3 步:
- 渐进式下采样,形成金字塔特征
- 对应特征上采样到统一的尺寸
- 拼接
下采样由一系列 Block(S,L,F) 组成。
S 是相对于伪图像的 stride。
L 是 3x3 尺寸的 2D 卷积层数
F 是输出通道数
上采样的操作用 U P ( S i n , S o u t , F ) UP(S_in,S_out,F) UP(Sin,Sout,F) 表示。
in 和 out 代表 stride 是从 in 的数量到 out 的数量.
最终要得到 F 个 featrue,最终一起拼接起来。
个人的理解:为了得到不同尺寸的信息,所以需要下采样,但为了将所有信息重新统一定位到原 pseudo-image 上,所以要通过上采样重新调整尺寸.
Detection Head
PointPillar 中是用 SSD 来做 3D 检测的。
与先验的 box 对比采样的也是 2D 的 IoU。
向上的 height 和 elevation 没有参与 IoU,但添加到了额外的回归任务当中。
Loss
PointPillar 的 Loss 函数和 SECOND 保持一致。
Loss 由 3 个子 Loss 组成:
- Loc 定位
- Dir 方向
- Cls 类别
先看定位:

然后,
d
a
d^a
da代表 anchor 的对角线.

最终的定位 Loss 如下:

再看 Dir 的 Loss,它直接采用 Softmax 分类形式。
目标分类的 Loss 采用 Focal Loss:

在这里
α
=
0.25
,
γ
=
2
\\alpha=0.25,\\gamma=2
α=0.25,γ=2
最终的 Loss 由 3 个 Loss 调和形成。

N
p
o
s
N_pos
Npos是 anchor box 正样本数量。
β
l
o
c
=
2
,
β
c
l
s
=
1
,
β
d
i
r
=
0.2
\\beta_loc=2,\\beta_cls=1,\\beta_dir=0.2
βloc=2,βcls=1,βdir=0.2
数据增强
PointPillar 也是以 KITTI 为测试基准的,好其他网络一样,由于样本数量过少,数据增加也就是必不可少的操作。
PointPillar 论文中有提到,它是跟随 SECOND 的思路做的一张 lookup table,然后对于每个类别随机取样。
之后就是常规的旋转、翻转、缩放、平移之类。
表现
PointPillar 将自己的表现划分 2 个指标:mAP 和 AOS.

这个无非是想说,我很牛,我基于纯 Lidar 数据能够和 lidar+Image 融合数据后的模型媲美。
其实,我更感兴趣的是 AOS 这个指标。
AOS 是 average orientation similarity (AOS) 的意思,自然是衡量 3D box 的方向相似度。

总结
PointPillar 充分吸收前人的思想,一字排开:
- PointNet
- VoxelNet
- SECOND
最终,形成了一个能基于纯 lidar 数据媲美融合数据模型的检测效果,并且速度极快。
所以,它很棒,点个赞,在自动驾驶世界中,快是王道,不讲速度的模型是耍流氓。
以上是关于自动驾驶激光点云 3D 目标检测 PointPillar 论文简述的主要内容,如果未能解决你的问题,请参考以下文章