分析的应用(RST-style discourse parsing and its applications in discourse analysis)
Posted 刘炫320
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分析的应用(RST-style discourse parsing and its applications in discourse analysis)相关的知识,希望对你有一定的参考价值。
引言
这位是Wei Vanessa Feng的博士论文的第二部分,主要讲述了篇章分析的一些应用,本文主要是对于其连贯性评估方面的一些介绍。
6.1 引言
一个写的非常好的文章,其各部分之间不是随机的顺序,而是有逻辑和连贯形式的,因此读者才能够容易的理解文章的内容。因此,自动评估连贯性是非常有必要的。例如,在文本生成中,一旦文本生成后,就需要一个后处理的程序来提高文本的连贯性。在多文档摘要中,生成的文章摘要应该是最连贯的。在论文打分中,连贯性也是一个主要打分方面。这里首先介绍最经典的连贯性模型基于实体的局部连贯性模型(B&L),然后再介绍自己的模型。
6.1.1 基于实体的局部连贯性模型
这里我们不细讲了,给一张图大家就可以知道它是怎么回事了。
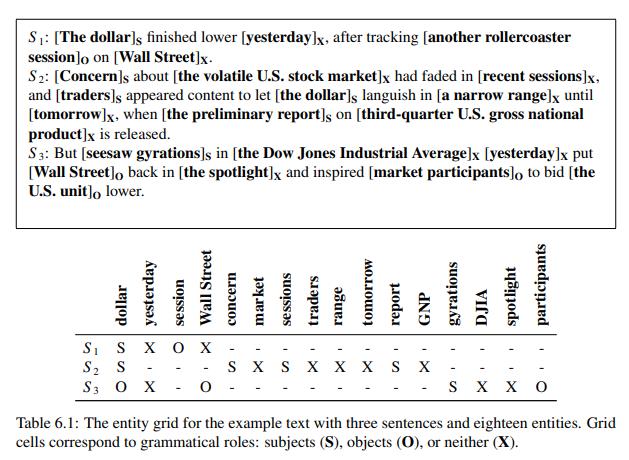
6.1.2 评价任务
有两个任务,一个是句子排序,一个是摘要连贯性打分。
句子排序就是给定一系列句子,随机打乱,然后认定打乱后的句子的连贯性低于原始句子。最后根据打乱后的句子与原始句子的排名上的正确率进行评估。
在摘要连贯性打分这块,也使用连贯性模型,不过与句子排序不同的是,这个任务是真实的语料,而不是合成的(synthetic)语料,即不是造出来的语料。
6.1.3 扩展
这里都是基于BL理论的扩展模型,我们后面再说。
6.2基于多重排序的实体连贯性模型扩展
之前的模型一般专注于丰富原始特征集合来融入其他文档信息。而与之相反,我们更希望去定义一个学习过程来让模型能够学习到更加细颗粒度的连贯性评估。特别的,我们提出了一个简明的扩展,不仅学习原始文档与变换后文档,而且也学习变换后文档之间的偏好。
我们显示,我们通过设置一个合理的目标分数对于每个变换来表示它与原文的不相似程度。我们称之为多重排序模型因为我们使用了一个多重排序的基础。这个扩展也可以很好的和其他扩展相组合。我们显示我们的模型可以在句子排序和摘要连贯性评估上都超过了BL。
6.2.1 实验设计
句子排序,标准的句子排序就是一个随机的排列和原文档之间的连贯性比较。这种成对的排序模型学习起来不够精细,因为排列间的细微差异没有学习。我们的主要贡献就是进一步区分不同排序间的排列,而不是简单的把他们认为是同一级别的连贯。
我们的一个基本假设就是一个文档的句子间存在一种合理规范的顺序。因此我们可以通过比较真实句子顺序和这种理想化的句子顺序之间的相似程度来评判文档的连贯性。实际上,我们自动的赋予了每个排列一个合适的客观分数来评估它和原文档之间的不相似性。通过学习所有的排列与原文之间的文本对,增加了大量的训练样本的同时也没有额外增加人工标注。
摘要连贯性打分。相比较标准的基于实体的连贯性模型,我们的主要贡献就是自动的给机器生成的摘要赋予一个客观的分数用来评估它和人类生成的摘要之间的不相似性。我们可以取得差不多甚至更好的性能相比较BL的模型,在不知道真实的连贯性分数的情况下。
在这个任务上关键在于评估我们的多重排序模型,因为摘要的连贯性打分任务可以更加精确的近似读者可能在真实的机器生成的文本的连贯性打分,而句子排序任务只能做到部分。
6.2.2 排序指标
既然认为排序上的不同也会带来连贯性上的差异,因此需要一个评价指标来告诉我们连贯性的高低。给定测试排序和原始排序,那么需要的评价指标需要满足以下准则:(1)可以自动计算;(2)独立于实体的评价,从而能够评价真实的句子顺序而不是实体转移概率。
这里我们使用3个距离评估指标,肯德尔距离、平均连续性、编辑距离。
6.2.3 实验1句子排序
我们第一个实验集合是句子排序,并且,我们探寻了3个特别的方面:排序评估、实体抽取和排序生成。
6.2.3.1 排序评估
在我们的多重排序模型中,对排序被我们纳入到了一个更长的多重排序中,这个排序顺序使用的是刚才讲的3个指标。我们使用两种不同的方法进行排序评估,每个部分中,源文档都会被看作是最高级别排名。
在生语料设置中,我们直接根据不相似性对一系列的排列进行一个完整的排序。由于一个完整的排序可能对于噪声太过敏感在训练过程中,因此我们也使用了分层设置进行实验。
在分层实验中,我们选取最相似的文章作为最高级,最不相似的文章作为最低级,而其他的排列则根据它们的分数在其中归一化分布,这里选择3-6个等级。如果是2个等级的话,那就是标注你的基于实体的模型。
6.2.3.2 实体抽取
BL中最好的结果是使用自动同指消解工具抽取出的实体。而且是在已知正确的句子顺序上进行的,因为在一个重排序的文档上进行自动同指消解太不可靠了。
我们也是使用了已有的自动同指消解工具获得完整的同指消解,正如Elsner(2011)中指出的那样,为了更好的模拟真实的人类阅读的环境,这些理想状态下的信息是不能够获得的,因此我们也有没有使用同指消解的方法,比如使用字符串匹配的方式进行。
6.2.3.3生成排列方式
我们不清楚BL是如何生成重排序的样本的,我们假设他们是完美的随机打乱的方式。
然而,事实上,不同的打乱顺序的影响是不同的。例如,在作文打分中,如果目标是一个接受良好教育的母语者,那么我们应该认为它们的论文会更加的连贯,因此文章大部分都是连贯的,只有一些小瑕疵。这样的话,就不太适合同一分布的随机生成了。
因此,除了使用原始的BL的方式进行生成重排列的数据外,我们还使用了最接近原始文本最大概率的方式进行生成。这也有另外一个优点,在标准的实体模型中,所有的被打乱的文本都被认为是不连贯的,这回导致连贯和不连贯的比例是20:1。然而,我们的多重排序模型通过不同的连贯性等级来进一步区分文章不同程度的连贯性。这样做的话,我们确实能够学习到连贯性的不同的同时,缓和缺少连贯性样本的问题。
生成方式如算法三所示,通过交换两个句子的位置来打乱源文档。

6.2.3.4 结果
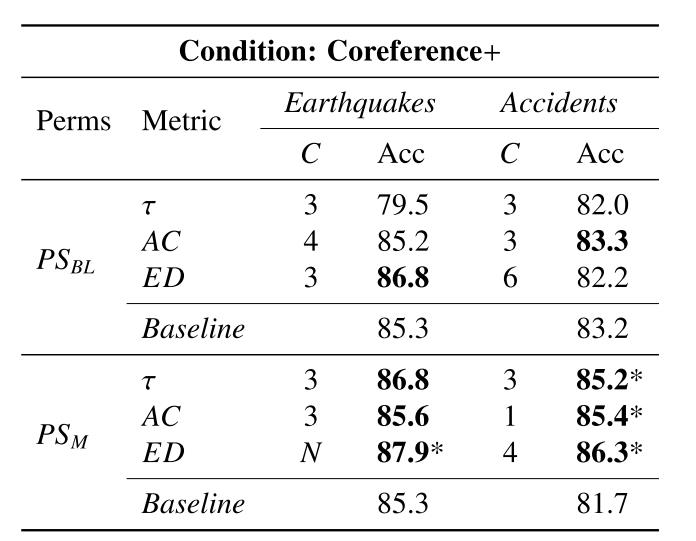
在这个任务中,我们使用两个分别包含200篇文章的数据集上进行,每篇文档最多20个重排序文档,使用的是SVM排序模型进行的。其中Acc指的是在测试集上的排序对。
首先是使用了同指信息和包含理想信息的模型
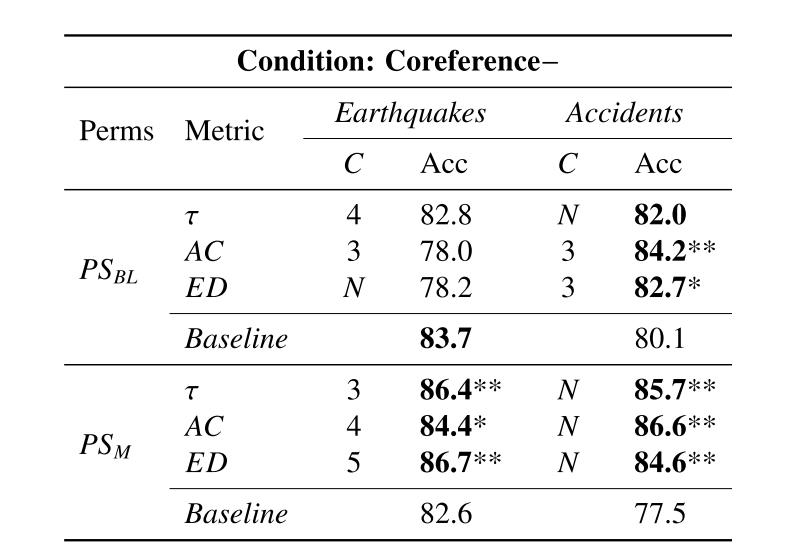
接下来是不使用同指信息的模型,可以看到其实性能上差不多了,尤其是使用了多重排序后的性能是好很多。
6.2.4 摘要连贯性
在摘要的连贯性评估任务中,我们处理了有系统生成和人工生成的多文档摘要。BL并没有在同一个文本中生成的摘要间进行一个二元区分。而是,他们通过人工评估每个摘要的连贯性并给出打分。因此,他们的模型已经学习到了不连贯的文档间微小差异。
然而我们想去看看我们是否可以通过我们计算的不相似性分数来替代人工评价,从而将原有的有监督学习转化为无监督学习来取得差不多的结果。然而,给定一个摘要,直接计算它的不相似分数有点不现实,因为我们并不知道它的真实句子顺序。为了解决这个问题,我们使用了一个简单的句子对齐方法在系统生成和人工生成通过输入同一个文章集合。给定一个系统生成的摘要Ds,以及人工生成的摘要Dh。我们将Dh中的句子顺序看作是
σ
\\sigma
σ,基于Ds计算其
π
\\pi
π.我们从Dh中找到醉相思的句子Sh。如果Dh中所有的句子的相似度都是0,那么将其顺序置为-1。一旦
π
\\pi
π知道了,我们就能够计算其不相似度。但是由于
π
\\pi
π还没有被声称为
σ
\\sigma
σ的一个排列,因此没有办法用肯德尔系数。
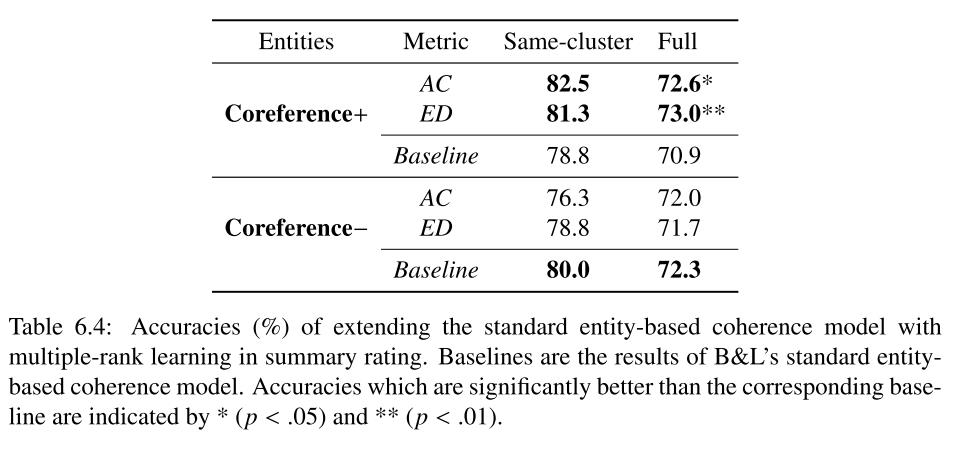
6.2.4.1 结果
正如之前所讲的那样,我们通过一个简单的句子对齐方法将系统生成的摘要和与其对应的人类生成的摘要对气候获得测试序列,并计算其与参考序列的不相似性。这样的话,我们将BL的有监督学习转换为了无监督学习。我们也使用了和BL相同的数据集。
在这个实验中,我们只考虑AC和ED两个评分标准,并且使用的是完整的排序。
以上是关于分析的应用(RST-style discourse parsing and its applications in discourse analysis)的主要内容,如果未能解决你的问题,请参考以下文章