MySql学习 —— 子查询(wherefromexists) 及 连接查询(left joinright joininner joinunion join)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySql学习 —— 子查询(wherefromexists) 及 连接查询(left joinright joininner joinunion join)相关的知识,希望对你有一定的参考价值。
同样的,使用goods表来练习子查询,表结构如下:
所有数据(cat_id与category.cat_id关联):
类别表:
mingoods(连接查询时作测试)

一、子查询
1、where型子查询:把内层查询的结果作为外层查询的比较条件
1.1 查询id最大的一件商品(使用排序+分页实现)
:mysql> SELECT goods_id,goods_name,shop_price FROM goods ORDER BY goods_id DESC LIMIT 1;

1.2 查询id最大的一件商品(使用where子查询实现)
:mysql> SELECT goods_id,goods_name,shop_price FROM goods WHERE goods_id = (SELECT MAX(goods_id) FROM goods);

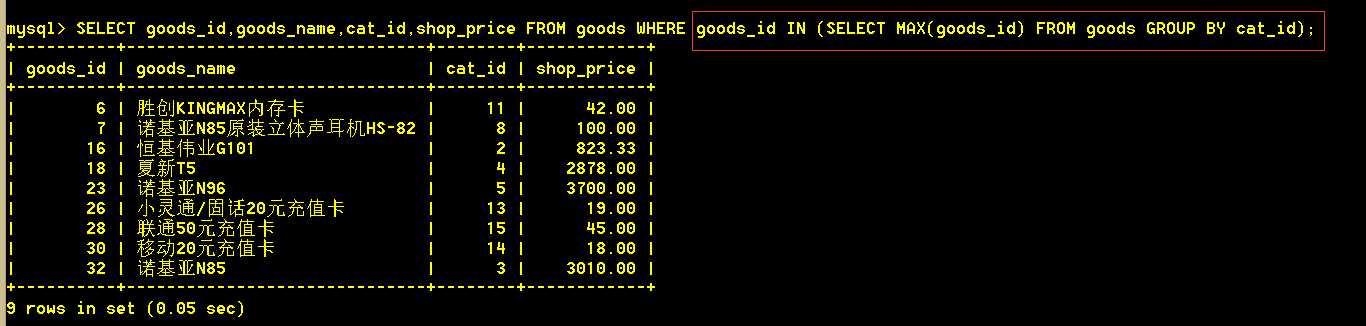
1.3 查询每个类别下id最大的商品(使用where子查询实现)
:mysql> SELECT goods_id,goods_name,cat_id,shop_price FROM goods WHERE goods_id IN (SELECT MAX(goods_id) FROM goods GROUP BY cat_id);
2、from型子查询:把内层的查询结果当成临时表,供外层sql再次查询。查询结果集可以当成表看待。临时表要使用一个别名。
2.1 查询每个类别下id最大的商品(使用from型子查询)
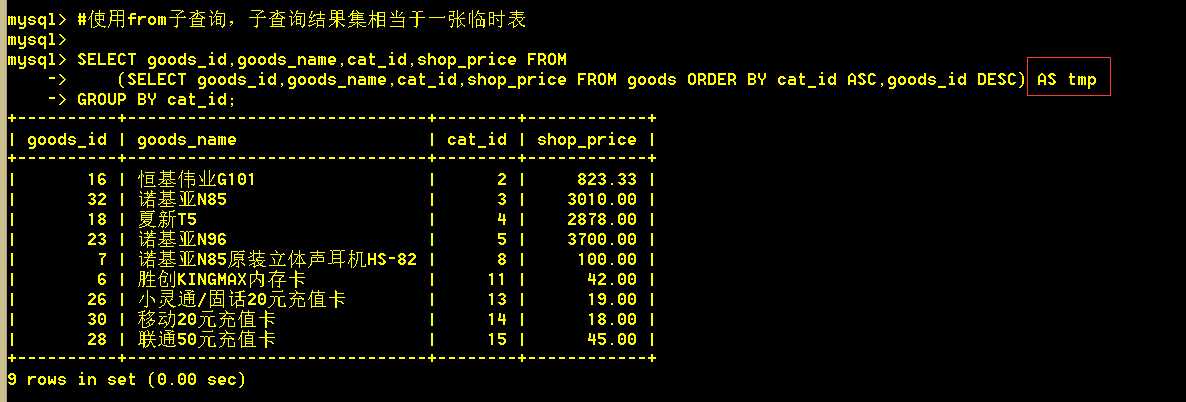
:mysql > SELECT goods_id,goods_name,cat_id,shop_price FROM
-> (SELECT goods_id,goods_name,cat_id,shop_price FROM goods ORDER BY cat_id ASC,goods_id DESC) AS tmp
-> GROUP BY cat_id;
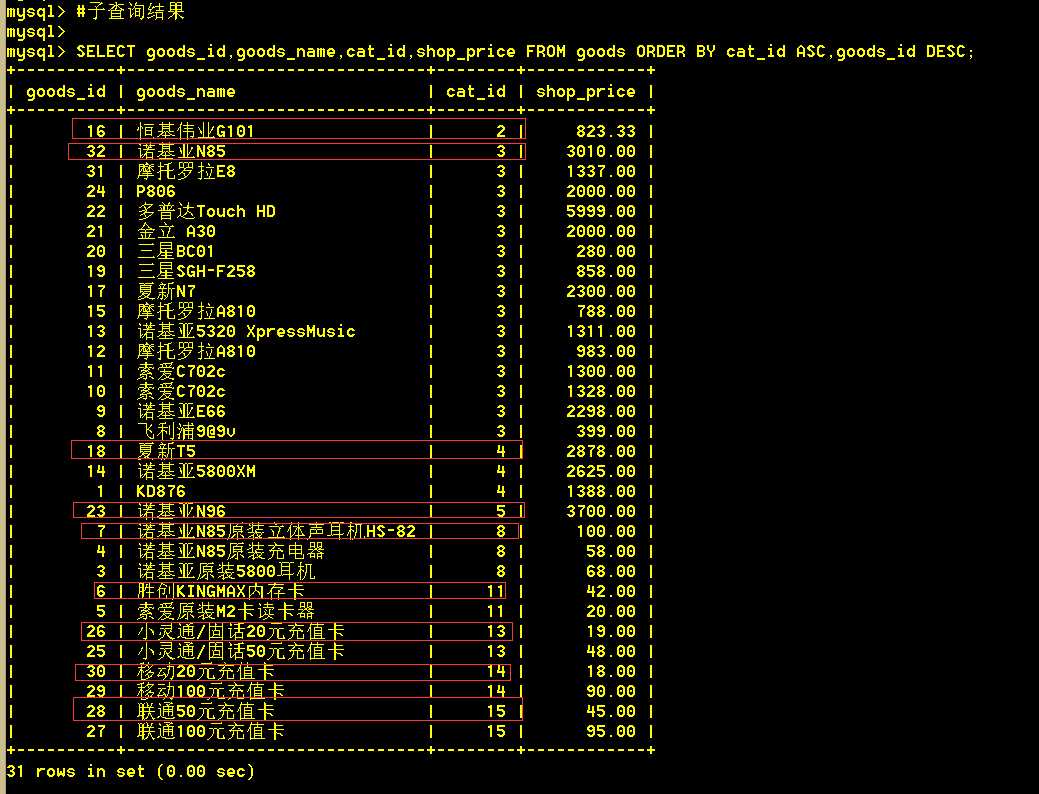
子查询查出的结果集看第二张图,可以看到每个类别的第一条的商品id都为该类别下的最大值。然后将这个结果集作为一张临时表,巧妙的使用group by 查询出每个类别下的第一条记录,即为每个类别下商品id最大。
3.exists型子查询:把外层sql的结果,拿到内层sql去测试,如果内层的sql成立,则该行取出。内层查询是exists后的查询。
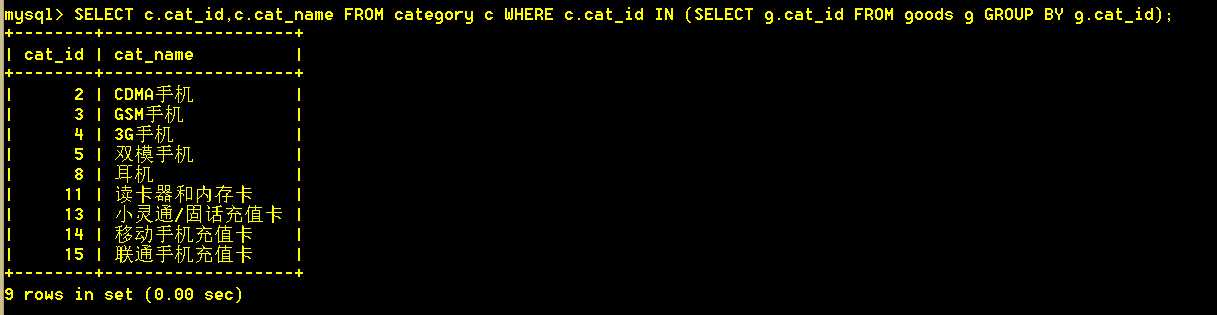
3.1 从类别表中取出其类别下有商品的类别(如果该类别下没有商品,则不取出),[使用where子查询]
:mysql> SELECT c.cat_id,c.cat_name FROM category c WHERE c.cat_id IN (SELECT g.cat_id FROM goods g GROUP BY g.cat_id);
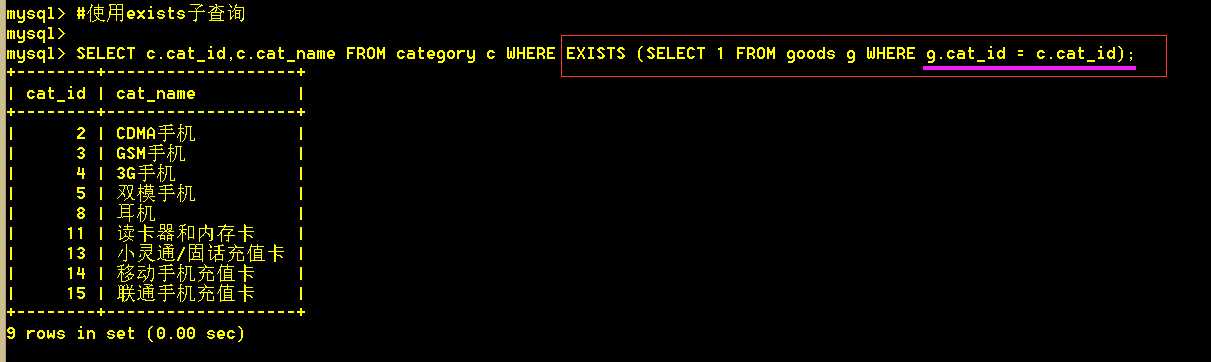
3.2 从类别表中取出其类别下有商品的类别(如果该类别下没有商品,则不取出),[使用exists子查询]
:mysql> SELECT c.cat_id,c.cat_name FROM category c WHERE EXISTS (SELECT 1 FROM goods g WHERE g.cat_id = c.cat_id);
exists子查询,如果exists后的内层查询能查出数据,则表示存在;为空则不存在。
4. any, in 子查询

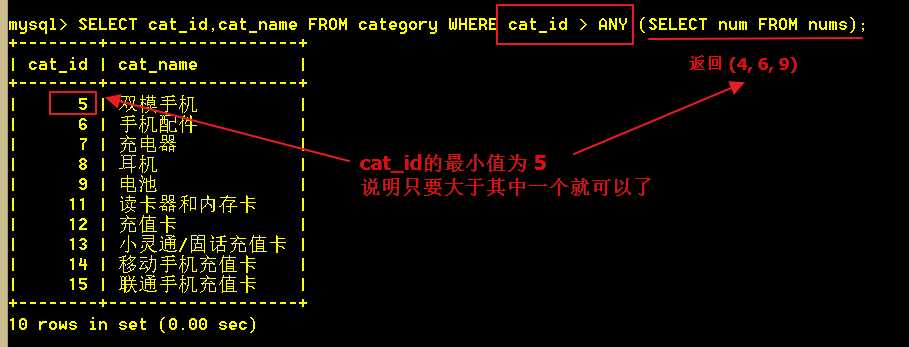
4.1 使用 any 查出类别大于任何一个num值的类别。
ANY关键词必须后面接一个比较操作符。ANY关键词的意思是“对于在子查询返回的列中的任一数值,如果比较结果为TRUE的话,则返回TRUE”。
:mysql> SELECT cat_id,cat_name FROM category WHERE cat_id > ANY (SELECT num FROM nums);
4.2 使用 in 查出cat_id 等于num的类别
:mysql> SELECT cat_id,cat_name FROM category WHERE cat_id IN (SELECT num FROM nums);
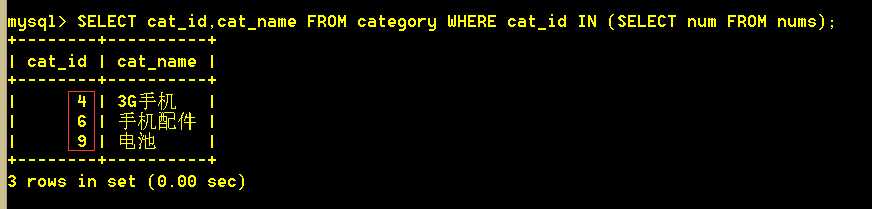
4.3 in 的效果 跟 =any 的效果是一样的。

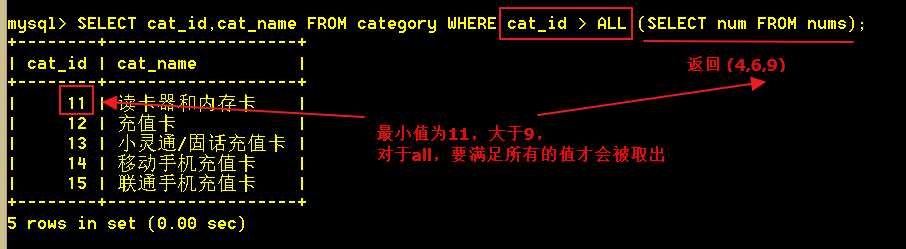
4.4 使用 all 查询
词语ALL必须接在一个比较操作符的后面。ALL的意思是“对于子查询返回的列中的所有值,如果比较结果为TRUE,则返回TRUE。”
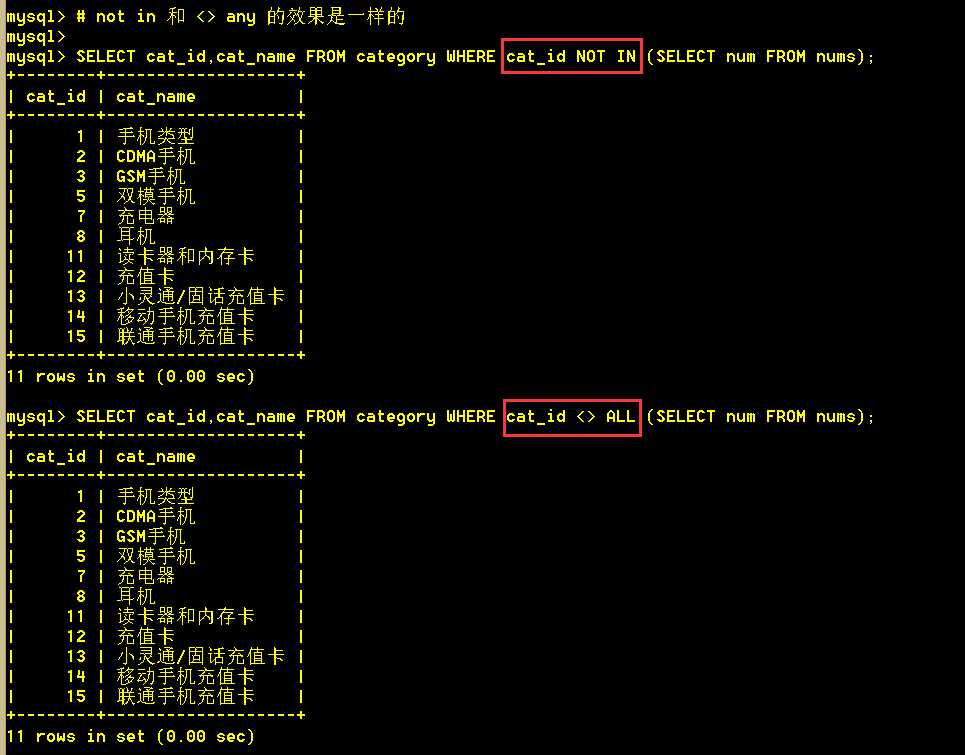
4.5 not in 和 <> any 的效果是一样的
NOT IN不是<> ANY的别名,但是是<> ALL的别名
子查询总结:
1. where型子查询:把内层查询的结果作为外层查询的比较条件。
from型子查询:把内层的查询结果当成临时表,供外层sql再次查询。查询结果集可以当成表看待,临时表需要一个别名。
exists型子查询:把外层sql的结果,拿到内层sql去测试,如果内层的sql成立,则该行取出。内层sql是exists后的查询。
2. 子查询也可以嵌套在其它子查询中,嵌套程度可以很深。子查询必须要位于圆括号中。
3. 子查询的主要优势为:
子查询允许结构化的查询,这样就可以把一个语句的每个部分隔离开。
有些操作需要复杂的联合和关联。子查询提供了其它的方法来执行这些操作。
4. ANY关键词必须后面接一个比较操作符。ANY关键词的意思是“对于在子查询返回的列中的任一数值,如果比较结果为TRUE的话,则返回TRUE”。
词语 IN 是 =ANY 的别名,二者效果相同。
NOT IN不是 <> ANY 的别名,但是是 <> ALL 的别名。
5. 词语ALL必须接在一个比较操作符的后面。ALL的意思是“对于子查询返回的列中的所有值,如果比较结果为TRUE,则返回TRUE。”
6. 优化子查询
①. 有些子句会影响在子查询中的行的数量和顺序,通过加一些限制条件来限制子查询查出来的条数。例如:
SELECT * FROM t1 WHERE t1.column1 IN (SELECT column1 FROM t2 ORDER BY column1);
SELECT * FROM t1 WHERE t1.column1 IN (SELECT DISTINCT column1 FROM t2);
SELECT * FROM t1 WHERE EXISTS (SELECT * FROM t2 LIMIT 1);
②. 用子查询替换联合。例如:
SELECT DISTINCT column1 FROM t1 WHERE t1.column1 IN (SELECT column1 FROM t2);
代替这个:SELECT DISTINCT t1.column1 FROM t1, t2 WHERE t1.column1 = t2.column1;
二、连接查询
学习连接查询,先了解下"笛卡尔积",看下百度给出的解释:

在数据库中,一张表就是一个集合,每一行就是集合中的一个元素。表之间作联合查询即是作笛卡尔乘积,比如A表有5条数据,B表有8条数据,如果不作条件筛选,那么两表查询就有 5 X 8 = 40 条数据。
先看下用到的测试表基本信息:我们要实现的功能就是查询商品的时候,从类别表将商品类别名称关联查询出来。
行数:类别表14条,商品表4条
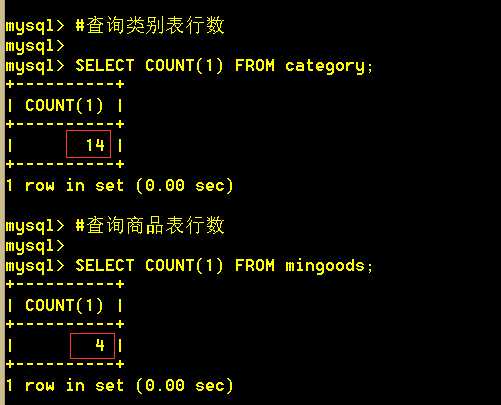
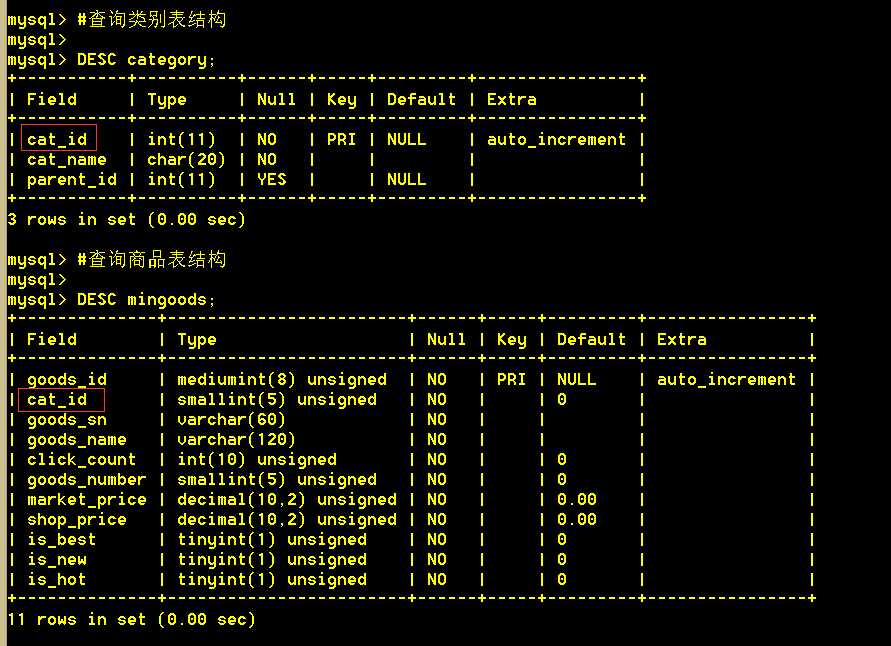
结构:商品表和类别表都有一个cat_id
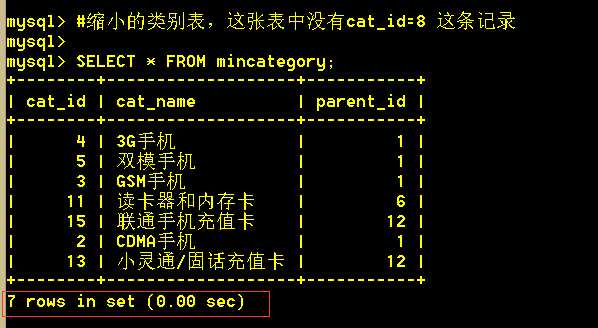
小类别表(左右连接时做对比)
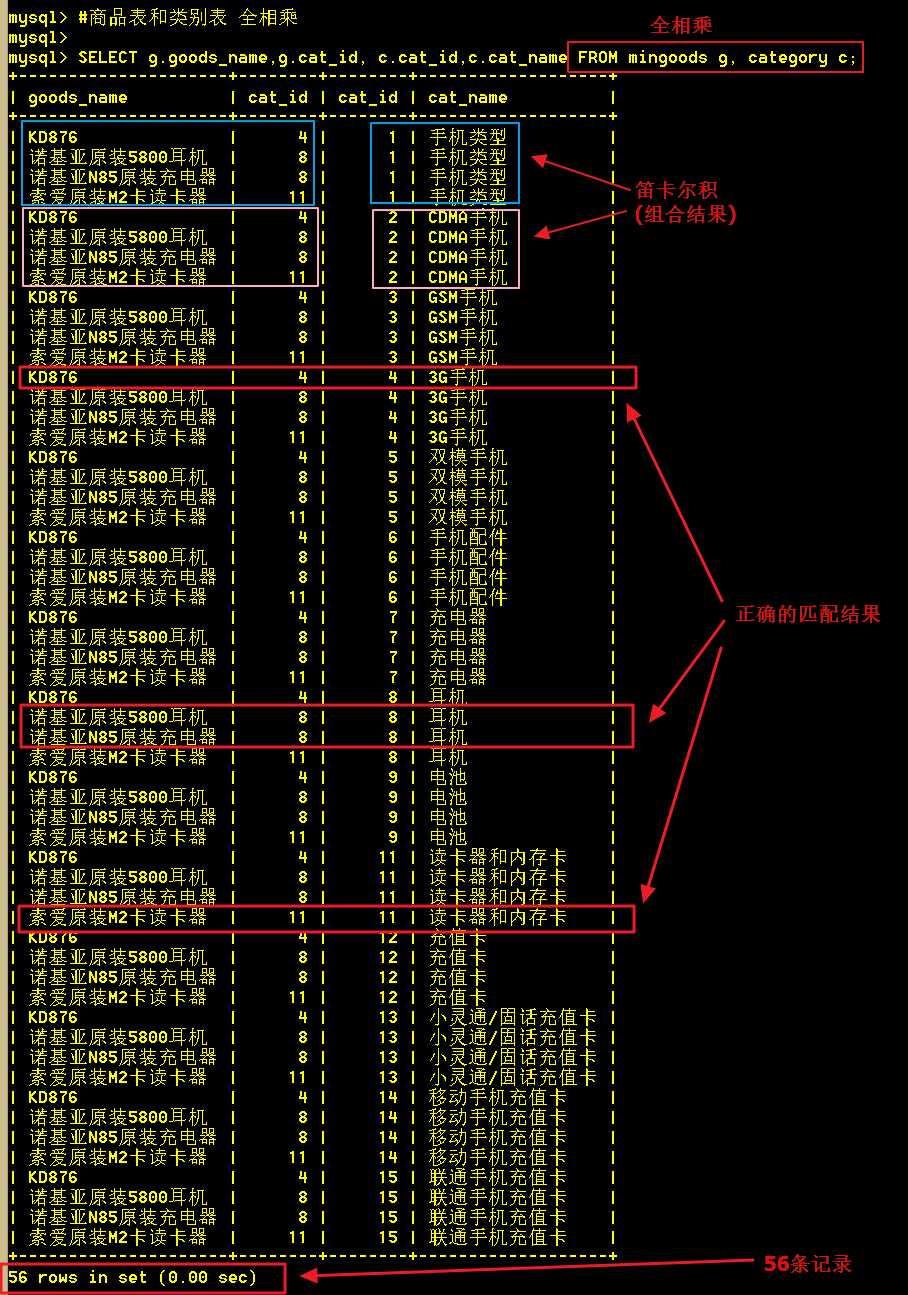
1.全相乘(不是全连接、连接查询),全相乘是作笛卡尔积
两表全相乘,就是直接从两张表里查询;从查询的截图看出,总共查出了 4 X 14 = 56 条记录,这些记录是笛卡尔乘积的结果,即两两组合;
但我们要的是每个商品信息显示类别名称而已,这里却查出了56条记录,其中有52条记录都是无效的数据,全相乘的查询效率低。
:mysql> SELECT goods_id,goods_name,cat_name FROM mingoods,category;
如果在两张表里有相同字段,做联合查询的时候,要区别表名,否则会报错误(模糊不清)
:mysql> SELECT goods_name,cat_id,cat_name FROM mingoods,category;

添加条件,使两表关联查询,这样查出来就是商品和类别一一对应了。虽然这里查出来4条记录,但是全相乘效率低,全相乘会在内存中生成一个非常大的数据(临时表),因为有很多不必要的数据。
如果一张表有10000条数据,另一张表有10000条数据,两表全相乘就是100W条数据,是非常消耗内存的。而且,全相乘不能好好的利用索引,因为全相乘生成一张临时表,临时表里是没有索引的,大大降低了查询效率。
:mysql> SELECT g.goods_name,g.cat_id AS g_cat_id, c.cat_id AS c_cat_id, c.cat_name FROM mingoods g, category c WHERE g.cat_id = c.cat_id;

2.左连接查询 left join ... on ...
语法:select A.filed, [A.filed2, .... ,] B.filed, [B.filed4...,] from <left table> as A left join <right table> as B on <expression>
假设有A、B两张表,左连接查询即 A表在左不动,B表在右滑动,A表与B表通过一个关系来关联行,B表去匹配A表。
2.1先来看看on后的条件恒为真的情况
:mysql> SELECT g.goods_name,g.cat_id, c.cat_id ,c.cat_name FROM mingoods g LEFT JOIN category c ON 1;
跟全相乘相比,从截图可以看出,总记录数仍然不变,还是 4 X 14 = 56 条记录。但这次是商品表不动,类别表去匹配,因为每次都为真,所以将所有的记录都查出来了。左连接,其实就可以看成左表是主表,右表是从表。
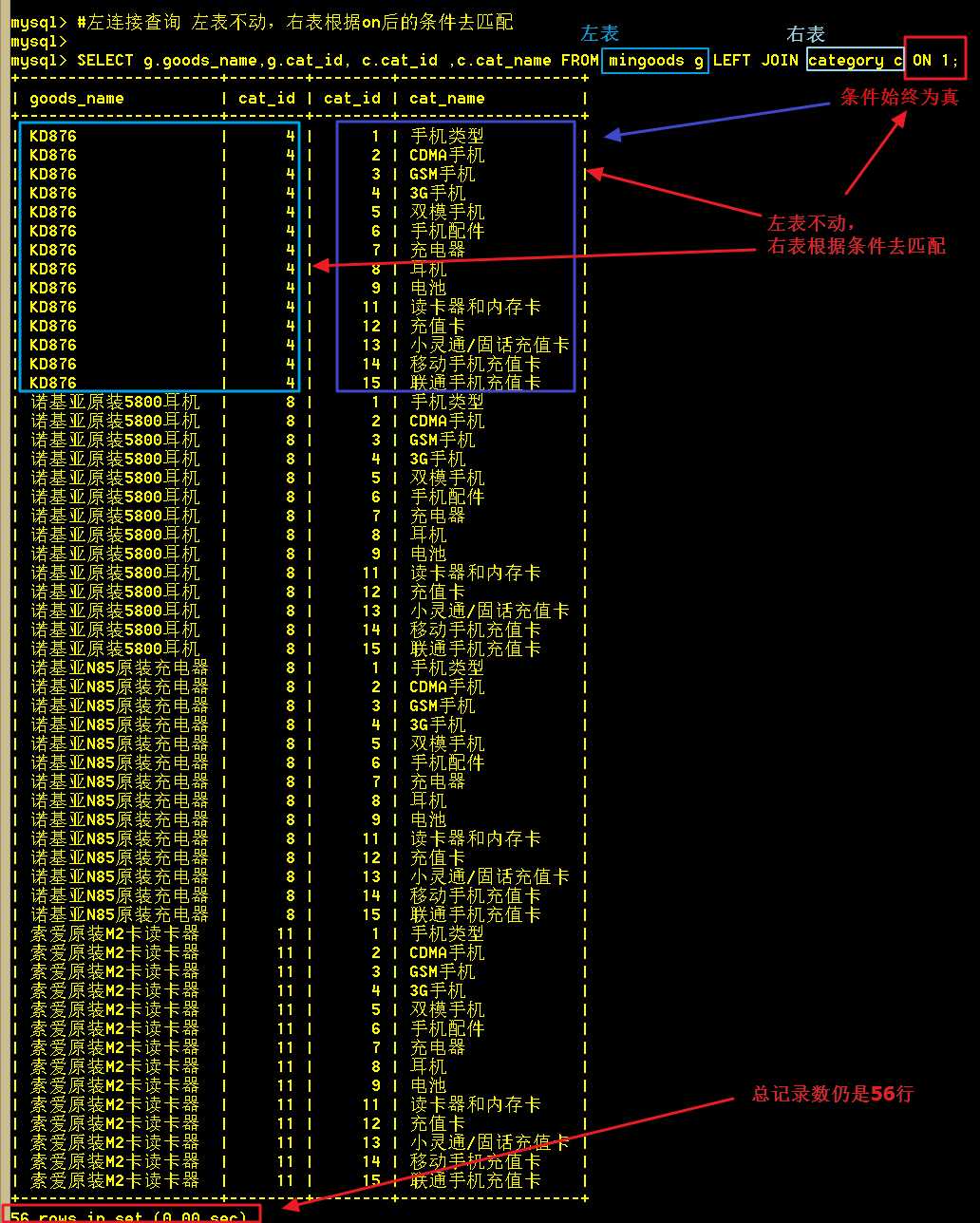
2.2 根据cat_id使两表关联行
:mysql> SELECT g.goods_name,g.cat_id,c.cat_id,c.cat_name FROM mingoods g LEFT JOIN category c ON g.cat_id = c.cat_id;
使用左连接查询达到了同样的效果,但是不会有其它冗余数据,查询速度快,消耗内存小,而且使用了索引。左连接查询效率相比于全相乘的查询效率快了10+倍以上。
左连接时,mingoods表(左表)不动,category表(右表)根据条件去一条条匹配,虽说category表也是读取一行行记录,然后判断cat_id是否跟mingoods表的相同,但是,左连接使用了索引,cat_id建立了索引的话,查询速度非常快,所以整体效率相比于全相乘要快得多,全相乘没有使用索引。

2.3 查询出第四个类别下的商品,要求显示商品名称
:mysql> SELECT g.goods_name,g.cat_id,c.cat_name,g.shop_price FROM goods g LEFT JOIN category c ON g.cat_id = c.cat_id WHERE g.cat_id = 4;

2.4 对于左连接查询,如果右表中没有满足条件的行,则默认填充NULL。
:mysql> SELECT g.goods_name,g.cat_id AS g_cat_id, c.cat_id AS c_cat_id,c.cat_id FROM mingoods g LEFT JOIN mincategory c ON g.cat_id = c.cat_id;

3.右连接查询 right join ... on ...
语法:select A.field1,A.field2,..., B.field3,B.field4 from <left table> A right join <right table> B on <expression>
右连接查询跟左连接查询类似,只是右连接是以右表为主表,会将右表所有数据查询出来,而左表则根据条件去匹配,如果左表没有满足条件的行,则左边默认显示NULL。左右连接是可以互换的。
:mysql> SELECT g.goods_name,g.cat_id AS g_cat_id, c.cat_id AS c_cat_id,c.cat_name FROM mingoods g RIGHT JOIN mincategory c ON g.cat_id = c.cat_id;

4. 内连接 inner join ... on ...
语法:select A.field1,A.field2,.., B.field3, B.field4 from <left table> A inner join <right table> B on <expression>
内连接查询,就是取左连接和右连接的交集,如果两边不能匹配条件,则都不取出。
:mysql> SELECT g.goods_name,g.cat_id, c.* from mingoods g INNER JOIN mincategory c ON g.cat_id = c.cat_id;

5. 联合查询 union
语法:select A.field1 as f1, A.field2 as f2 from <table1> A union (select B.field3 as f1, field4 as f2 from <table2> B)
union是求两个查询的并集。union合并的是结果集,不区分来自于哪一张表,所以可以合并多张表查询出来的数据。
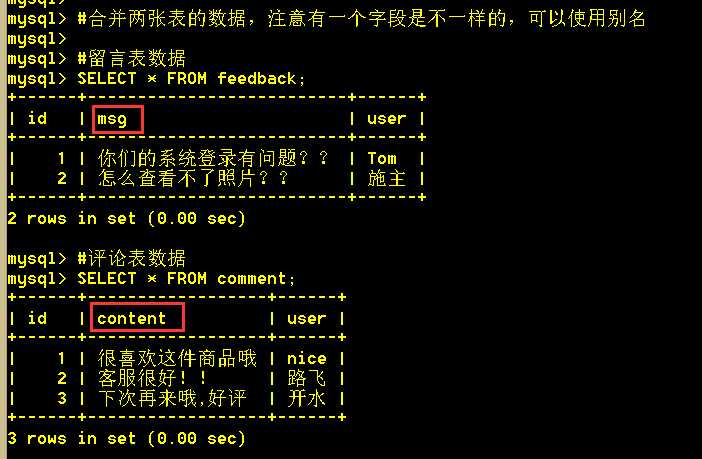
5.1 将两张表的数据合并查询出来
:mysql> SELECT id, content, user FROM comment UNION (SELECT id, msg AS content, user FROM feedback);
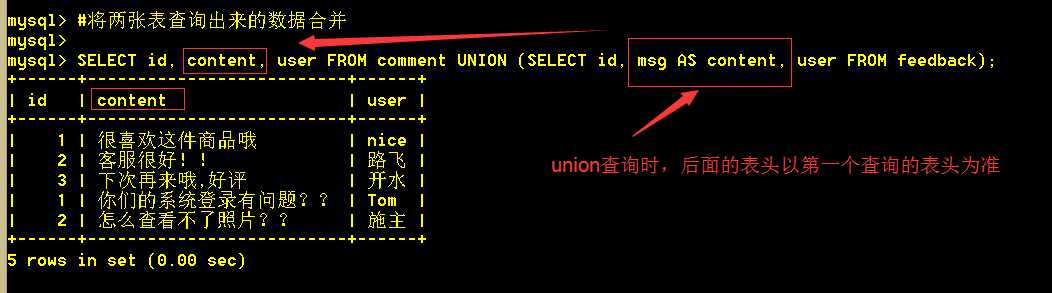
5.2 union查询,列名不一致时,以第一条sql语句的列名对齐
:mysql> SELECT id, content, user FROM comment UNION (SELECT id, msg, user FROM feedback);
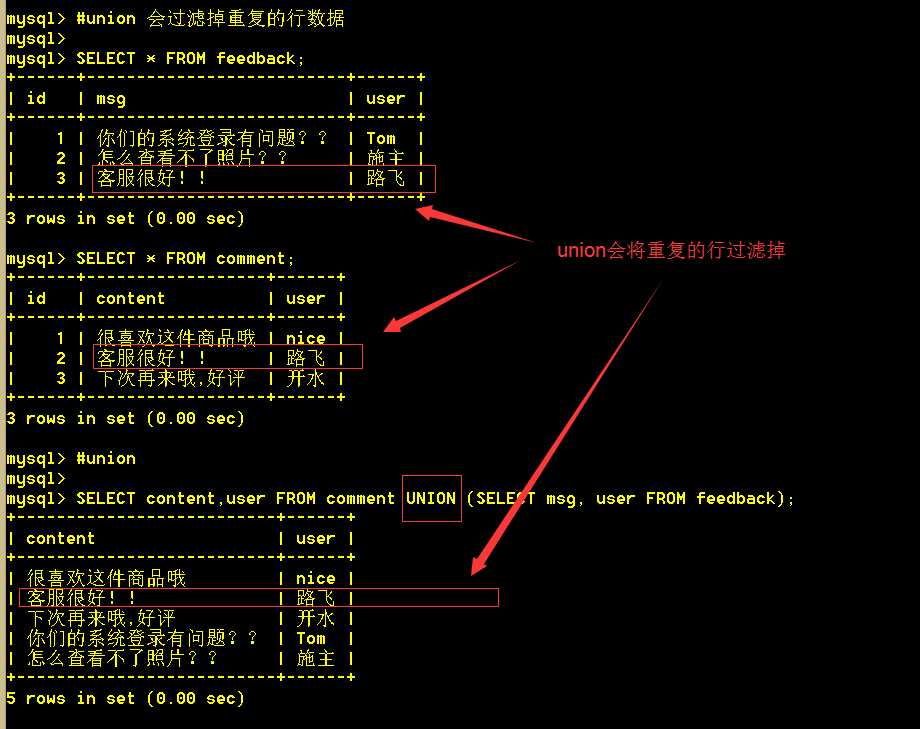
5.3 使用union查询会将重复的行过滤掉
:mysql> SELECT content,user FROM comment UNION (SELECT msg, user FROM feedback);
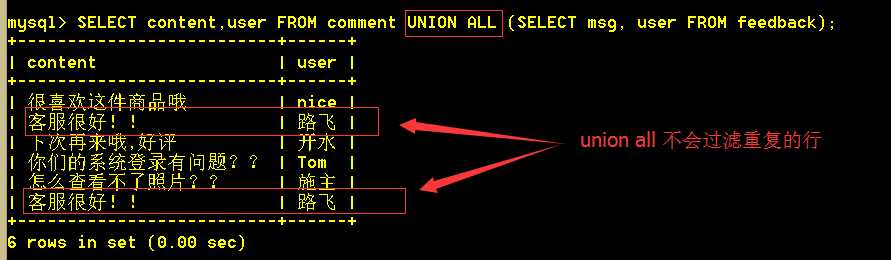
5.4 使用union all查询所有,重复的行不会被过滤
:mysql> SELECT content,user FROM comment UNION ALL (SELECT msg, user FROM feedback);
5.5 union查询,如果列数不相等,会报列数不相等错误

5.6 union 后的结果集还可以再做筛选
:mysql> SELECT id,content,user FROM comment UNION ALL (SELECT id, msg, user FROM feedback) ORDER BY id DESC;
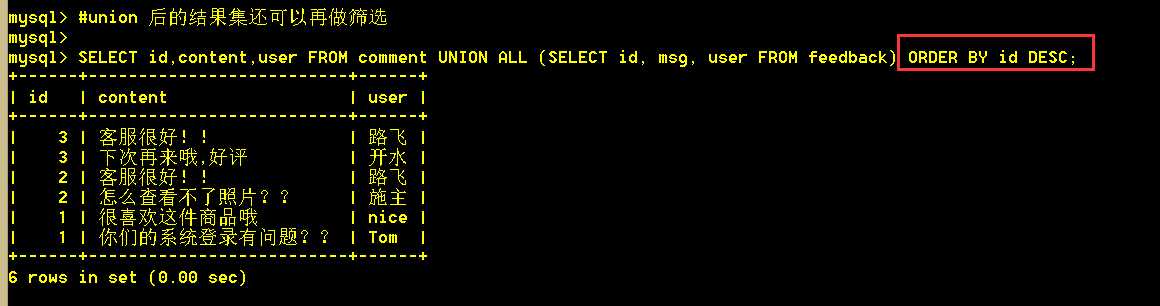
union查询时,order by放在内层sql中是不起作用的;因为union查出来的结果集再排序,内层的排序就没有意义了;因此,内层的order by排序,在执行期间,被mysql的代码分析器给优化掉了。
:mysql> (SELECT id,content,user FROM comment ORDER BY id DESC) UNION ALL (SELECT id, msg, user FROM feedback ORDER BY id DESC);

order by 如果和limit一起使用,就显得有意义了,就不会被优化掉
mysql> ( SELECT goods_name,cat_id,shop_price FROM goods WHERE cat_id = 3 ORDER BY shop_price DESC LIMIT 3 )
-> UNION
-> ( SELECT goods_name,cat_id,shop_price FROM goods WHERE cat_id = 4 ORDER BY shop_price DESC LIMIT 2 );

5.7 练习
:mysql> SELECT name, SUM(money) FROM ( ( SELECT * FROM A ) UNION ALL ( SELECT * FROM B ) ) tmp GROUP BY name;


连接查询总结:
1.在数据库中,一张表就是一个集合,每一行就是集合中的一个元素。连接查询即是作笛卡尔积,比如A表有1W条数据,B表有1W条数据,那么两表查询就有 1W X 1W = 100W 条数据
2.如果在两张表里有相同字段,做联合查询的时候,要区别表名,否则会报错误(ambiguous 模糊不清)
3.全相乘效率低,全相乘会在内存中生成一个非常大的数据(临时表),因为有很多不必要的数据。
如果一张表有10000条数据,另一张表有10000条数据,两表全相乘就是100W条数据,是非常消耗内存的。
而且,全相乘不能好好的利用索引,因为全相乘生成一张临时表,临时表里是没有索引的,大大降低了查询效率。
4.左连接查询时,以左表为主表,会将左表所有数据查询出来;左表不动,右表根据条件去一条条匹配,如果没有满足条件的记录,则右边返回NULL。
右连接查询值,以右表为主表,会将右表所有数据查询出来,右表不动,左表则根据条件去匹配,如果左表没有满足条件的行,则左边返回NULL。
左右连接是可以互换的:A left join B == B right join A (都是以A为主表) 。
左右连接既然可以互换,出于移植兼容性方面的考虑,尽量使用左连接。
5.连接查询时,虽说也是读取一行行记录,然后判断是否满足条件,但是,连接查询使用了索引,条件列建立了索引的话,查询速度非常快,所以整体效率相比于全相乘要快得多,全相乘是没有使用索引的。
使用连接查询,查询速度快,消耗内存小,而且使用了索引。连接查询效率相比于全相乘的查询效率快了10+倍以上。
6.内连接查询,就是取左连接和右连接的交集,如果两边不能匹配条件,则都不取出。
7.MySql不支持外连接,相应的,MySql可以用union(联合查询)来查出左连接和右连接的并集。
union查询会过滤重复的行,union all 不会过滤重复的行。
union查询时,union之间的sql列数必须相等,列名以第一条sql的列为准;列类型可以不一样,但没太大意义。
union查询时,order by放在内层sql中是不起作用的;因为union查出来的结果集再排序,内层的排序就没有意义了;因此,内层的order by排序,在执行期间,被mysql的代码分析器给优化掉了。
但是,order by 如果和limit一起使用,就显得有意义了,会影响最终结果集,就不会被优化掉。order by会根据最终是否会影响结果集而选择性的优化。
^_^
以上是关于MySql学习 —— 子查询(wherefromexists) 及 连接查询(left joinright joininner joinunion join)的主要内容,如果未能解决你的问题,请参考以下文章