Python spider Ajax抓包下载视频
Posted Adorable_Rocy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python spider Ajax抓包下载视频相关的知识,希望对你有一定的参考价值。
抓包的过程中,有一个很重要的信息,UA伪装,所有的请求头都需要我们注意,不可以遗漏信息
1.获取视频电影数据
- 首页
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/99.0.4844.82 Safari/537.36'
home_url = 'https://www.pearvideo.com/category_5'
#首页的page_text
home_page = requests.get(url=home_url,headers=headers).content
# 抓取初始界面
home_tree = etree.HTML(home_page)
# 视频下载地址
all_of_video_url = home_tree.xpath('//*[@id="listvideoListUl"]/li[@class="categoryem "]')
- 详情页
for li in all_of_video_url:
v_name = li.xpath('./div/a/div[2]/text()')[0] + '.mp4'
# 详情页界面
v_url = 'https://www.pearvideo.com/' + li.xpath('//div[@class="vervideo-bd"]/a/@href')[0]
v_page_text = requests.get(url=v_url,headers=headers).content
# 解析详情页
v_tree = etree.HTML(v_page_text)
- ajax视频请求:
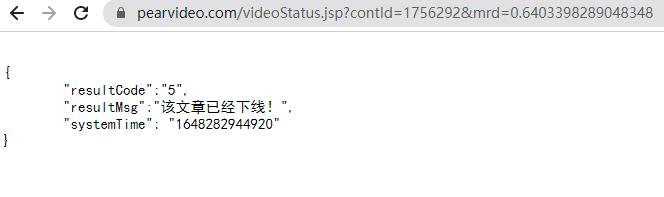
但是我们在请求的时候,发现并没什么用,显示文章已下线了,这是因为我们直接对其发出请求,所以会导致请求是无效的,因为不知道来源
- 手动发送请求
ajax_url = 'https://www.pearvideo.com/videoStatus.jsp?'
ajax_id = str(v_tree.xpath('//div[@class="video-tt-box"]//div[@class="fav"]/@data-id')[0])
# ajax请求头
ajax_headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36',
'Referer': 'https://www.pearvideo.com/video_' + ajax_id
ajax_param =
'contId': ajax_id,
'mrd': str(random.random())
# print(f'ajax_headers["Referer"],ajax_headers["User-Agent"],ajax_url')
ajax_json = requests.get(url=ajax_url,headers=ajax_headers,params=ajax_param).json()
# 根据json串 使用正则表达式来解析出来src地址
vitual_url = ajax_json["videoInfo"]["videos"]["srcUrl"]
# 真实地址
# https://video.pearvideo.com/mp4/short[xxxxx]/20220324/cont-1756292-10023871-230424-hd.mp4
print(vitual_url)
# 虚假地址
# https://video.pearvideo.com/mp4/third/20220324/1648264378624-10023871-230424-hd.mp4
# 替换
# 网址确实是会被替换。所以扩大范围
ex = '.*?/\\w5/1\\d8/(.*?)-'
word = re.findall(ex, vitual_url, re.S)[0]
v_real_url = re.sub(word, 'cont-' + ajax_id, vitual_url)
dic =
'name': v_name,
'url': v_real_url
load_urls.append(dic)
- 使用连接池多线程请求:
def get_video(dic):
v_url = dic['url']
v_name = dic['name']
print(v_name,'正在下载\\n')
v_content = requests.get(url=v_url,headers=headers).content
v_paht = './videoCollection/' + v_name
with open(v_paht,'wb') as fp:
fp.write(v_content)
print(v_name,'下载完成\\n')
pool = Pool(4)
pool.map(get_video,load_urls)
pool.close()
- 下载完毕

以上是关于Python spider Ajax抓包下载视频的主要内容,如果未能解决你的问题,请参考以下文章