[机器学习] Coursera笔记 - 机器学习应用的建议-Part2
Posted WangBo_NLPR
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[机器学习] Coursera笔记 - 机器学习应用的建议-Part2相关的知识,希望对你有一定的参考价值。
序言
机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,包括在线课程或Tutorial的学习笔记,论文资料的阅读笔记,算法代码的调试心得,前沿理论的思考等等,针对不同的内容会开设不同的专栏系列。
机器学习是一个令人激动令人着迷的研究领域,既有美妙的理论公式,又有实用的工程技术,在不断学习和应用机器学习算法的过程中,我愈发的被这个领域所吸引,只恨自己没有早点接触到这个神奇伟大的领域!不过我也觉得自己非常幸运,生活在这个机器学习技术发展如火如荼的时代,并且做着与之相关的工作。
写博客的目的是为了促使自己不断总结经验教训,思考算法原理,加深技术理解,并锻炼自己的表述和写作能力。同时,希望可以通过分享经验帮助新入门的朋友,结识从事相关工作的朋友,也希望得到高人大神的批评指正!
前言
[机器学习] Coursera笔记系列是以我在Coursera上学习Machine Learning(Andrew Ng老师主讲)课程时的笔记资料加以整理推出的。内容涵盖线性回归、逻辑回归、Softmax回归、SVM、神经网络和CNN等等,主要学习资料来自Andrew Ng老师在Coursera的机器学习教程以及UFLDL Tutorial,Stanford CS231n等在线课程和Tutorial,同时也参考了大量网上的相关资料。
本篇博客主要整理自“Advice for Applying Machine Learning”课程的笔记资料,包括假设函数的评估、数据集划分、模型选择问题、偏差和方差,以及机器学习诊断法等方面,涵盖了大量的器学习应用的建议和技巧。
同时,我也会将自己在机器学习算法应用中的经验分享出来,供大家参考。
文章小节安排如下:
1)如何评价一个模型(Evaluating a Hypothesis)
2)欠拟合与过拟合(Underfit and Overfit)
3)模型选择与数据集划分(Model Selection and Train/Validation/Test Sets)
4)如何诊断一个机器学习算法(How to diagnose a algorithm)
5)如何调试一个机器学习算法(How to debug a algorithm)
6)误差分析(Error Analysis)
7)偏斜类问题(Skewed Classes)
8)查全和查准的权衡(Trading Off Precision and Recall)
9)数据的重要性(Importance of Data)
10)最后的总结
这是第二篇,前两篇请参考:
机器学习应用的建议与方法1
机器学习应用的建议与方法3
机器学习算法的应用其实是个经验活儿,靠的是日积月累的不断试错和积累。课程里Ng给出了机器学习算法应用中常用的准则、技巧和建议,不过想要全面理解和掌握这些建议,需要反复练习。
四、如何诊断一个机器学习算法(How to diagnose a algorithm)
调试学习型算法的时候千万不能想当然,比如在缺少正确全面评估的情况下就去开展数据收集工作,或者设计更多的特征等等,这些工作都可以扩展成为一个很大的项目,花费半年或者一年的时间,但事实上我们并不知道最后效果会是怎样的。
例如数据收集工作,根据我个人的经验,在利用学习型算法解决问题时,收集整理数据的时间差不多占了全部任务时间的一半(这并不夸张)。所以通常我会找到一小部分数据去快速实现一个算法系统,然后找到这个系统的瓶颈所在,是数据不足,还是模型能力不够等等,然后再针对性的开展工作。
事实上通过前面的讲述可以发现,如果一个学习算法表现不理想,那么多半是两种原因,要么是欠拟合(偏差比较大),要么是过拟合(方差比较大)。
这里又提出了偏差(bias)和方差(variance)的概念,Ng老师的课程里并没有展开分析机器学习背景下的偏差与方差问题,也许是假定各位童鞋的数学基础都很好……我们在统计学中都学过偏差与方差的概念和公式,一张图解释如下:

简单来说, 在统计学上,偏差反映了预测值偏离实际值的程度;偏差反映了预测值的离散程度。这里我暂时不对偏差与方差问题作深入的讨论,以后会专门撰写相关的博客详细分析机器学习背景下的偏差与方差问题。这里我们只要明确一点即可,在机器学习上,偏差与方差问题的研究对象是假设函数(也可以说是模型)。
4.1 诊断曲线(Diagnostic curve)
诊断曲线反映的是训练误差、验证误差随着多项式次数 d 改变或正则化参数 λ 改变的变化趋势,针对的是假设函数复杂度、正则化参数lambda选择问题。
首先我们来看如何用诊断曲线来选择最合适的多项式次数(假设我们在训练一个回归模型),还是用图来说明问题:

如图所思,一开始 d 较小,对应着一个比较大的训练集误差和验证集误差,随着增大多项式的次数,我们将对训练集拟合得越来越好,同时验证集误差也逐渐下降。但是随着 d 进一步变大,训练集误差仍然是在继续减小,可验证集误差就会开始变大,说明我们过拟合了。
是不是很容易? 多项式次数 d 与训练误差和验证误差的曲线,可以很好的反映出在当前训练样本集下,多项式次数d对模型欠拟合和过拟合的影响,同时可以选出最合适的 d。
同理,我们可以诊断正则化参数 λ 对模型的影响,进而找到最合适的 λ 。
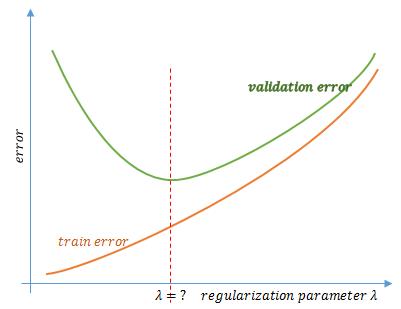
关于正则化参数 λ 对模型的影响,展开来也可以讲很多,后面会专门开辟章节进行分析。
4.2 学习曲线(Learning curve)
学习曲线反映的是训练误差、验证误差随着训练样本数量 m 改变的变化趋势,针对的是假设函数参数选择问题。使用学习曲线可以很方便的判断某一个学习算法是否处于偏差问题/方差问题/或是二者皆有。
为何要分为曲线诊断曲线和学习曲线?统一称为学习曲线或者诊断曲线不行么?其实我认为是可以的,不过样本数量对模型的影响和分析更复杂一些,所以单独拿出来分析。

如图所示,曲线反映出:在当前多项式次数和正则化参数下,训练样本数量 m 对模型欠拟合和过拟合的影响。但问题是,你没法确定说某个 m 值是最优的,事实上这也没有太大意义。
从上图中可以看出, 随着训练数据量的增加,训练集误差和验证集误差都会随之减小,因为使用的数据越多,越能获得更好的泛化表现或者说对新样本的适应能力更强,也就是说,数据越多越能拟合出合适的模型。
那问题就来了,利用学习曲线,如何判断模型处于高偏差(欠拟合)还是高方差(过拟合)?
模型处于高偏差
如果一个模型处于高偏差(欠拟合)状态,那么它的学习曲线基本上应该呈现如下样子。

可以看出,如果模型处于高偏差,那么训练集误差曲线上升比较陡峭,噌地一下就上去了,同时验证误差下降的比较缓慢。 当训练样本数量达到或超过了特定的数值,训练误差和验证误差(其实也包括测试集误差)就趋于接近且不变,并且处于较高的误差值上(这也是高偏差的主要判断依据)。
多项式次数较低或者正则化参数过大等,都可能导致模型处于欠拟合(高偏差)状态。在高偏差情形中,当训练集误差和验证集误差趋于接近且不变时,可以得到最能拟合数据的那条曲线(虽然很差,但已经是此状态下最优的了)。
模型处于高方差
如果一个模型处于高方差(过拟合)状态,那么它的学习曲线差不多应该呈现如下样子。

可以看出,处于高方差的模型有两个特点,一个是训练误差相对较小,并且随样本数量增加的涨幅比较平缓;另一个是训练误差和验证误差差之间有一段明显的差距(即训练集误差很小,验证集误差很大)。
图中曲线图也反映出,随着训练集样本数量增加,训练误差和验证误差这两条学习曲线正在相互靠近,也就是说,训练集误差很可能会逐渐增大,而验证集误差则会持续下降。所以 在高方差的情形中使用更多的训练数据对改进算法的表现是有效果的。
新入门童鞋也许会问,为何模型过拟合时候增加训练样本是有效的呢?
首先要明确一点,增加训练样本的意思有两点:第一是增加样本的数量,第二是增加样本的多样性。举例来说,如果你一直给算法看黑猫,那算法可能永远都不会认识白猫;如果你只给算法看很少很少的白猫照片,那算法也可能无法形成对白猫完整的建模。所以训练样本的数量和多样性都很重要。
其实拟合的过程,就是模型复杂程度和数据复杂程度的博弈。
高偏差与高方差的差异
在高偏差和高方差的情况下,learning curves中的训练误差(Jtrain)和和验证误差(Jcv)最终都是趋于接近的,这说明了什么呢?两种接近形式又有什么差异呢?
在high bias中,Jcv和Jtrain较早的趋于接近,且处于一个较高的error值;
在high variance中,Jcv和Jtrain较晚才趋于接近,且处于一个较低的error值;
可以看出,学习算法的欠拟合和过拟合状态分析看似简单,但实则并不是那么容易判断,需要方法和经验。
4.3 诊断/学习曲线的运用
上面绘制的诊断曲线和学习曲线都是相当理想化的,但在实际应用中总会有噪声或其他干扰,导致绘制的曲线变得复杂。但总的来说,绘制曲线确实有助于看清学习算法是否处于高偏差、高方差、或二者皆有的情形。
下面看几个诊断曲线。
1)固定多项式次数和lambda,观察学习曲线
lambda=1
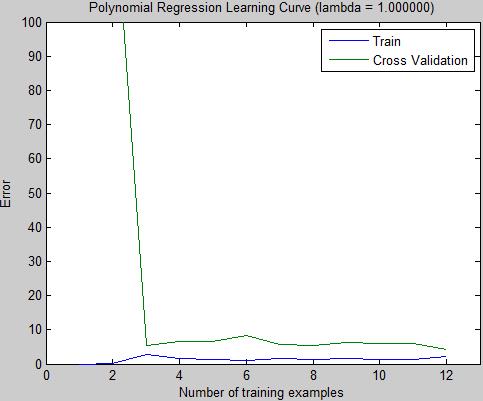
lambda=1100

2)固定多项式次数和样本数量,观察诊断曲线

是不是很崩溃,这些曲线拐弯交错,乍一看确实有点让人不知所措,但基本上还是可以分析的。
最后摘录Ng老师的良言。
诊断法提供了一系列测试方法和评价指标,通过执行这种测试能够深入了解某种算法是否有用,并且可以给出该算法改进的指导意见。
很多算法改进方法都可以扩展开来成一个六个月或更长时间的项目,遗憾的是大多数人都是在凭借感觉选择算法的改进方案,很多情况下最后他们都会很遗憾地发现自己选择的是一条不归路。
诊断方法的执行和实现需要花一些时间,因为这毕竟是一些额外的分析工作,但这样做的确可以更有效率地利用好你的时间,排除掉至少一半的改进措施,留下那些确实有前途的方法,让你在开发和改进学习算法时节省了几个月的时间,早点从不必要的尝试中解脱出来。
五、如何调试一个机器学习算法(How to debug a algorithm)
掌握了前面所说的机器学习算法诊断方法,接下来的问题就是算法的调试了,就像在编程中调试的概念一样,我们需要掌握一些方法套路来完善和改进算法。
5.1 常用算法调试方法
算法调试是一项复杂的、需要技巧的工作,也许你诊断出了算法处于过拟合状态,但你就是调不好……所以这是个经验活儿。但虽然经验很重要,但也有一些套路可用,总结一下无外乎以下几点。
1)增加训练样本
2)增加/减少特征
3)增加/减少多项式次数
4)增大/减小lambda
如果你发现模型处于欠拟合,你就选那些能够增加模型复杂度的方法;如果你发现模型处于过拟合,你就选可以降低或者平衡模型复杂度的方法。注意这里我用了“降低”和“平衡”两个词,减少特征项可以降低模型复杂度,增加训练样本可以平衡模型复杂度。
5.1 常用算法调试方法
正则化技术是通过正则化参数 λ 对参数 θ 进行惩罚或者说正则化,进而修正学习算法的高方差问题。本质上,正则化技术试图通过降低甚至去除假设函数中某些特征项(特征变量)的影响,进而平滑决策边界/拟合曲线,修正过拟合问题。
为何需要正则化技术?
在发生过拟合时,一种改进手段是弱化或者舍弃一些特征项,但是第一在成千上万的特征项中,我们没办法判断一个特征项的作用大小,也就没办法取舍;第二是每个特征项也许都对预测有那么一点点影响,我们不希望去掉任何任何一个。
于是这就导致了正则化概念的发生。正则化技术将保留所有的特征变量,但是会改变每个特征变量的权重大小,从而调整模型的拟合状态。
以下面的带正则化项的代价函数为例:

我们在代价函数中加上了红色的正则化项,这其实就是一种对参数的惩罚措施,λ 控制着对参数的惩罚力度。 正则化背后的思路就是,当我们加大对参数的惩罚(λ 设置较大使得参数都很小),就可以得到一个形式更加简单的模型,也就可以更好的避免过拟合。例如我们将 λ 设置为1000000,那么 h(θ) 的形式基本就是h(θ)=θ0,其他项几乎可以忽略不计了。
正则化与优化目标
让我们再从代价函数的角度来分析。当我们假如了正则化项,那么我们的优化目标就变成了两个,第一个是想要更好地拟合训练数据;第二个是想要保持参数值较小。因此,λ 的作用就是控制代价函数中两个不同目标之间的平衡关系。既要保证模型对训练数据有较好的拟合,也要保证参数值较小(模型形式相对简单)。
以上,就是对正则化技术的讲解。
5.3 模型选择的建议
我的建议是:复杂模型+正则化技术
为什么呢?因为过拟合时通过正则化技术来降低模型复杂度是比较简单的,而欠拟合时增加特征项或者增加多项式次数是比较麻烦的。通常我们都倾向于先选择一个看上去不错的模型,然后再做调整,而不是选择一个看上去就很差的模型。
以神经网络举例。当你在使用神经网络算法拟合数据的时候,
如果选择一个较简单的网络结构(隐藏单元比较少,甚至只有一个隐藏层,一个隐藏单元),那么该网络的参数就不会很多,很容易出现欠拟合,这种比较小型的神经网络最大优势在于计算量较小;
如果选择一个较大型的网络结构(要么隐藏层单元比较多,要么隐藏层比较多),那么该网络的参数一般较多,很容易出现过拟合,另外的一大劣势是计算量较大。
但事实上,你会发现越大型的网络性能越好,如果发生了过拟合,可以使用正则化技术来修正。一般来说,使用一个大型的神经网络并使用正则化来修正过拟合问题,通常比使用一个小型的神经网络效果更好,但主要的问题是计算量相对较大。
补充一点,在使用回归算法时,我们利用验证集去拟合多项式次数,那么在使用神经网络算法时,我们可以利用验证集去选择最合适的网络层数和每个隐层的节点数量。
六、误差分析(Error Analysis)
6.1 什么是误差分析
简单来说,误差分析就是对预测错误的样本进行分析,以发现某些系统性的规律。除了学习曲线,误差分析也是也是一种非常有用的方法,误差分析过程往往是可以发现模型预测错误的原因所在,能够启发我们如何改进当前的算法。
总结Ng老师在课程里的讲解:
对于一个机器学习问题,不同的机器学习算法所遇到的问题一般是相同的,也就是说,对于一种特征设计和一组训练样本,如果分类算法A出现了某些问题,那么分类算法B通常也会出现。
因此,对于一个机器学习问题,应该用一种简单快速的方法去实验,并手动分析一些错误的分类结果,找到一些错分的规律,错分样本的共同特点等,进而总结一些新的特征或改进分类器的设计。通过实践一些快速即便不完美的算法,我们能够更快地找到算法难以处理的例子,进而找到错误的根源所在,这样就能集中精力在真正的问题上。
6.2 如何应用误差分析
其实在分类算法中,也存在着类似二八原则的问题,也就是80%的样本是很好分类的,而20%的样本分类是非常困难的。还是说一下我本人在色情图像分类任务中的经验,就我们遇到的样本而言,有90%左右都是非常容易分类的,也就是要么是色情淫秽,要么是正常的。剩下的10%,那可就非常头疼了,需要根据具体的应用环境做处理,举例来说,光膀子男性是否是敏感的?裸体婴儿是否是敏感的?两条大长腿是否是敏感的?甚至是比基尼泳装是否是敏感的?这些案例在不同场景下的处理尺度是不一致的,需要具体问题具体分析。
但其实,很多客户也搞不清楚哪些样本是要屏蔽的,哪些是允许上传的,所以我们在研发算法时候,往往一开始只是训练一个基本准确的模型(误报会比较多,但很容易并且很快就能训练好),然后快速在客户那里部署测试,然后不断将误报的样本收集整理,跟客户一起进行误差分析,逐渐确定鉴定尺度,最终训练得到一个符合客户预期的分类模型。
从我个人经验来看,误差分析是比较繁琐的工作,你需要不断去测试样本分析误报样本总结规律。这很花精力,你也会觉得这很low,不上档次……但事实上,误差分析会带给你两个好处:
1)快速找到算法的短处所在;
2)让你成为领域专家;
不要觉得分析数据是很low的活儿,这是一个讲究理论结合实际的时代,如果你不解决实际问题,那么没人会觉得你很厉害。
参考资料
Coursera - Machine learning( Andrew Ng)
https://www.coursera.org/learn/machine-learning
End 机器学习应用的建议-Part2
以上是关于[机器学习] Coursera笔记 - 机器学习应用的建议-Part2的主要内容,如果未能解决你的问题,请参考以下文章