CUDA 学习寄存器用法
Posted tiemaxiaosu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CUDA 学习寄存器用法相关的知识,希望对你有一定的参考价值。
一、映射寄存器方式
CPU与GPU架构的一个主要区别就是CPU与GPU映射寄存器的方式。CPU通过使用寄存器重命名和栈来执行多线程。为了运行一个新的任务,CPU需要进行上下文切换,将当前所有寄存器的状态保存到栈(系统内存)上,然后从栈恢复当前需要执行的新线程上次的执行状态。这些操作通常需要花费上百个CPU时钟周期。如果在CPU上开启过多的线程,时间几乎都将花费在上下文切换过程中寄存器内容的切换进/换出操作上。因此,如果在CPU开启过多线程,有限工作的吞吐量将会快速降低。
然而,GPU却恰恰相反。GPU利用多线程隐藏了内存获取与指令执行带来的延迟。因此,在GPU上开启过少的线程反而会因为内存事务使GPU处于闲置状态。此外,GPU也不使用寄存器重命名的机制,而是致力于为每个线程分配真是寄存器。因此,当需要上下文切换时,所需要的操作就是将指向当前寄存器的选择器(或指针)更新,以指向下一个执行的线程束的寄存器,因此几乎零开销。
二、寄存器空间大小
由于所使用的硬件不同,每个SM可供所有线程使用的寄存器空间大小也不同,分布有8KB、16KB、32KB、64KB。牢记,每个线程中每个变量会占用一个寄存器。因此,C语言中的一个浮点型变量就会占用N个寄存器,其中N代表调度的线程数量。在费米架构的设备上,每个SM拥有32KB 的寄存器空间。如果每个线程块有256个线程,则每个线程可以使用32(32768/4/256)个寄存器。为了让费米架构的设备上的每个线程可以使用的寄存器数目达到最大,即64 个寄存器(G80及GT200上最多128个),每个线程块上的线程数目需要减少一半,即128。当线程块上的寄存器数目是允许的最大值时,每个SM会只处理一个线程块。同样,也可以使用四个线程块,每个线程块32个线程(4*32=128个线程),每个线程使用的寄存器数目也能达到最多。
三、SM调度线程块数目
大多数内核对寄存器的需求量都很低。如果将寄存器的需求量从128降到64,则相同的SM上可再调度一个线程块。例如需要32个寄存器,则可调度4个线程块。通过这样做,运行的线程总数可以提高。在费米型设备上,每个SM最多能运行1536个线程。一般情况下,占用率越高,程序运行就越快。
但是,每个SM能够调度的线程束的数量也是有限的。因此,将每个线程需要的寄存器数量从32降到16,并不意味着SM能调度8个线程块。如下表:
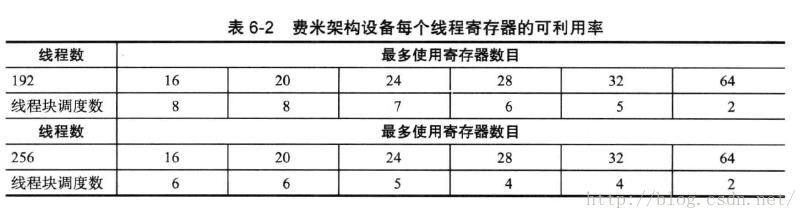
表6-2中测试设备为费米架构的设备。至于开普勒架构的设备,只需简单的将表中的寄存器数目与线程块数目加倍即可。此处使用192和256个线程进行测试是因为他们能够保证硬件的充分利用。注意当内核使用的寄存器的数目为16与20时,SM上调度的线程块的数目并没有增加,这是因为分配到每个SM上的线程的数量是有限的。在这种情况下,可以不考虑是否影响每个SM运行的线程总数而直接增加寄存器的使用量。
四、寄存器运用
将结果累积在寄存器中可省去大量的内存写操作。这种寄存器的优化方式可以使程序执行速度得到很大的提高。然而,这种优化方式需要程序员思考哪些参数是存于寄存器中,哪些参数是存于内存中,哪些参数需要从寄存器中复制回内存,等等。基于寄存器的优化能够为代码的执行时间带来巨大影响。使用寄存器可以有效消除内存访问,或提供额外的ILP,以此实现GPU内核函数的加速,这是最为有效的方法之一。
以上是关于CUDA 学习寄存器用法的主要内容,如果未能解决你的问题,请参考以下文章