YOLO系列YOLO V1 论文精读与学习总结
Posted SinHao22
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLO系列YOLO V1 论文精读与学习总结相关的知识,希望对你有一定的参考价值。
目录
0. 前言
最近一段时间在读YOLO系列的论文,目前跟着同济子豪兄读完了YOLO V1-V3的论文,真的有很大收获。跟着子豪兄读YOLO论文真是无痛啊!感谢子豪兄!!
目前的想法是把YOLO系列的论文精读完后对内容结构和重要知识点做总结,一方面是让自己理解得更深入,也方便以后快速回顾;另一方面也想和大家交流学习。

(图片来自:https://pjreddie.com/darknet/yolo/)
学习YOLO的过程真的很有趣,有很多优秀的资源,有前人摸索和踩坑,真的省了后人很多时间精力。YOLO V1-V3的作者Joseph Redmon是一个很有趣,喜欢皮一下的人。另外,当时他看到YOLO被用于军事领域以及可能被互连网大厂用于窃取个人隐私,就宣布退出计算机视觉了。这也是为什么YOLO V4和V5他没有参与研究。
YOLO V1是YOLO单阶段目标检测的开山鼻祖,所以好好读下YOLO V1的论文是非常有必要的!
接下来我会先介绍YOLO V1的大体思路,先在宏观上对YOLO V1有大体的认识;
然后我会从训练和预测推理两个方面来介绍YOLO V1,训练阶段主要是了解YOLO V1的主干网络结构、损失函数处理等,预测阶段主要是了解模型的NMS非极大值抑制后处理;
接着会介绍YOLO V1与其他优秀模型的比较,最后总结YOLO V1的优势和存在的不足,这些不足也是之后YOLO V2(YOLO 9000)的改进之处。
另外,所有的博客都是别人二次消化的产物,这里面会包含别人主观的看法,甚至还有不到位的理解。我也是刚刚入门目标检测领域,写该篇博客的目的主要是总结前段时间的学习。看博客也许可以帮助你对YOLO有更深入的理解,但作者的论文原文才是最好的学习资料(YOLO V3除外 - -||)。
论文原文:https://arxiv.org/pdf/1506.02640.pdf
1.YOLO V1 大体思路
目标检测的技术演进路线:

(图片来源:https://www.bilibili.com/video/BV1Vg411V7bJ?spm_id_from=333.999.0.0)
YOLO V1是单阶段目标检测,相较于之前的两阶段目标检测,它最大的特点就是快,因为它使用一个端到端的神经网络。
简单来说,它的大体思路是:输入一张448x448的图片,模型直接输出一个7x7x30的tensor,这个tensor中包含了目标的位置和种类信息,之后对这7x7x30的tensor进行后处理,NMS非极大值抑制,就得到了最终的结果(目标的位置和种类)。
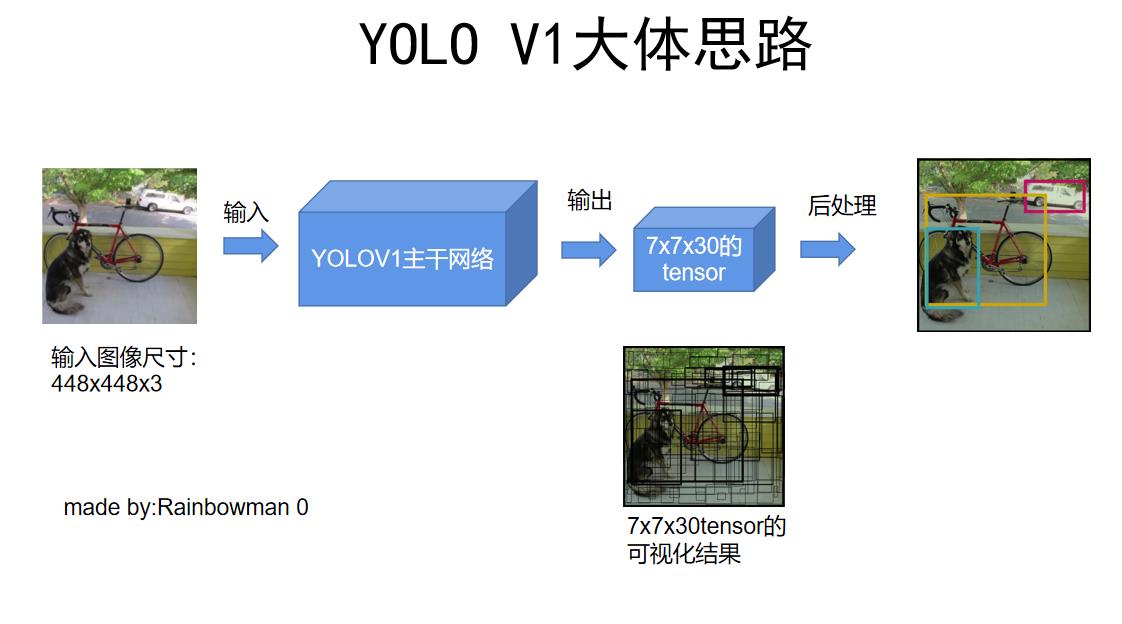
而且,YOLO V1在速度快的同时性能(mAP)也直逼当时的SOTA模型。
可以看看论文中的模型性能对比:

另外提一点,YOLO V1的输入尺寸需要固定。关于这点我的理解是:因为网络结构中没有使用全局平均池化层(GAP),而是把最后一层卷积层直接与全连接层相连,这就导致最后一层卷积层的神经元总数目必须固定,因此输入的图像尺寸也必须一致。YOLO V2就通过加入GAP,使得可以输入不同尺寸的图像。
2. YOLO V1的训练过程
2.1 YOLO V1网络结构
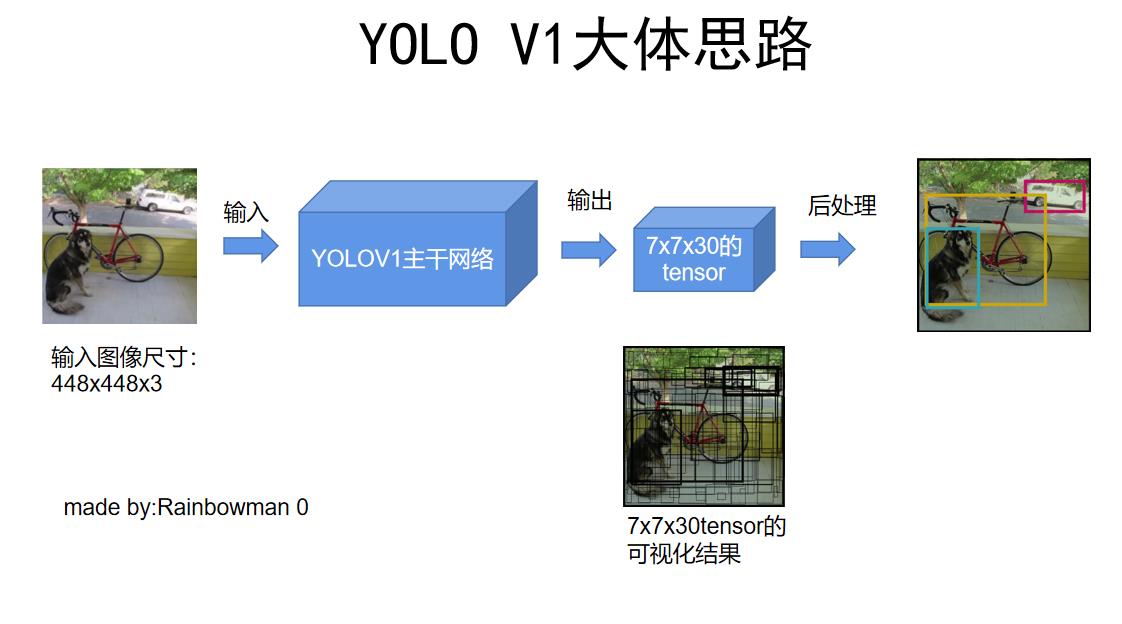
在这个图中,我们看到第一步是把448x448的RGB三通道图像输入了YOLOV1主干网络里,那么这个主干网络内部长什么样子呢?
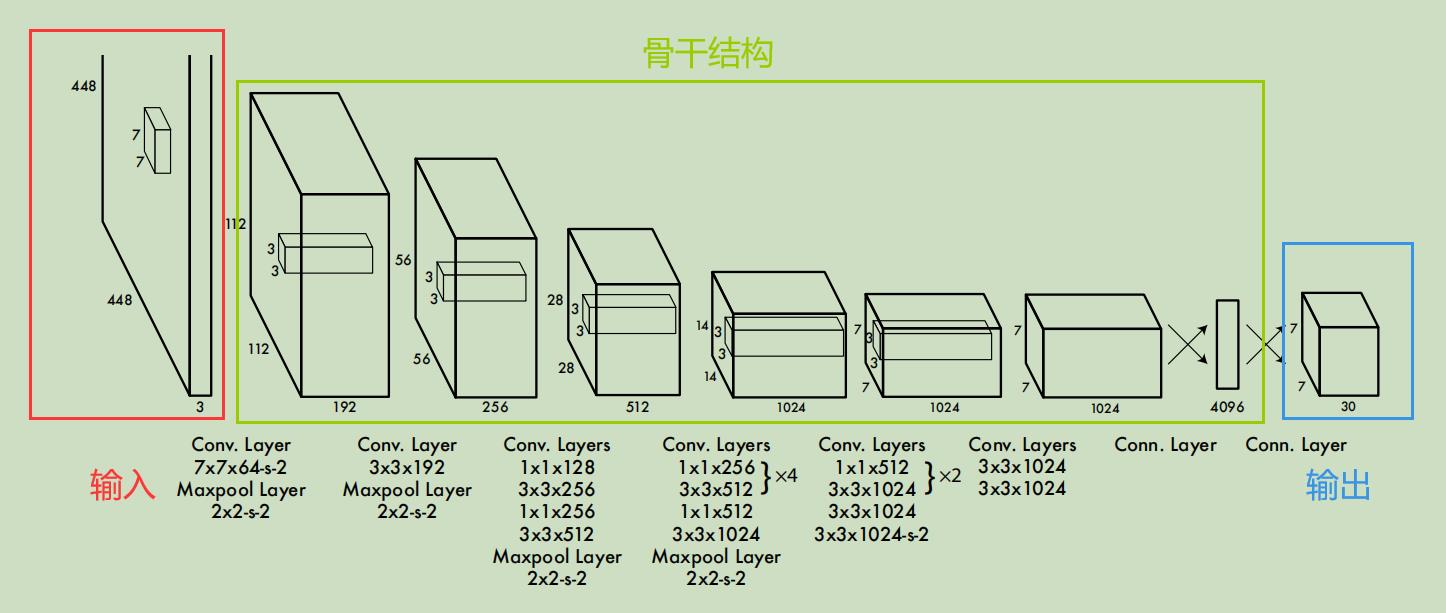
可以看到,一张448x448x3的图像输入网络后,经过了24层卷积层提取特征,最后经过两层全连接层,输出了7x7x30维的张量。这里解释下,其实最后两层的全连接层,倒数第二层有4096个神经元,这个可以从图中看出,而最后一层有7x7x30=1470个神经元,我们把这1470个神经元的全连接层再进行reshape,就得到了图中所画的7x7x30的长方体。至于为什么要画成7x7x30的长方体而不是有1470个神经元的长方形,这个会在“2.3 输出的7x7x30维张量代表含义”部分解释。
可以看出,该网络用了很多1x1的卷积核来进行降维处理,另外,根据论文所说,该网络除了最后一层用的是线性激活函数外,其余层均使用Leaky Relu激活函数。

2.2 具体训练过程
那么,了解了具体的网络结构,还需要知道作者是怎么训练这个网络的。因为具体的训练确实存在技巧的,我之前用TensorFlow搭了个网络结构随便一训练的效果确实很差。
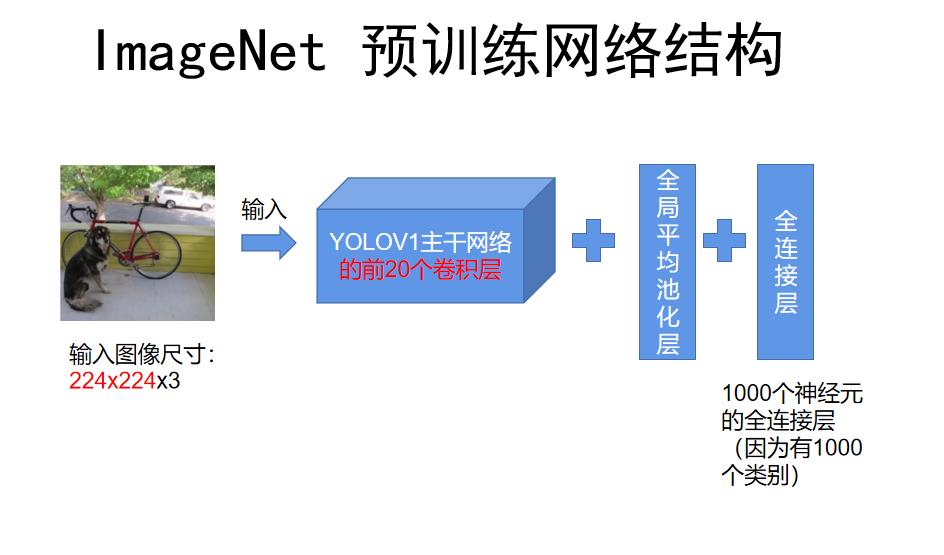
2.2.1 把主干结构在ImageNet上进行预训练
根据论文所说,作者首先拿出了网络结构的前20个卷积层,在其后面加上全局平均池化层和全连接层,在Iamge-Net1000个类别的图像分类数据集上对主干结构进行预训练,并且输入图像的尺寸是224x224。
这里提个问题:主干结构的输入要求必须是448x448的固定尺寸,为什么在预训练阶段可以输入224x224的图像呢?
主要原因是加入了全局平均池化层,这样不论输入尺寸是多少,在和最后的全连接层连接时都可以保证相同的神经元数目。至于全局平均池化层是什么就不多说了,百度上有很多详细的解释,其实很简单。
根据论文中的写法,我画出了预训练的网络结构和大致过程:
2.2.2 真正开始训练
经过上一步的预训练,就已经把主干网络的前20个卷积层给训练好了,前20层的参数已经学到了图片的特征。接下来的步骤本质就是迁移学习,在训练好的前20层卷积层后加上4层卷积层和2层全连接层,然后在目标检测的任务上进行迁移学习。
这里需要强调一点:之前的预训练是在图像分类任务上做的,训练起来很简单。而接下来的迁移学习需要在目标检测任务的数据集上面做,除了预测目标类别外,还需要预测目标的位置坐标。所以损失函数肯定要变成适用于目标检测任务的(既包含分类误差,也包含定位误差),这样才能够反向传播进行训练。
具体的损失函数在“ 损失函数设置”部分会详细说明,在此之前,我们需要先弄明白网络最后输出的7x7x30维张量代表的含义。
2.3 输出的7x7x30维张量代表含义
这部分是理解YOLOV1思想很重要的一部分,首先说明YOLOV1的思想:
(1)把输入图像分成7x7=49个小方块,称为“grid cell”,如下图所示;

(2)每个“grid cell”产生两个预测框,称为“bounding box”;
(3)我们在训练集中会把每个object用方框框住,这个方框称为“ground truth”;
(4)“ground truth”的中心点落到哪个“grid cell”中,就由该“grid cell”中的某一个“bounding box”负责预测该目标。
这三个概念非常重要,不要搞混:
| 名称 | 数量 | 作用 |
|---|---|---|
| ground truth | 数量不确定 | 在训练集中,每张图片用方框框出目标 |
| grid cell | 7x7=49 | 把输入图像分成49个小方块 |
| bounding box | 49x2=98 | 每个grid cell有两个bounding box,若ground truth的中心点落在该grid cell中,则选择该grid cell的2个bounding box中,与ground truth IOU最大的那个负责预测该目标 |
上面的表格中提到了IOU,是指两个方框的交并比,即两个方框的交集所占面积比上两个方框的并集所占面积,用来衡量两个方框的重叠程度。
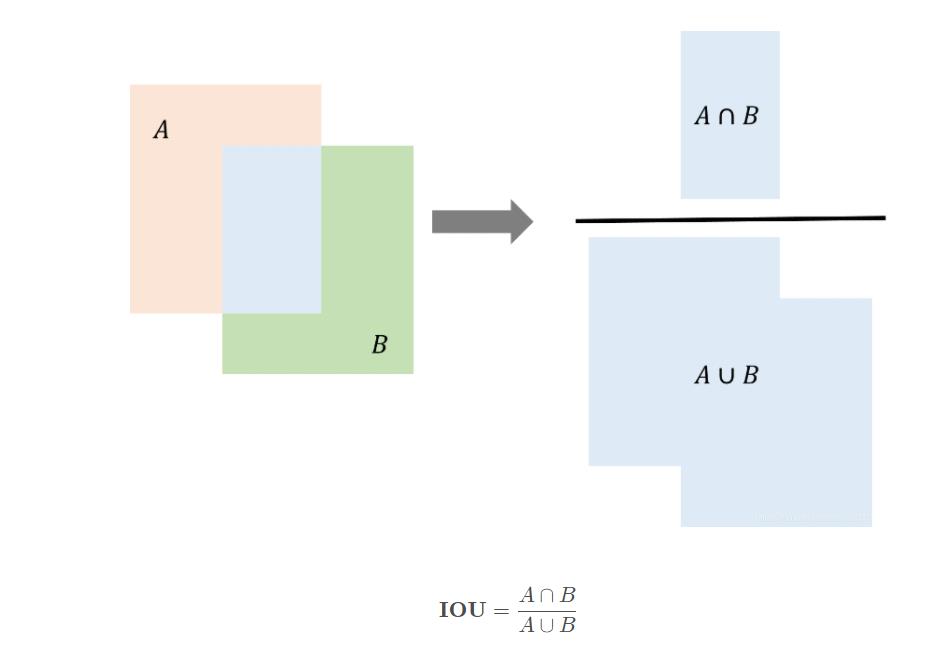
图片来源:目标检测指标IOU
现在开始解释模型最后输出的7x7x30维的张量的含义。

前面的7x7很容易理解,是7x7个grid cell。那么,最后的30是什么呢?这里通过网上的这张图来解释:

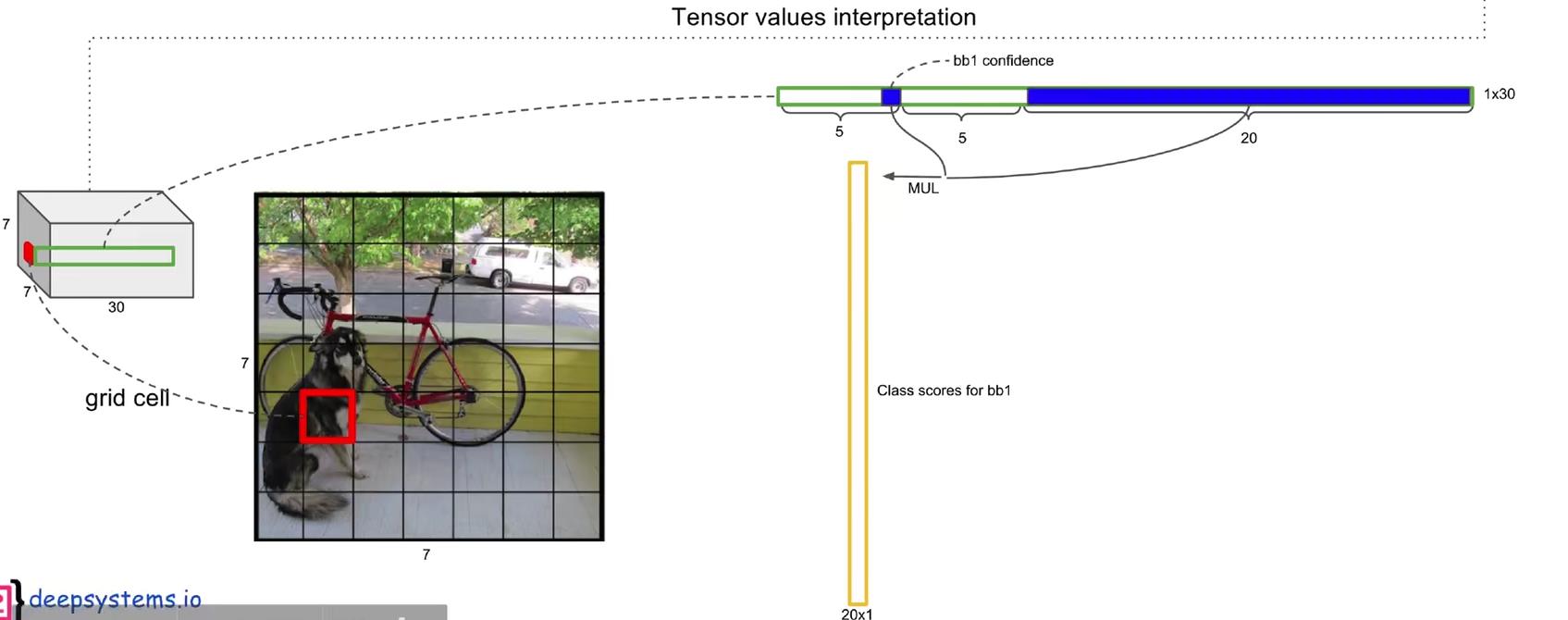
前面说了,共有7x7=49个“grid cell”,而每个“grid cell”有两个“bounding box”,负责预测“ground truth”的位置和类别。因此,最后的30实际上是由5x2+20组成的。
第一个5,分别是x,y,w,h,c。其中:
x,y是指“bounding box”的预测框的中心坐标相较于该“bounding box”归属的“grid cell”左上角的偏移量,在0-1之间。如下图所示
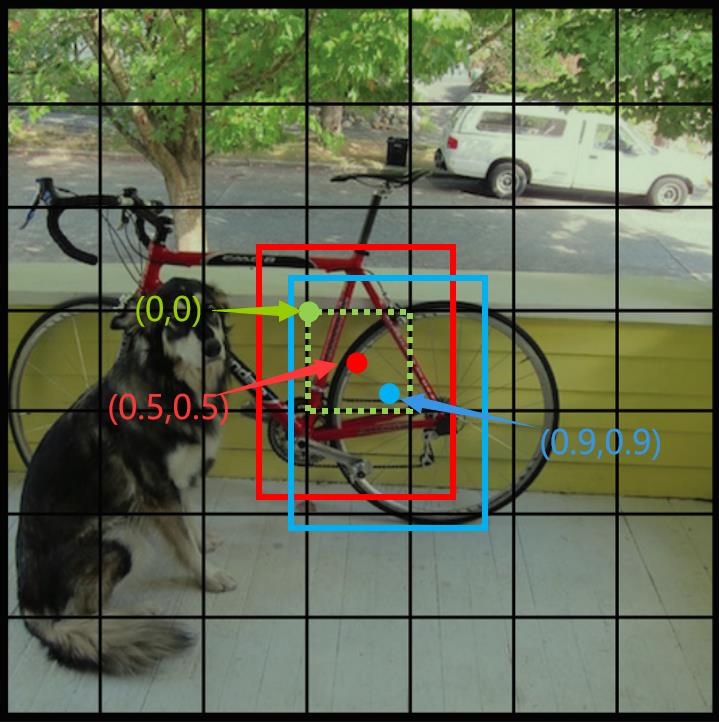
在上图中,绿色虚线框代表grid cell,绿点表示该grid cell的左上角坐标,为(0,0);
红色和蓝色框代表该grid cell包含的两个bounding box,红点和蓝点表示这两个boung box的中心坐标。有一点很重要,bound box的中心坐标一定在该grid cell内部,因此,红点和蓝点的坐标可以归一化在0-1之间。再上图中,红点的坐标为(0.5,0.5),即x=y=0.5,蓝点的坐标为(0.9,0.9),即x=y=0.9。
w和h是指该bound box的宽和高,但也归一化到了0-1之间,表示相较于原始图像的宽和高(即448个像素)。比如该bounding box预测的框宽是44.8个像素,高也是44.8个像素,则w=0.1,h=0.1。
比如对于下面的这个例子:

红框的x=0.8,y=0.5,w=0.1,h=0.2。
那么,最后的c表示什么呢?c是置信度,表示的实际含义是:该bounding box 中含有目标的概率,在论文中表示为:

那么这个c实际是怎么求出来的呢?作者用bounding box与ground truth的IOU来代替c,即作者的思想是:用bounding box与ground truth的重合程度,来表示该bounding box中含有目标的概率,这显然是符合直觉的,也是说得通的。上面图片中的Pr(Object)非0即1,若ground truth的中心点落入该grid cell中,则Pr(Object)=1,否则Pr(Object)=0。
所以,对于一个bounding box,有x,y,w,h,c这五个参数,前四个参数而已确定bounding box的方框,最后的c可以该bounding box 中含有目标的概率。而对于一个grid cell有两个bounding box,因此是5x2。
OK,至此已经解释清楚了30=5x2 + 20中的前半部分,那么后面的20又是什么?
YOLOV1是在PASCAL VOC数据集上训练的,该数据集上有20个类别,因此这里的20表示的是条件概率:在该grid cell包含目标的条件下,该目标是某种类别的概率。在论文中作者用Pr(Classi | Object)表示。因为有20个类别,所以有20个条件概率。
这就是7x7x30中的30表示的具体含义。
另外,因为c表示的是该方框中存在目标的概率,后面的20表示的是条件概率:在该grid cell包含目标的条件下,该目标是某种类别的概率。所以用c乘以条件概率就可以得到全概率,如下图所示。全概率就表示该方框中包含目标的概率。
2.3 损失函数设置
模型的训练离不开损失函数,对于目标检测的损失函数,肯定是既要惩罚方框的定位误差,也要惩罚分类错误的误差,YOLOV1的损失函数长这个样子:
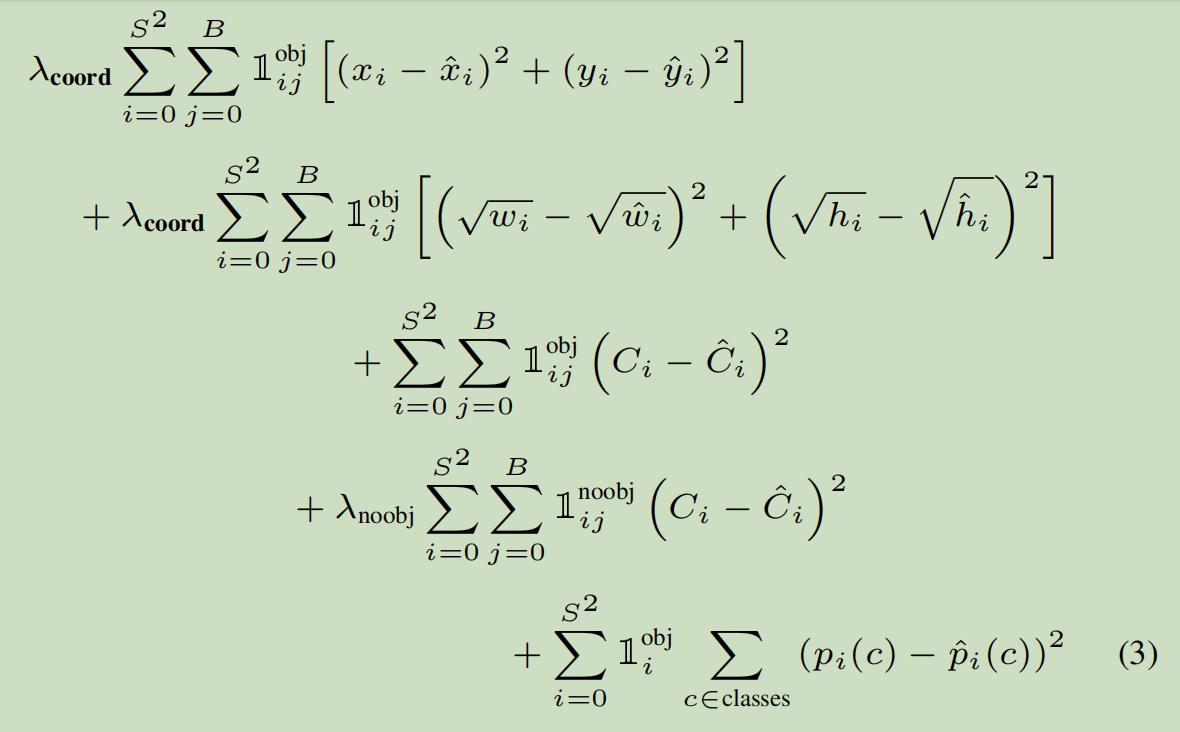
(图片来自论文原文)
看着有些复杂,其实本质非常浅显易懂。我们先来直观看一下,所有的误差选用的都是平方和误差,这也是为什么YOLOV1在论文开头就说明自己把目标检测当作了回归问题去处理:

这里解释下其中的三个符号的含义,引用同济子豪兄视频里的截图。
图片来源:https://www.bilibili.com/video/BV15w411Z7LG?p=11
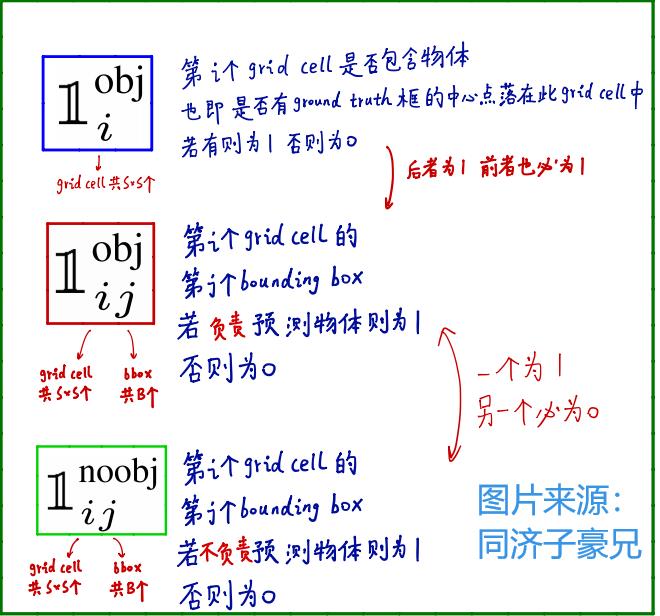
这个损失函数很好理解,总共有5项,我们来一项一项看:
(1)第一项:

S2=7x7=49,表示49个grid cell,B表示每个grid cell中包含的bounding box数目,为2。第一个xi表示模型预测的bounding box的横坐标,为0-1之间的数。第二个xi为标签值,是ground truth相较于该grid cell左上角的偏移量。yi也同理。
因此,第一项衡量的是:负责检测物体的bounding box的中心点的定位误差。说得更直白点儿就是:这个bounding box位置定的准不准。
(2)第二项:

道理其实和第一项差不多,这里衡量的是bounding box的宽和高的误差,即:这个bounding box是不是和ground truth贴合得有多严丝合缝。
但有一点需要强调一下,为什么这里要开根号,而不是像第一项一样直接用w呢?
这是为了使得小框对于宽高的拟合损失更加敏感,考虑下面的情况:
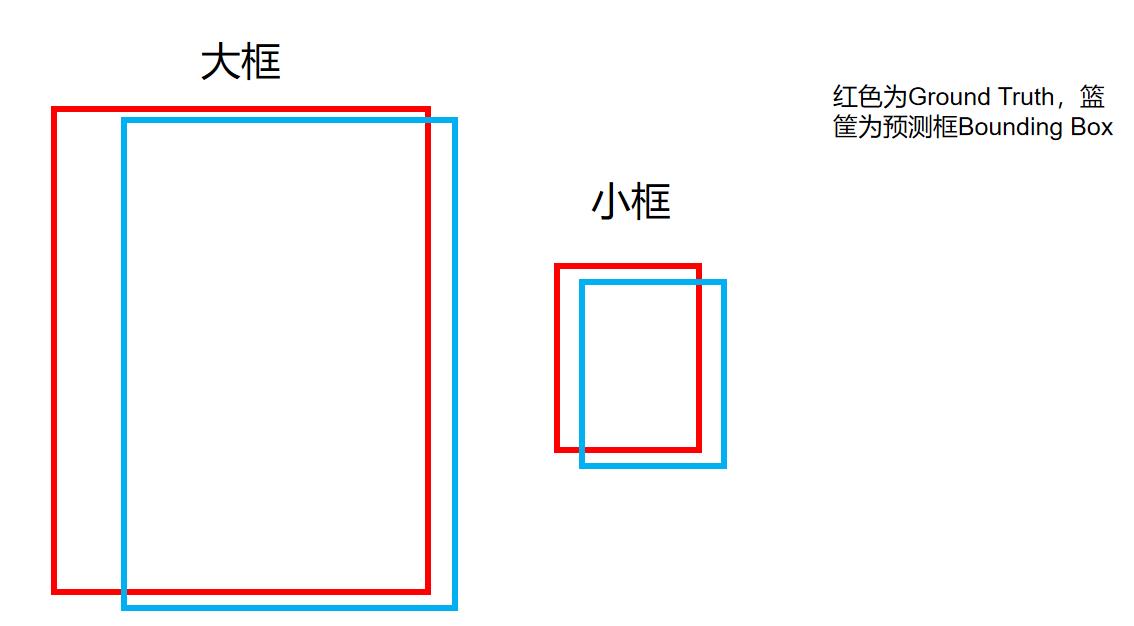
在上图中,大框和小框的bounding box都和ground truth差了一点,但对于实际预测来讲,大框(大目标)差的这一点也许无关痛痒,而小框(小目标)差的这一点可能就会导致bounding box的方框和目标差了很远。而如果还是使用第一项那样直接算平方和误差,就相当于把大框和小框一视同仁了,这样显然不合理。而如果使用开根号处理,就会一定程度上改善这一问题:
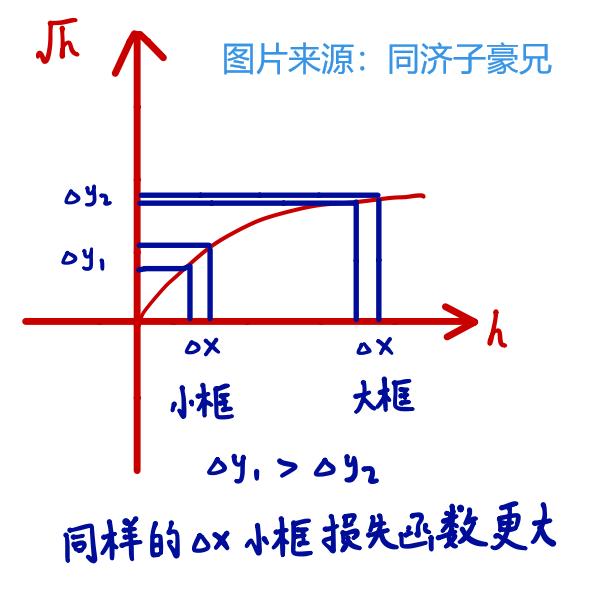
这样一来,同样是差一点,小框产生的误差会更大,即对小框惩罚的更严重。
(3)第三项:

前两项涉及到了x,y,w,h四个参数,第三项和第四项则涉及到了第五个参数c。同样是用平方和损失函数来衡量,其中,第一个Ci是模型预测出的置信度,而第二项Ci是标签值,具体计算方法前面也说过了,就是该bounding box与ground truth的IOU。
因此第三项衡量的:负责检测物体的bounding box的置信度误差。
(4)第四项:
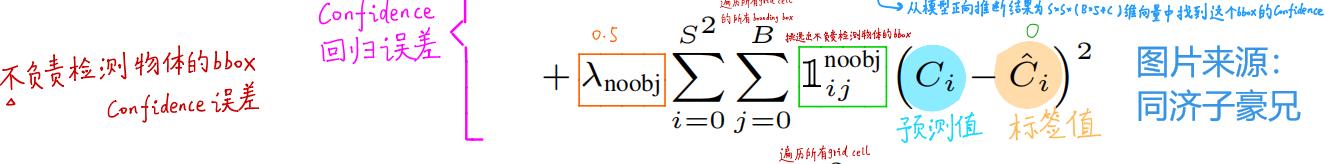
第四项与第三项基本一样,不过衡量的是:不负责检测物体的bounding box的置信度误差。
这里强调一点:不负责检查物体的bounding box有两类:一类是该bounding box所在的grid cell中,不包含ground truth的中心点;另一类是虽然该bounding box所在的grid cell包含ground truth的中心点,但该bounding box与ground truth的IOU没有另外一个bounding box与ground truth的IOU大。
(5)第五项:

第五项衡量的是:负责检测物体的grid cell的分类误差。其实就是之前说的20个条件概率。很好理解,比如说对于模型预测值来讲,这20个类别的条件概率是一个20维的向量:[0.7,0.1,0.05,0,0…],而标签值则是一个只包含一个1其余全是0的20维向量:[1,0,0,…],计算第五项的误差就是把对应元素相减然后平方再求和。
至此,再来看损失函数:
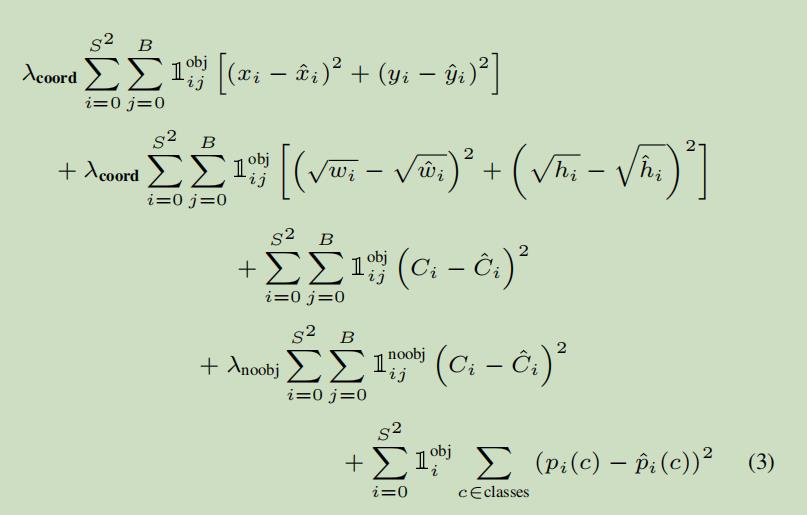
前两项衡量了负责预测的bounding box的定位误差,且给了一个较高的权重λ=5。
第三项衡量了负责检测物体的bounding box的置信度误差,希望模型预测出的该项置信度尽可能等于bounding box与ground truth的IOU。
第四项衡量了不负责检测物体的bounding box的置信度误差,希望模型预测出的该项置信度尽可能等于0。因为是不负责检测物体的bounding box,所以给了一个较小的权重λ=0.5。
最后一项衡量了模型的分类误差,实际上就是让模型预测出的正确类别的条件概率尽可能等于1。
至此就解释清楚了YOLOV1的损失函数。既然定义好了损失函数,接下来要做的就是反向传播、梯度下降训练模型了,具体的训练参数可以看原论文。模型的训练部分也就结束了。
3.YOLO V1推断过程(NMS后处理)
先来回顾下YOLOV1的大体思路:
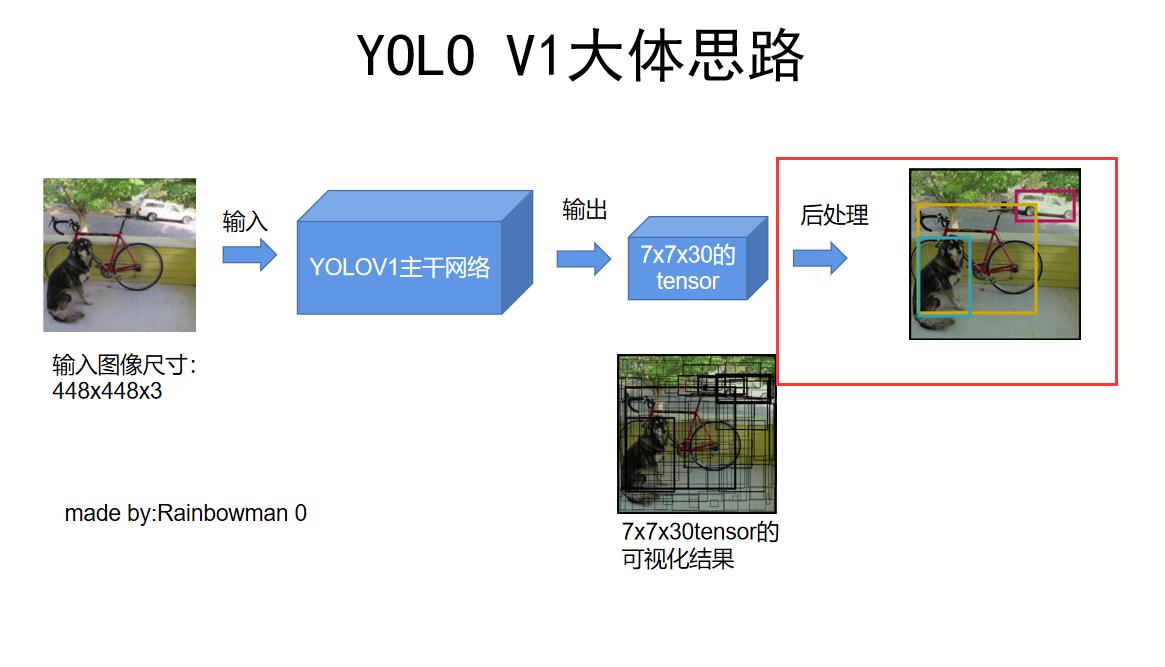
我们刚刚解释了YOLOV1主干网络的具体结构、主干网络如何训练、最后输出的7x7x30tensor的含义以及损失函数。
其实以上这些都是训练过程的内容,而模型训练好了,就需要用来推理了:我们输入一张448x448x3的图像,模型给出了7x7x30的tensor。虽然这个tensor中确实包含了bounding box的位置和类别信息,但我们知道,总共有7x7x2=98个bounding box,也就是说直接输出的7x7x30的向量如果可视化之后长这个样子:

其中方框线的粗细代表了该bounding box的置信度c。置信度越高,线越粗。
然而这样的结果显然是我们无法直接使用的,我们最终希望得到的结果长这样:

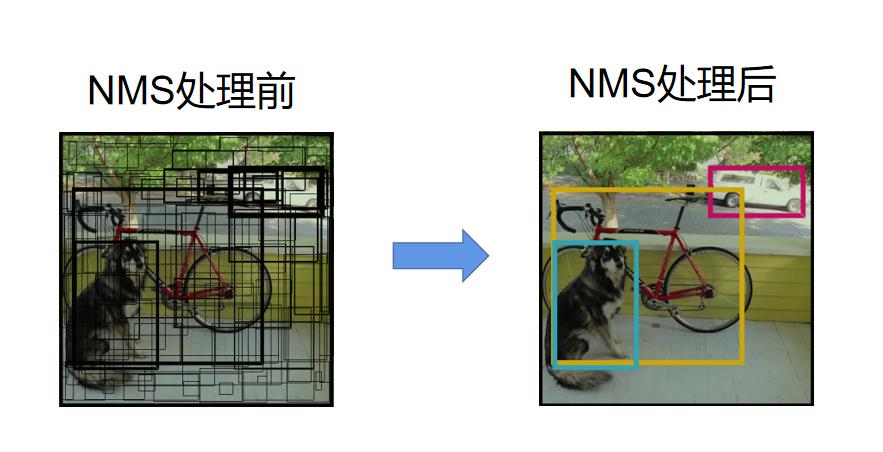
这就需要我们进行NMS非极大值抑制的后处理操作:
我们需要对这样的结果进行后处理,最终得到最合理的几个方框,我们需要剔除置信度很低的bounding box(置信度低意味着模型认为该bounding box的预测框和ground truth框的IOU很小),另一方面我们需要提出重复预测的bounding box(比如两个相邻的grid cell的bounding box都框出了同一条狗,两个bounding box的重合度很高,如下图的红框和篮框,应该去掉一个,因为重复预测同一个物体了)

而NMS就可以解决这一问题,NMS的具体思路为:
(1)对于最终输出的7x7x30的tensor的每一列拿出来(指的是30维度的那一列),用每个bounding box的置信度c(30个参数里总共包含了两个bounding box的置信度c)乘那20个条件概率,即可得到20个全概率,最终可以得到一个98x20的矩阵
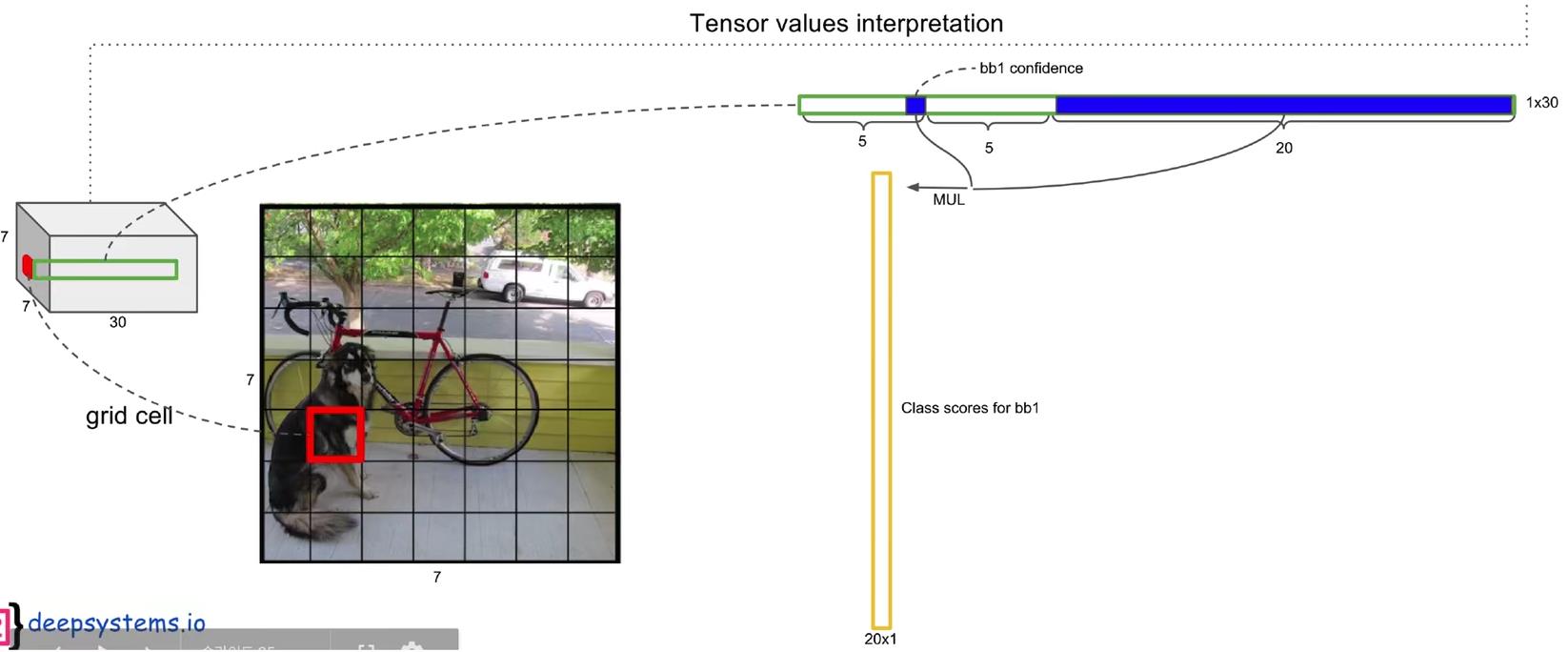
上图展示了求出第一个grid cell的第一个bounding box对应的20个类别的全概率。
具体的细节在“2.3 输出的7x7x30维张量代表含义”中解释过了。对于每一个grid cell,都可以得出两个20维的全概率(因为每个grid cell有两个bounding box),所以总共可以得到98个20维的向量,如下所示:
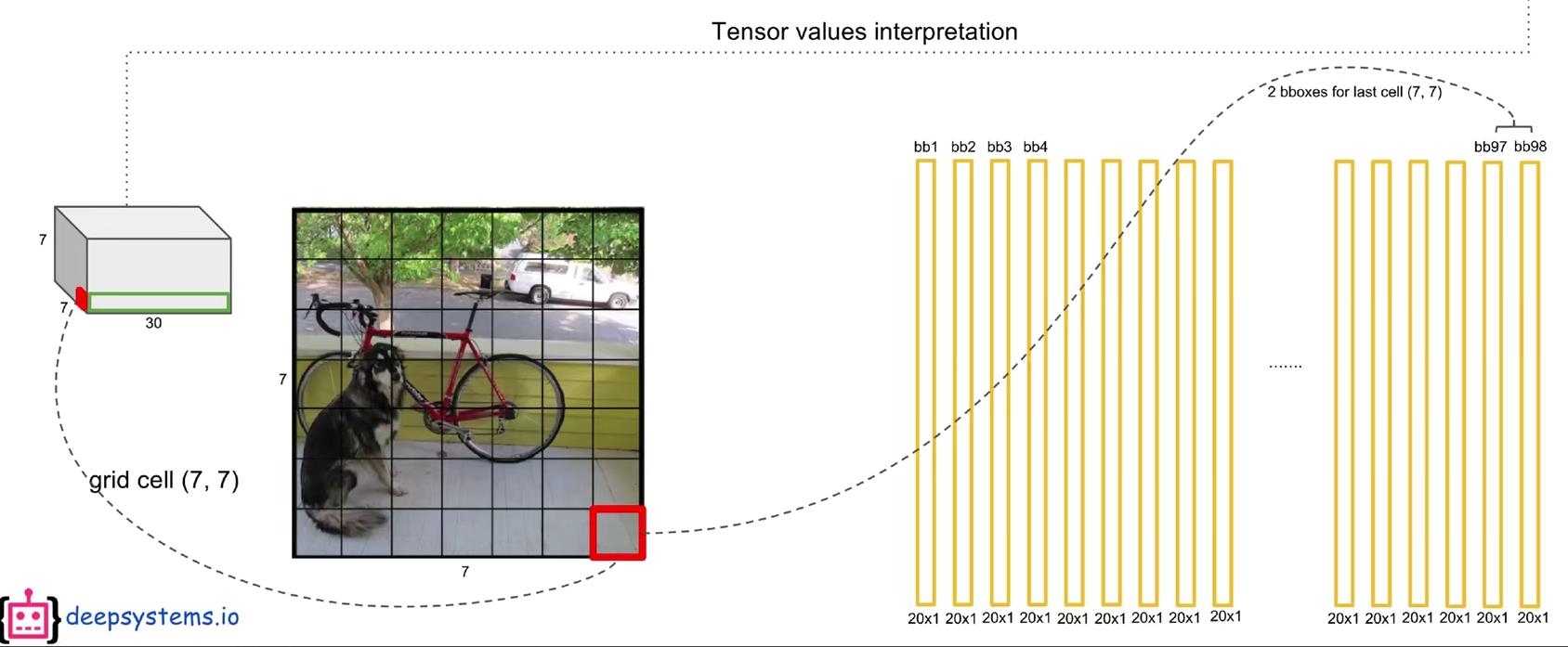
最终我们得到了一个98x20的矩阵:
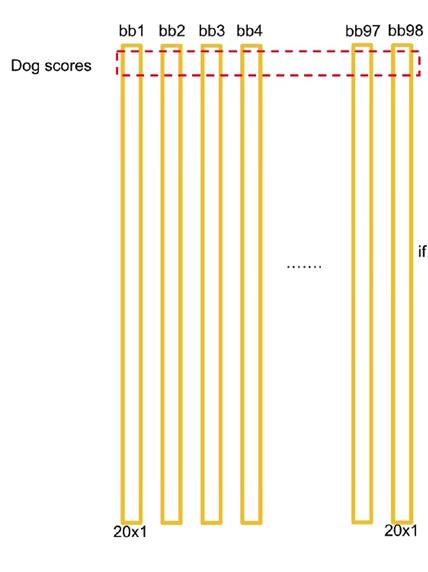
这其中,每一行代表这98个bounding box对某一类别的全概率,如第一行(代表狗)的第一列的元素,代表的含义是:第一个grid cell的第一个“bounding box,认为该方框中存在狗的全概率是多少,我们称这个数为置信度。
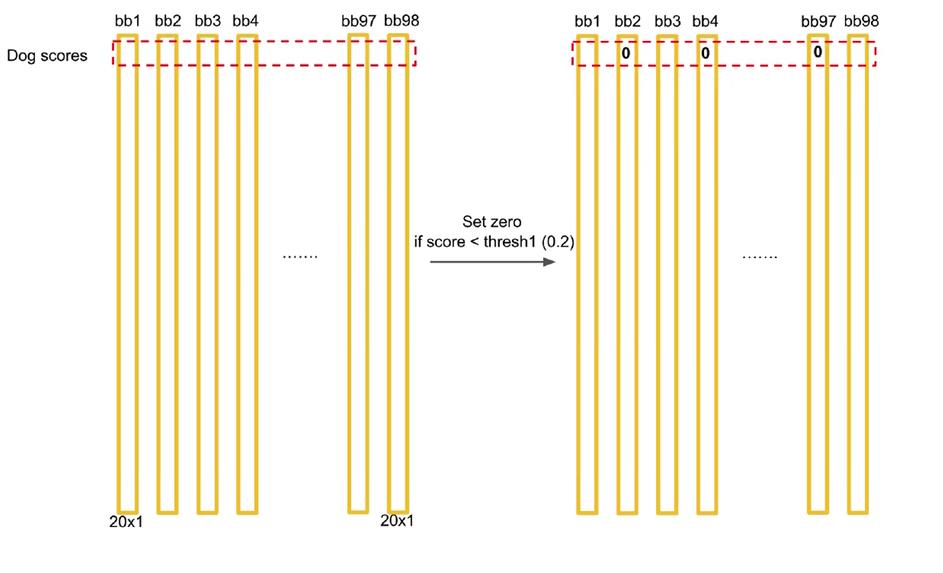
(2)对矩阵进行逐行处理,以第一行为例,首先将置信度小于某个具体阈值的数(YOLOV1中设置为0.2)全部置为0。
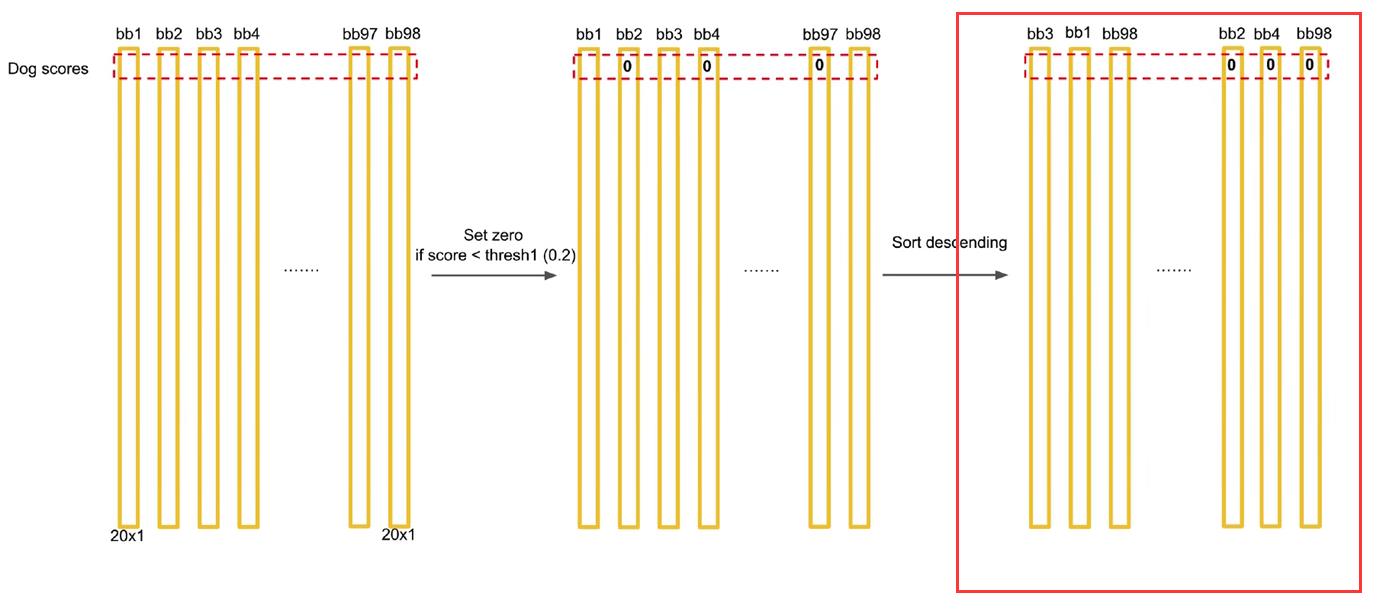
(3)将经过第二步处理后,按照某一行中元素的大小,按列进行从大到小排序:
(4)从第一个非0的元素开始,用该bounding box对应的框与剩下的非零元素的bounding box对应的框的IOU进行比较,若IOU大于某一个阈值(如0.5),则把置信度小的元素置为0,如下所示:
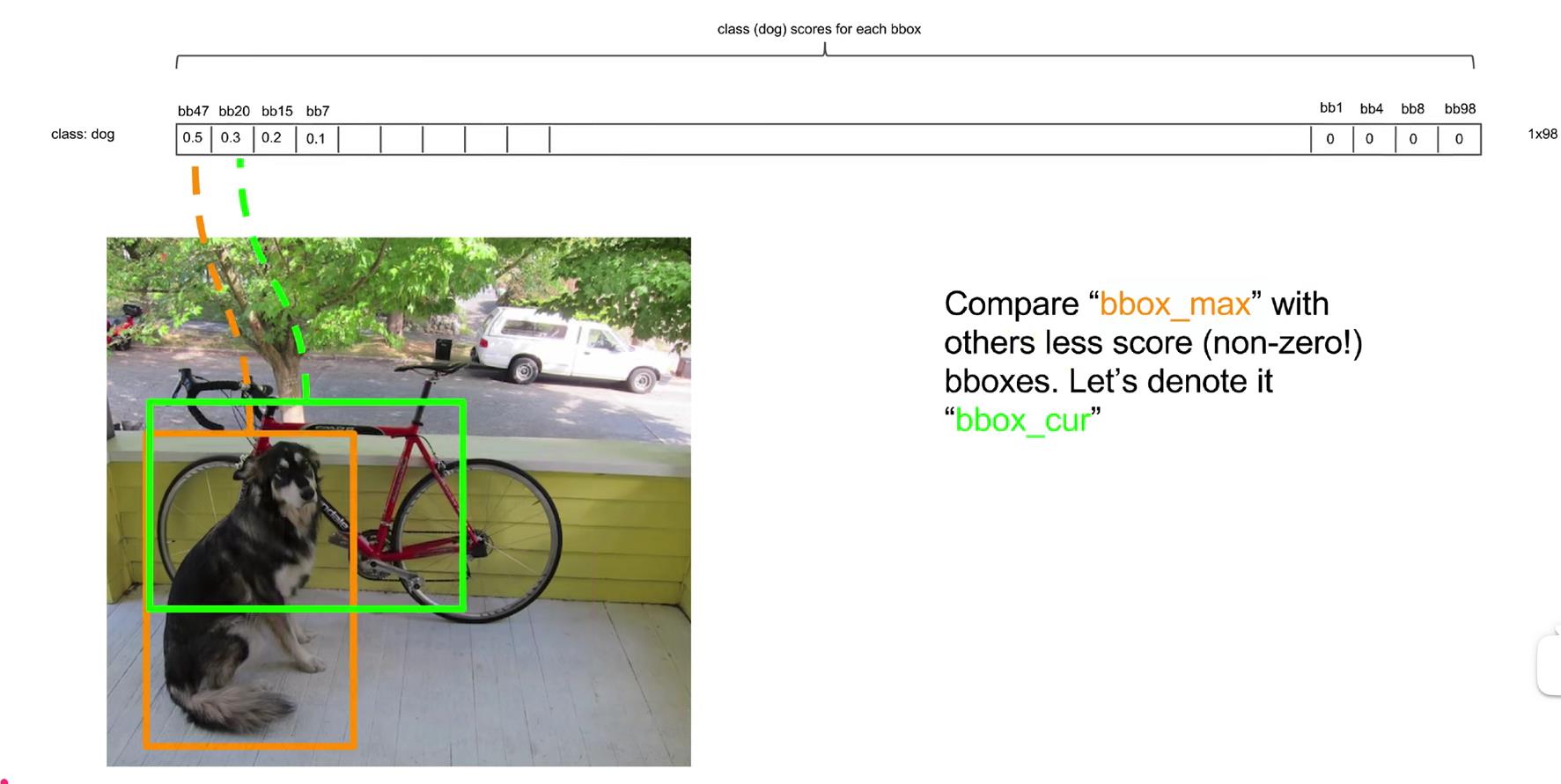
在上图中,第一个元素和第二个元素的bounding box对应的方框IOU超过了阈值0.5,所以第二个元素(绿色)要被置为0,得到的结果为:
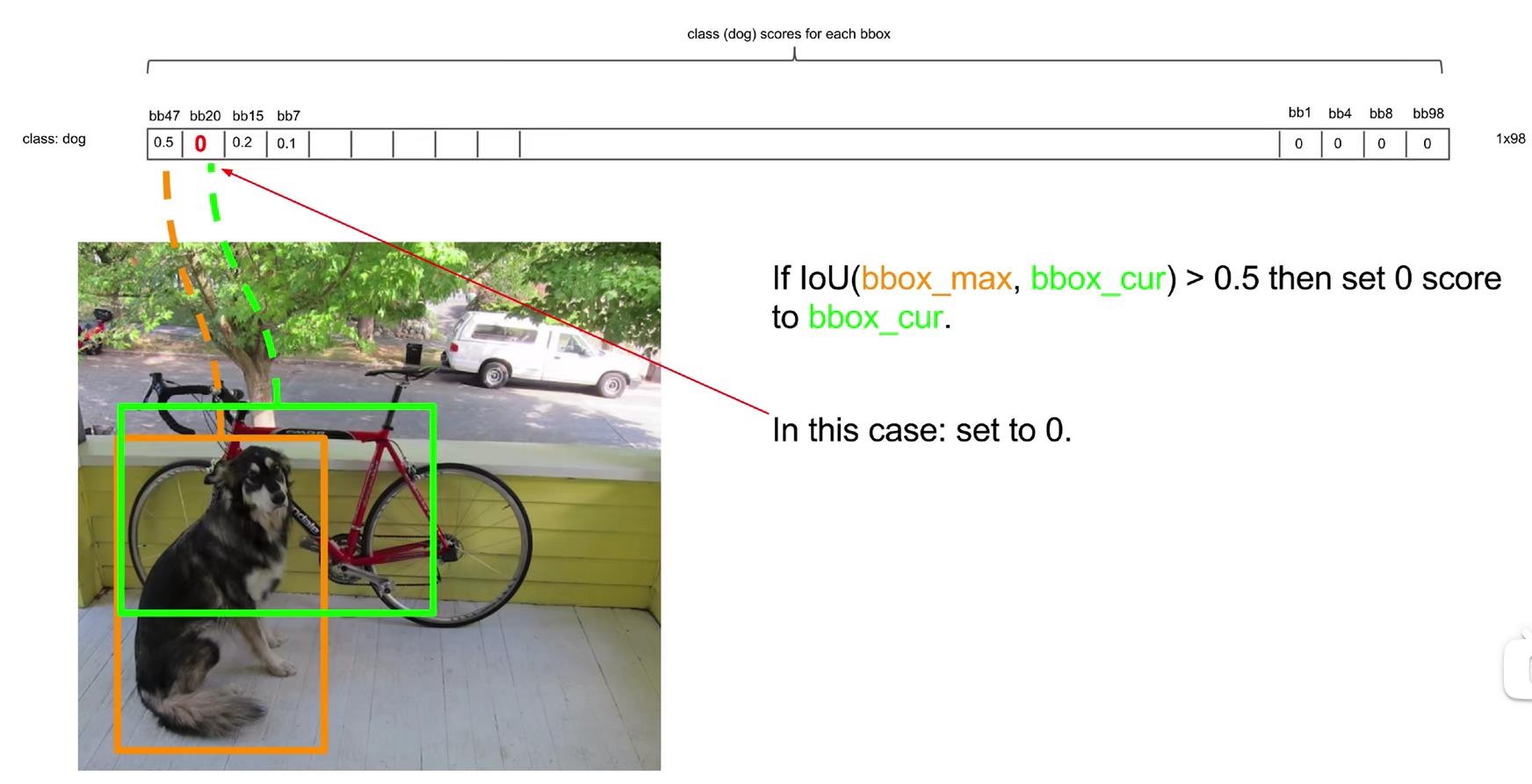
(5)对剩下的非0元素依次进行第四步
以上就是NMS的具体过程,简单来说,NMS后处理的作用如下图所示:
感觉文字的表达能力实在有限,建议还是去看看同济子豪兄关于NMS的讲解,清晰直观,视频地址为:
https://www.bilibili.com/video/BV15w411Z7LG?p=5
4. YOLOV1 与其他模型的比较
作者比较了YOLOV1和其他模型的mAP和速度,比较结果如下:

这个图开头已经说过了,简单来说就是FAST YOLO是当前最快的模型,且mAP不低。YOLOV1是实时目标检测(FPS>30)领域内mAP最高的模型。Fast R-CNN和Faster R-CNN虽然mAP都要比YOLOV1高一些,但速度远比不上YOLOV1。
这里我们再来看另一个图,作者在VOC 2007上对Fast R-CNN(当时最理想的模型)和YOLOV1进行了细致的比较,总共比较了Correct、Localization、Similar、Other、Background五个种类:
Correct:正确分类,且预测框与ground truth的IOU大于0.5,既预测对了类别,预测框的位置和大小也很合适。
Localization:正确分类,但预测框与ground
truth的IOU大于0.1小于0.5,即虽然预测对了类别,但预测框的位置不是那么的严丝合缝,不过也可以接受。
Similar:预测了相近的类别,且预测框与ground
truth的IOU大于0.1。即预测的类别虽不正确但相近,预测框的位置还可以接受。
Other:预测类别错误,预测框与ground truth的IOU大于0.1。即预测的类别不正确,但预测框还勉强把目标给框住了。
Background:预测框与ground truth的IOU小于0.1,即该预测框的位置为背景,没有目标。
作者对比了Fast R-CNN和YOLOV1在这几项指标的错误率,情况如下:
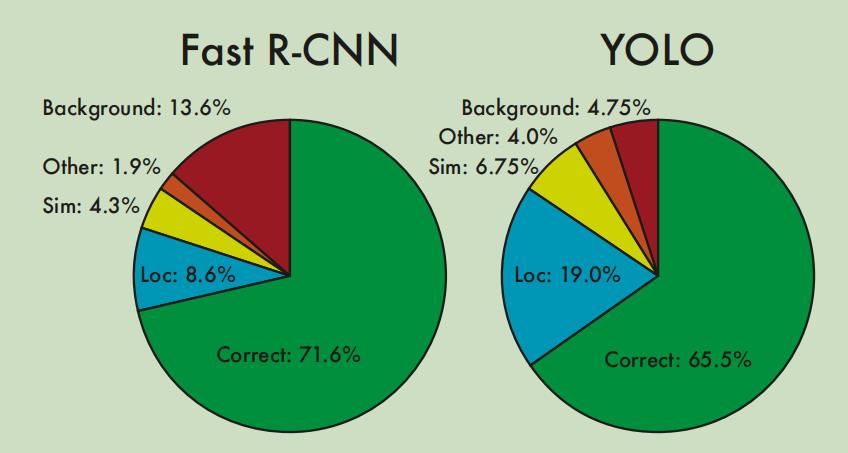
可以看出,Fast R-CNN更容易把背景预测成目标,而YOLO的预测框定位没有Fast R-CNN准确。
所以很自然的想法是把两个模型结合,结合后的模型mAP如下:
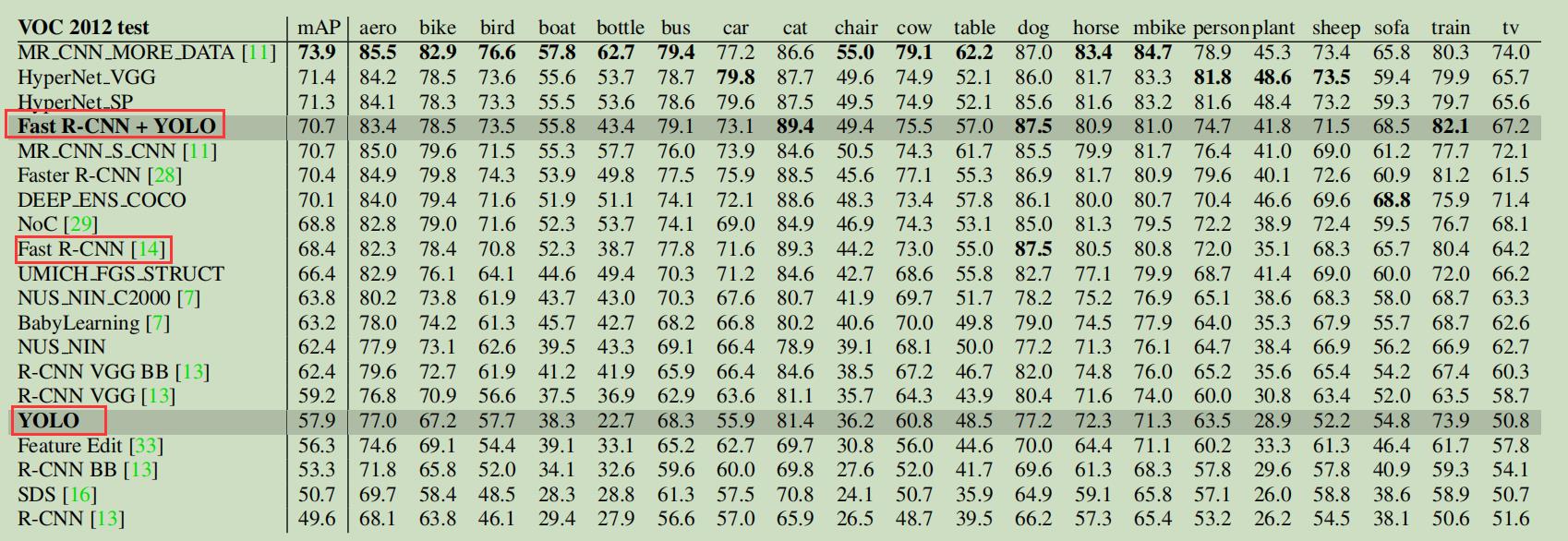
可以看到整体的mAP确实从Fast R-CNN的68.4提升到了70.7,提升还不少。
另外,作者也比较了YOLO和其他模型的泛化性能,具体方法是:在PASCAL VOC这个现实世界的数据集上进行训练,然后去预测艺术品数据集Picasso Dataset和People-Art Dataset数据集上进行预测。
因为艺术品和现实世界的差距还是很大的,YOLO的预测效果如下:

YOLOV1和别的模型的泛化能力比较:
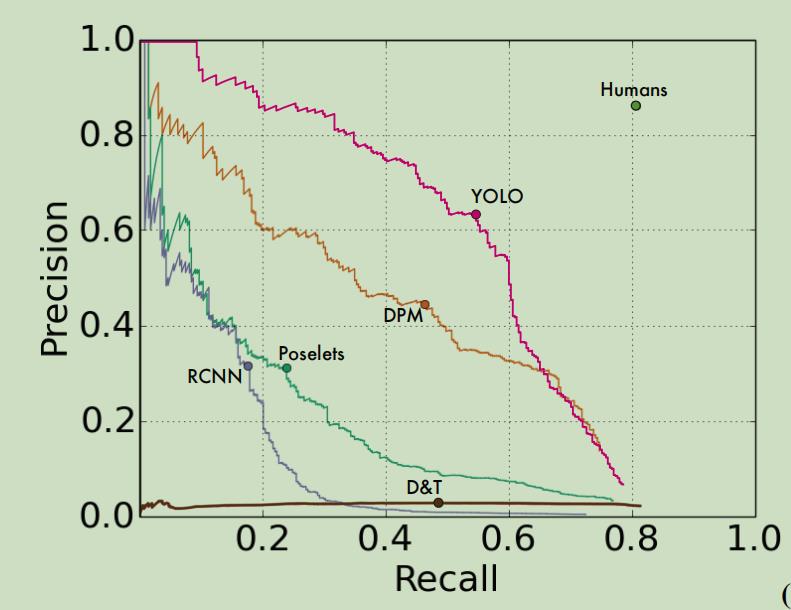
可以看到RCNN的泛化能力远不如YOLO,YOLOV1是目前泛化能力最强的模型。
这其实很令人兴奋,因为在现实生活中,我们常认为只有你能做到举一反三、灵活运用,才能认为你熟练掌握了该知识。而YOLO的泛化能力显然就很好地做到了举一反三。YOLO更像是在模拟考和最终高考中都做得很好的学生,而别的模型更像是在模拟考中做得很好,但当高考和模拟考题型相差很大时,其他的模型做得较差。
5. YOLOV1的优势与不足
5.1 YOLOV1的优势
(1)速度快
YOLO的优势很多,最具优势的是速度快!目标检测本身的任务性质就提出了实时的要求,帧率自然是越高越好。
(2)准确率高
YOLOV1的准确率虽然不是当时最高的,但mAP也直逼当时的SOTA模型。
(3)端到端的模型,后续优化容易
之前的两阶段模型都是pipeline式的设计,很多部分融合在一起,各部分单独优化起来很复杂,性能提升也有限。YOLOV1提出了单结段的目标检测,直接提出了一个端到端的模型,输入一张图像,直接输出该图像中目标的种类和位置坐标。
这一方面让人从直觉上感到合理和优雅,另一方面也方便后续进行优化,直接在该端到端的模型上进行优化改进,从要好过在pipeline里对每一部分进行优化要强得多。
以上三点是我的个人理解。
5.2 YOLOV1的不足
当然,夸了YOLOV1这么多,它也存在不少有待改进的地方:
(1)对小目标的识别效果较差
这点其实论文中的实验数据也有所说明:
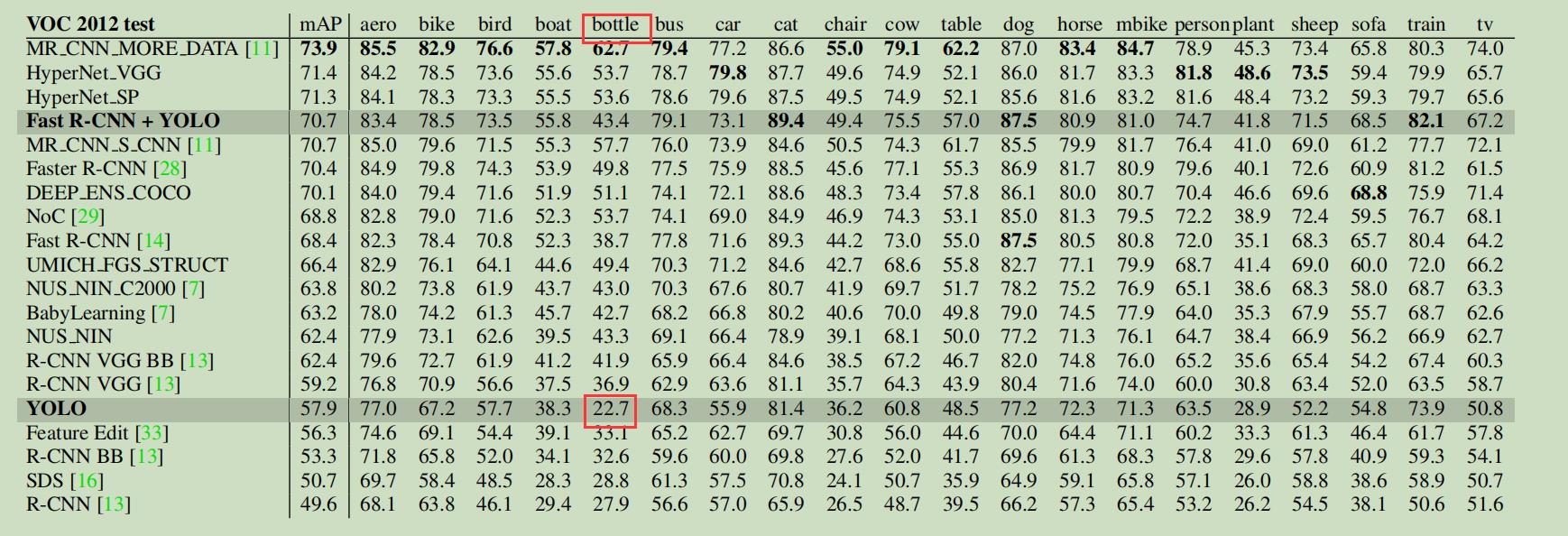
可以看到YOLOV1在对“瓶子”这类小物体上的识别效果较差,至于小物体识别较差的原因其实可以好好说道说道:
这其实是由本身的设计造成的:我们知道,在YOLOV1中,一张图片被分为7x7=49个grid cell,每个grid cell中可能最多有一个bounding box负责预测目标,也就是最多只能预测49个目标。且这49个目标的ground truth中心点需要分别落在49个grid cell中。而对于小目标而言,假如一个grid cell中出现好几个小目标(如鸟群),就会预测不到。
(2)准确率还有待提高
YOLOV1的准确率确实不低,但mAP也不是最高的。这里有一个插曲,YOLOV1的作者Joseph Redmon在CVPR上作报告时,为了装B自己拿了个摄像头给观众演示自己的YOLOV1有多NB,但其中有一个场景是他弯下腰时,YOLOV1把他背后的墙体预测成了“Toilet”。
(3)预测框的定位误差有待减小
之前的饼图也看到了,YOLOV1相较于Fast R-CNN而言,预测框的定位没有那么的准确,这点也是可以改进的地方。
6. 总结
我是没想到写YOLOV1的总结这么费时间,我今天花了大半天的时间去整理、画图、看视频,但也确实增进了对YOLOV1的理解。
尽管如此,我还是能感觉到自己表述中有一些不清楚的地方,一些知识点的理解也包含了部分主观性。因此,最好的学习资料还是作者的论文原文。
接下来一段时间会更新YOLOV2(YOLO 9000)的论文精读和学习总结,可以期待一下。(不过不知道有没有人看哈哈哈哈,寒假快乐!
以上是关于YOLO系列YOLO V1 论文精读与学习总结的主要内容,如果未能解决你的问题,请参考以下文章