emplace_back优势在哪里?
Posted 每天告诉自己要努力
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了emplace_back优势在哪里?相关的知识,希望对你有一定的参考价值。
先贴上c++11升级版的push_back源码,实则是在传入右值时,调用emplace_back();

下面做了个测试:
class A
public:
A()
cout << "默认构造" << endl;
A(int a)
cout << "有参构造" << endl;
~A()
cout << "析构函数" << endl;
A(A&& a)
cout << "右值构造" << endl;
A(const A& a)
cout << "左值构造" << endl;
;
开始测试
test1
void test1()
vector<A> vec;
A a;
cout << "______开始测试_____" << endl;
vec.push_back(a);
//vec.emplace_back(a);
cout << "________________" << endl;
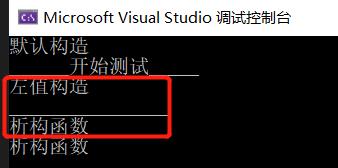 当传入一个构造的对象时,毫无意外,push_back和emplace_back结果是一样的。
当传入一个构造的对象时,毫无意外,push_back和emplace_back结果是一样的。
test2
void test2()
vector<A> vec;
cout << "______开始测试_____" << endl;
//vec.push_back(A);
vec.emplace_back(A());
cout << "________________" << endl;
两种方法的结果是一样的。
test3
void test3()
vector<A> vec;
cout << "______开始测试_____" << endl;
//vec.push_back(5);
vec.emplace_back(5);
cout << "________________" << endl;
如果是emplace:

如果是push_back:

结论:
emplace_back为什么优于push_back呢?
我觉得是因为c++11带来的几个新特性导致的:右值引用、模板参数列表可变长、右值引用的完美转发。
其中由于push_back升级了也有右值引用的版本。
因此emplace_back的优势主要在于模板参数列表可变长和完美转发。
①只有在容器中push或emplace自定义的数据类型时,才有讨论二者差别的意义。其他情况下,效果是一样的。
②在添加自定义数据时,push_back只支持一个参数的传入,而emplace_back可以支持多个。
③性能差异主要在于,在添加自定义类型时,并且只是传入1个参数时,并且需要触发自定义类型中的有参构造时,才会有区别。
区别在于:
- emplace直接调用有参构造创建出临时对象,并且通过forward函数进行完美转发,原地完成添加数据。整个过程只构造一次、析构一次。
- 而push_back需要自身先调用默认构造生成临时对象,再通过移动构造生成一个临时副本,把这个临时副本再传给emplace进行原地构造。再传给emplace_back之前,多出了一次移动构造和析构,因此一共是两次构造两次析构。
以上是关于emplace_back优势在哪里?的主要内容,如果未能解决你的问题,请参考以下文章