数据结构与算法:树 赫夫曼树
Posted 史大拿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法:树 赫夫曼树相关的知识,希望对你有一定的参考价值。
Tips: 采用java语言,关注博主,底部附有完整代码
工具:IDEA
本系列介绍的是数据结构: 树
这是第6篇目前计划一共有11篇:
- 二叉树入门
- 顺序二叉树
- 线索化二叉树
- 堆排序
- 赫夫曼树(一)
- 赫夫曼树(二) 本篇
- 赫夫曼树(三)
- 二叉排序树(BST)
- 平衡二叉排序树AVL
- 2-3树,2-3-4树,B树 B+树 B*树 了解
- 数据结构与算法:树 红黑树 (十一)
敬请期待吧~~
高光时刻
随机字符串生成赫夫曼树完整流程:

回顾
先来回顾一下上一篇,上一篇的重点就是创建一颗赫夫曼树,
赫夫曼树是WPL 最小的树
上一篇是将数组转变成赫夫曼树
流程为:
-
将数组转变成赫夫曼结点集合
-
依次取出集合中前两个数据生成一个新的结点,然后删除掉这两个旧的结点
-
重新排序
-
重复2,3操作,直到集合中只剩下一个结点
最终赫夫曼集合中最后的这个结点就是他的根节点
完整流程图:

随机字符串生成赫夫曼树
解释一下什么叫随机字符串生成赫夫曼树
假设当前有一串字符串为 :
String str = “统计字符串个数122333”;
可以看出,字符串中有重复的数据
例如
- 22
- 333
那么就将权值设置为字符串中每个字符的个数,
在新添加一个变量来记录当前字母
修改赫夫曼结点
public class HuffmanNode implements Comparable<HuffmanNode>
// 权值 【字母个数】
public int value;
// 字母
public Byte by;
// 左子结点
public HuffmanNode leftNode;
// 右子结点
public HuffmanNode rightNode;
public HuffmanNode(int value, Byte by)
this.value = value;
this.by = by;
// 前序遍历
public void show() ...
@Override
public int compareTo(HuffmanNode o)
return value - o.value;
这里用包装类Byte来记录字母完全是因为Byte能够设置null
统计字符串个数
// 统计字符串个数
public static void count()
String str = "统计字符串个数122333";
HashMap<Character, Integer> map = new HashMap<>();
for (int i = 0; i < str.length(); i++)
char ch = str.charAt(i);
int temp = 0;
// 判断是否包含key
if (map.containsKey(ch))
// 包含key取出对应的value进行累加
temp = map.get(ch);
map.put(ch, temp + 1);
System.out.println("字符个数为:" + map);
结果
字符个数为:数=1, 计=1, 1=1, 串=1, 2=2, 3=3, 符=1, 字=1, 个=1, 统=1
这段代码很好理解,也是一道很常见的面试题!
因为这段代码重复的字母不多,体现不出赫夫的优点,现在讲原本字符串替换成
String str = “i like like like java do you like a java”;
这段字符串,分别为:
- d : 1
- v : 1
- u : 1
- j : 2
- v : 2
- o : 2
- l : 4
- k : 4
- e : 4
- i : 5
- a : 5
- 空格 : 9
左边是字母,右边是字母个数
然后通过昨天的代码来稍微改改就可以:
完整流程:

代码
赫夫曼代码:
# 赫夫曼代码:
public static HuffmanNode createHuffmanTree(ArrayList<HuffmanNode> list)
while (list.size() > 1)
// 排序
Collections.sort(list);
// System.out.println("第" + index + "次变化过程前:" + list);
// 左子结点
HuffmanNode left = list.get(0);
// 右子结点
HuffmanNode right = list.get(1);
HuffmanNode parent = new HuffmanNode(left.value + right.value, null);
parent.leftNode = left;
parent.rightNode = right;
// 删除左子结点
list.remove(0);
// 删除右子结点
list.remove(0);
list.add(parent);
// 返回root结点
return list.get(0);
这段代码很简单,上一篇也说过~
最终随机生成的赫夫曼树为:
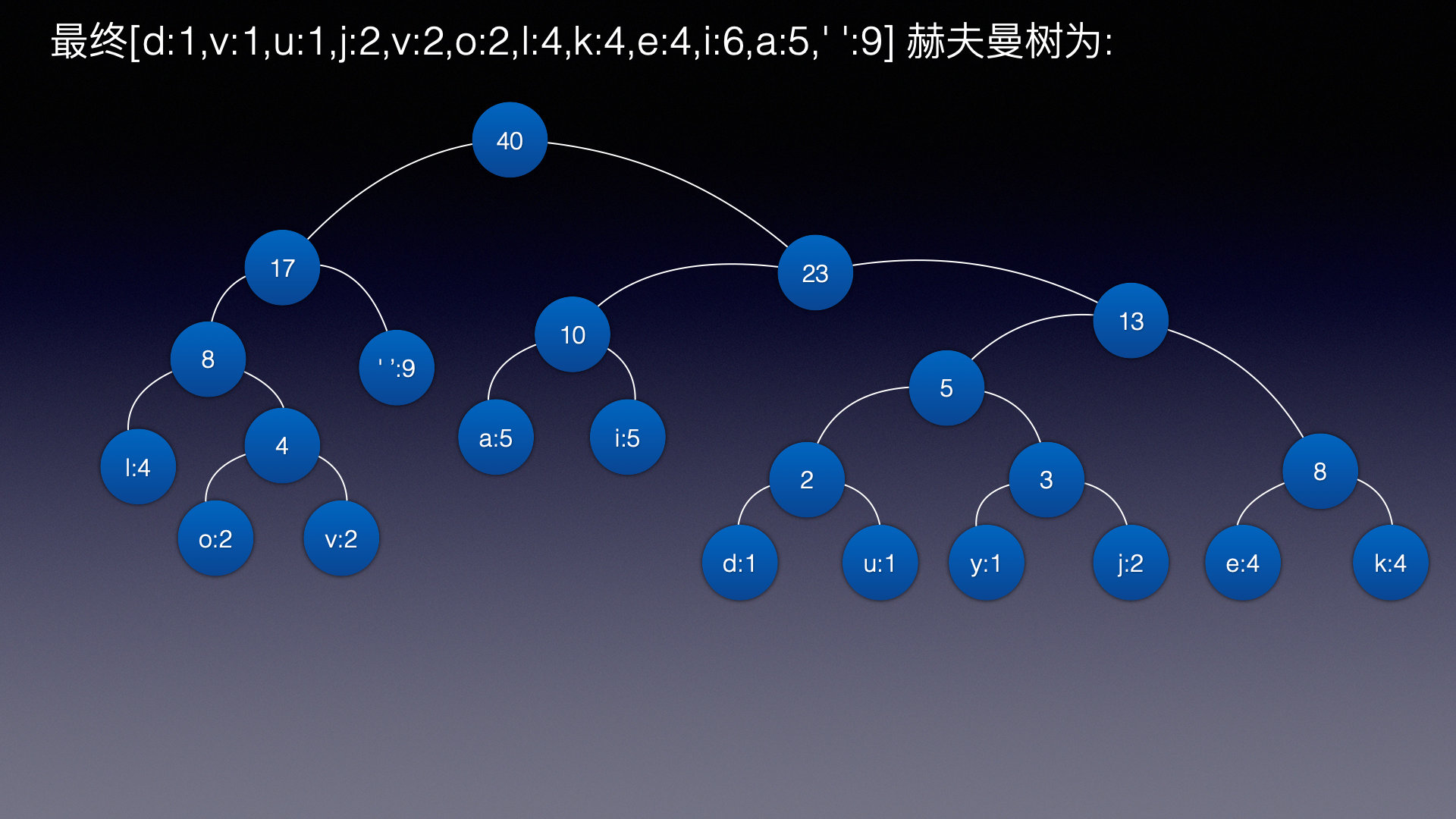
此时规定
- 左子结点用0表示
- 右子结点用1表示
遍历所有的叶子结点,因为在赫夫曼树中,叶子结点一定是有权值的!
也就是说遍历的整个树,获取到整个树中所有的权值数据
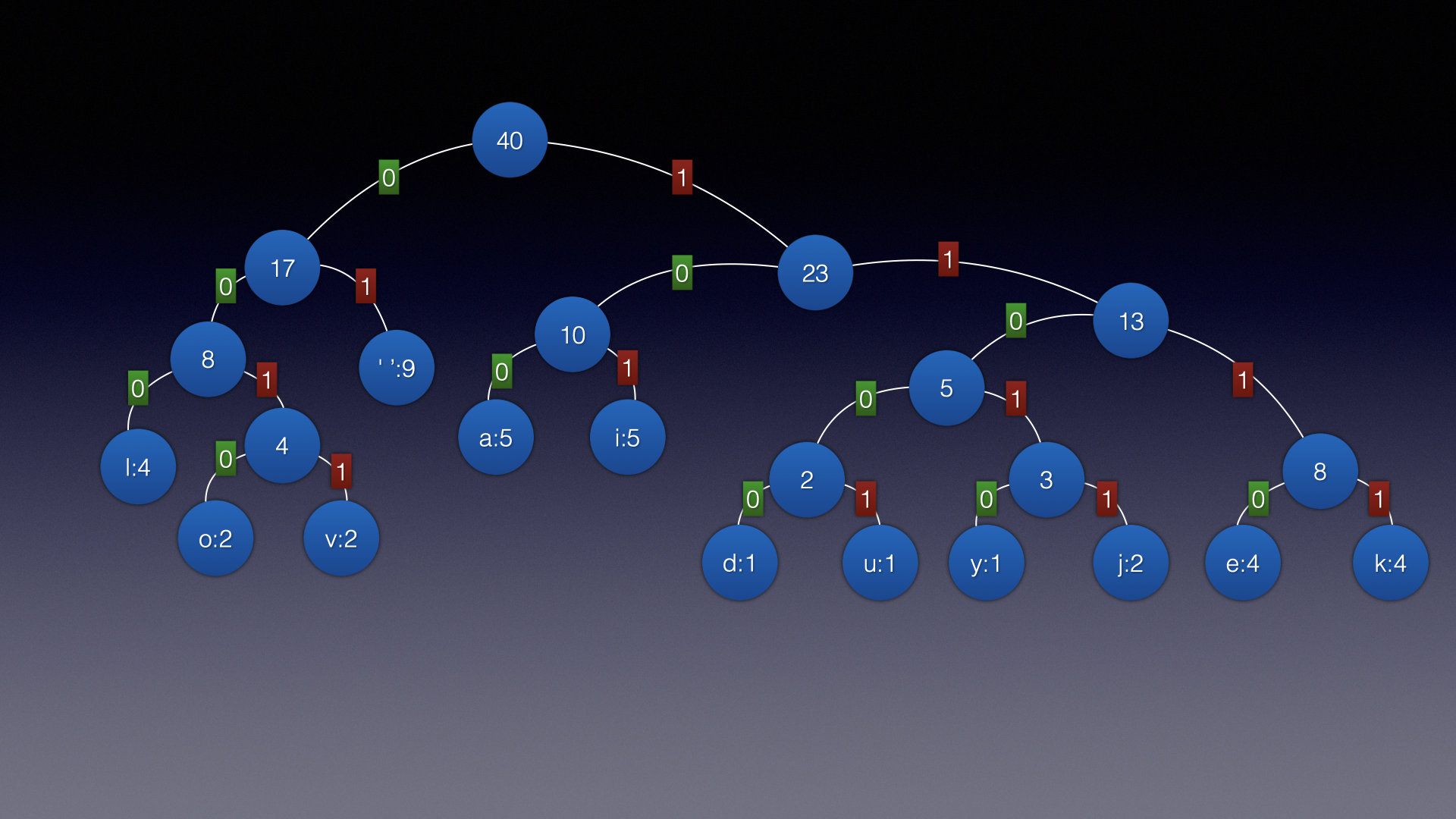
为了好记,以后这张图就叫做赫夫曼对照表
完整代码
/**
* @author: android 超级兵
* @create: 2022-06-14 10:55
**/
public class CreateHuffmanTreeClient
// 存储最终结果
public static HashMap<Byte, String> map = new HashMap<>();
public static void main(String[] args)
String str = "i like like like java do you like a java";
// 生成赫夫曼对照表
HashMap<Byte, String> codingMap = getHuffManChart(str);
System.out.println("赫夫曼表为1: " + codingMap.toString());
/*
* @author: android 超级兵
* @create: 2022/6/14 14:23
* TODO 获取赫夫曼对照表
*/
public static HashMap<Byte, String> getHuffManChart(String str)
// 创建赫夫曼树
// TODO #上面代码展示过了... 就不展示了
// rootNode 是根节点
HuffmanNode rootNode = createHuffman(str.getBytes());
// 生成赫夫曼对照表
return coding(rootNode);
/*
* @author: android 超级兵
* @create: 2022/6/14 13:13
* @param node: root结点
*/
public static HashMap<Byte, String> coding(HuffmanNode node)
// sb用来存储拼接路径
StringBuilder sb = new StringBuilder();
coding(node, "", sb);
// 返回对应的拼接值
return map;
/*
* @author: android 超级兵
* @create: 2022/6/14 11:01
* TODO huffman 前序编码
* @param node: 当前结点 [左子结点0] [右子结点1]
* @param str: 存储拼接路径
*/
public static void coding(HuffmanNode node, String str, StringBuilder sb)
// 结点为null不处理
if (node == null)
return;
// 重点!!
// 创建StringBuilder是为了保存递归之前的数据
// 并且StringBuilder 是可变的(java基础)
StringBuilder sb2 = new StringBuilder(sb);
// 添加每一次的路径
sb2.append(str);
// 不是叶子结点
if (node.by == null)
// 向左递归
coding(node.leftNode, "0", sb2);
// 向右递归
coding(node.rightNode, "1", sb2);
else
// 叶子结点
map.put(node.by, sb2.toString());
最终结果为:
赫夫曼表为1: 32=01, 97=100, 100=11000, 117=11001, 101=1110, 118=11011, 105=101, 121=11010, 106=0010, 107=1111, 108=000, 111=0011
这就是赫夫曼对照表的最终数据
因为是通过Byte来包装的,所以得到的数据全都是ASICC码
也可以通过一段代码转换一下方便查看
/// 为了方便查看,实战中不用
private static HashMap<String, String> byteToStringMap(HashMap<Byte, String> codingMap)
HashMap<String, String> tempMap = new HashMap<>();
codingMap.entrySet().stream().map(new Function<Map.Entry<Byte, String>, Object>()
@Override
public String[] apply(Map.Entry<Byte, String> entry)
return new String[]String.valueOf((char) ((int) entry.getKey())), entry.getValue();
).forEach(new Consumer<Object>()
@Override
public void accept(Object o)
if (o instanceof String[])
String[] s = ((String[]) o);
tempMap.put(s[0], s[1]);
);
return tempMap;
最终效果为:
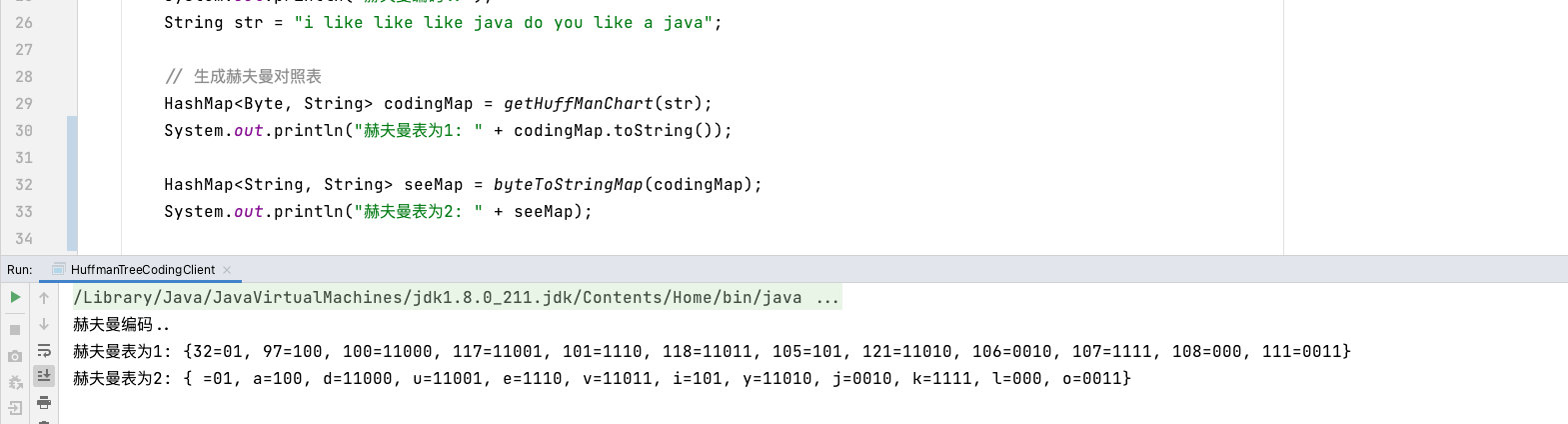
还要注意的是,生成的赫夫曼树是前序编码
意思就是每个编号从左往右数都是唯一的!
原创不易,您的点赞就是对我最大的支持!
其他树结构文章:
- 二叉树入门
- 顺序二叉树
- 线索化二叉树
- 堆排序
- 赫夫曼树(一)
- 赫夫曼树(二) 本篇
- 赫夫曼树(三)
- 二叉排序树(BST)
- 平衡二叉排序树AVL
- 2-3树,2-3-4树,B树 B+树 B*树 了解
- 数据结构与算法:树 红黑树 (十一)
以上是关于数据结构与算法:树 赫夫曼树的主要内容,如果未能解决你的问题,请参考以下文章