机器学习预备知识之概率论(下)
Posted skyWalker_ONLY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习预备知识之概率论(下)相关的知识,希望对你有一定的参考价值。
期望值和方差
随机变量的期望值E(X),也称为平均数或者均值,使用下面的公式计算,这两个公式分别用于计算离散随机变量和连续随机变量的期望值:
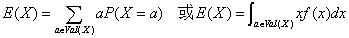
使用上面的公式计算指示器变量(取值要么为1要么为0的随机变量)可得: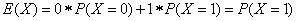
下面是与期望有关的两个重要定理,第一个是期望的线性性质: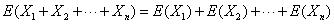
无论随机变量是否相互独立,期望的线性性质都成立。而第二个定义只有在随机变量相互独立时才成立: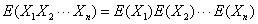
期望其它重要的性质还有:如果C是常数则E(C)=C,E(CX)=CE(X)。
方差用于衡量一个分布的离散程度,使用下面的公式计算方差: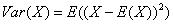
通常使用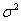 表示方差,使用
表示方差,使用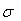 表示标准差,标准差和方差的关系为:
表示标准差,标准差和方差的关系为: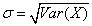
在已知随机变量X的期望时,可以通过下面的公式快速的计算X的方差:
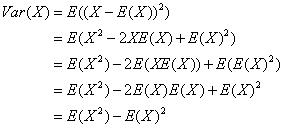
上述推导过程利用了期望的线性性质以及如果C是常数则E(C)=C,E(CX)=CE(X)(此处C为E(X))。方差不是随机变量的线性函数,比如:
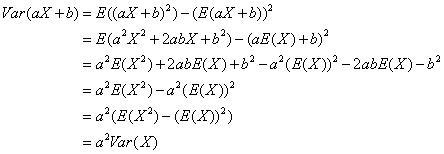
如果随机变量X和Y相互独立,那么有下面的关系:

两个随机变量的协方差定义如下,协方差表示两个随机变量的相关程度:

伯努利、泊松和高斯分布
伯努利分布是最基本的分布之一,服从伯努利分布的随机变量X只能取两个值0和1,通常使用p表示X取值为1的概率,即p=P(X=1),q为X取值为0的概率,即q= P(X=0)=1-p。由于X只能取值0和1,因此常用语表示试验是否成功。由定义可知伯努利的分布为:
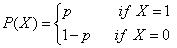
还可以将上面公式概括为: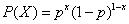 。伯努利分布的期望和方差分别为p和p(1-p),计算过程如下:
。伯努利分布的期望和方差分别为p和p(1-p),计算过程如下:
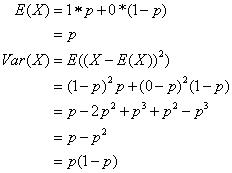
泊松分布是处理事件发生的非常有用的分布,适合于描述单位时间内随机事件发生的次数的概率分布。如某一服务设施在一定时间内受到的服务请求的次数,电话交换机接到呼叫的次数、汽车站台的候客人数、机器出现的故障数、自然灾害发生的次数、DNA序列的变异数、放射性原子核的衰变数等。
泊松分布的参数λ是单位时间(或单位面积)内随机事件的平均发生率,泊松分布的质量函数为: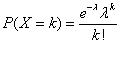
期望和方差都为λ,计算过程如下:
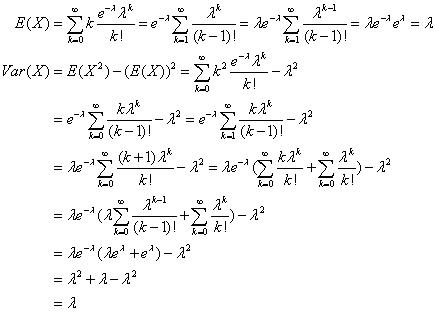
在上述的推导过程中用到了一个重要的公式: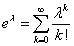 。
。
高斯分布也称为正态分布,是最常使用的分布之一,比如可以在试验次数非常大时用于近似的表示二项式分布,或者在平均发生率很高时近似表示泊松分布,还与大数定理有关。高斯分布由两个参数决定:期望µ和方差σ2,其公式如下:
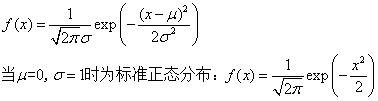
下图为高斯分布的示例图,从该图中可以得知:期望决定正态曲线的中心位置,方差决定正态曲线的陡峭或扁平程度。方差越小,曲线越陡峭;方差越大,曲线越扁平。

在机器学习中经常会处理多变量的高斯分布,k维多变量的高斯分布可以使用参数(µ,Σ)表示,其中µ为期望值的k维向量,Σ为kxk协方差矩阵,其中Σii=Var(Xi),Σij= Cov(X i,X j)。多变量高斯分布的概率密度函数为:
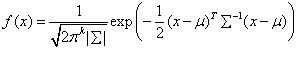
以上是关于机器学习预备知识之概率论(下)的主要内容,如果未能解决你的问题,请参考以下文章