Python入门动态网页分析及抓取
Posted 白玉梁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python入门动态网页分析及抓取相关的知识,希望对你有一定的参考价值。
什么是动态网页?动态网页,就是网页中包含通过异步ajax加载出来的内容!
我们在打开某个网页时,点击右键“查看网页源代码”,会发现有一部分网页上显示的内容,源代码里面没有,而这部分就是通过ajax异步加载出来的,这就是动态网页!
就拿csdn博客来举例:Python入门(一)环境搭建
点开这篇文章,下方有一条评论:

按F12检查元素:
然后选中这条评论内容:

此时,就可以确定评论区域所在位置:<div class="comment-list-box" >...</div>
其实,这也就是所谓的网页分析,通过检查元素,确定你想提取的内容的区域位置,后面就可以通过标签id,name,class或其它属性提取内容!
继续往下看:

这里面包含了一个列表,而那条评论就在其中,此时我们可以在网页中,右键查看网页源代码,然后Ctrl+F,输入“comment-list-box”找到这部分:
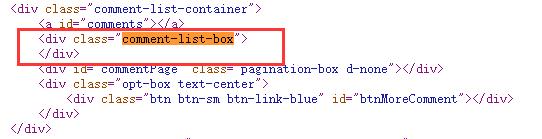
我们会发现,源代码里什么也没有!到这里,是不是就明白了呢?
而如果我们要提取这部分动态内容,仅通过上一篇的方法是无法办到的,除非能分析出来加载动态网页的url,那如何才能简单高效的抓取动态网页内容呢?这里就需要用到动态网页抓取神器:Selenium
Selenium实则是一个web自动化测试工具,可以模拟用户滑动,点击,打开,验证等等一系列网页操作行为,就像一个真实用户在操作一样!这样就可以使用浏览器渲染方法将爬取动态网页,变成爬取静态网页!
安装Selenium:pip install selenium
安装成功后,简单测试:
from selenium import webdriver
# 用selenium打开网页
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
报错:
WebDriverException( selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home
这其实是缺少了谷歌浏览器驱动:chromedriver,下载后放在某个盘符下并记录位置,修改代码重新执行:
driver = webdriver.Chrome(executable_path=r"C:\\chromedriver.exe")
driver.get("https://www.baidu.com")
笔者这里使用的是FireFox浏览器,效果是一样的,当然,你要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\\geckodriver.exe")
driver.get("https://www.baidu.com")

成功打开后,会显示浏览器已被控制!
我们可以在PyCharm中,查看webdriver所提供的方法:

当所提取内容嵌套在frame中时,我们可以driver.switch_to.frame定位,简单的,我们就可以直接用
driver.find_element_by_css_selector、find_element_by_tag_name等等提取内容,方法中带复数s的提取的是列表,不带s的提取的则是单个数据,很好理解,详细使用方法,可以查看官方文档!
仍以csdn博客为例:Python入门(一)环境搭建,爬取这篇文章的评论,上面我们已经分析到评论所在区域:<div class="comment-list-box" >...</div>:
那么我们就可以直接通过find_element_by_css_selector获取该div下的内容:
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r"C:\\geckodriver.exe")
driver.get("https://baiyuliang.blog.csdn.net/article/details/120473414")
comment_list_box = driver.find_element_by_css_selector('div.comment-list-box')
comment_list = comment_list_box.find_element_by_class_name('comment-list')
comment_line_box = comment_list.find_elements_by_class_name('comment-line-box')
for comment in comment_line_box:
span_text = comment.find_element_by_class_name('new-comment').text
print(span_text)
结果:

注意find_element_by_css_selector和find_element_by_class_name的用法区别!
以上是关于Python入门动态网页分析及抓取的主要内容,如果未能解决你的问题,请参考以下文章