关于OIerDB部署与迁移到ACM的一些笔记
Posted 小哈里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于OIerDB部署与迁移到ACM的一些笔记相关的知识,希望对你有一定的参考价值。
文章目录
1、项目地址
https://github.com/OIerDb-ng/OIerDb
https://github.com/OIerDb-ng/OIerDb-data-generator
2、运行项目
OIerDb NG
项目主要基于Typescript,环境为node和yarn。
# 环境安装
nvm install 16.0.0
nvm ls
nvm use 16.0.0
# linux 需要 -g 才可以加到环境变量中
npm i -g yarn
# npm修改代理
npm config get registry
npm config set registry https://registry.npm.taobao.org
npm config list
npm update
#查看代理 #删除代理 #更换淘宝镜像
yarn config list
yarn config delete proxy
yarn config set registry https://registry.npm.taobao.org
# 本地部署
yarn install --frozen-lockfile
yarn build
npm run dev
# Linux 服务器云端部署
# https://blog.csdn.net/qq_41664096/article/details/118961381
# 使用以下命令运行才能外网访问
npx vite --host 0.0.0.0
代码修改:
-
新增public中的文件夹,编译前将编译好的数据文件导入
-
修改数据来源为本地数据
src\\libs\\OIerDb.ts
http://localhost:3000/acmdb -
其他网页的部分看着改
都在src,pages里,稍微学了一点点ts和react语法
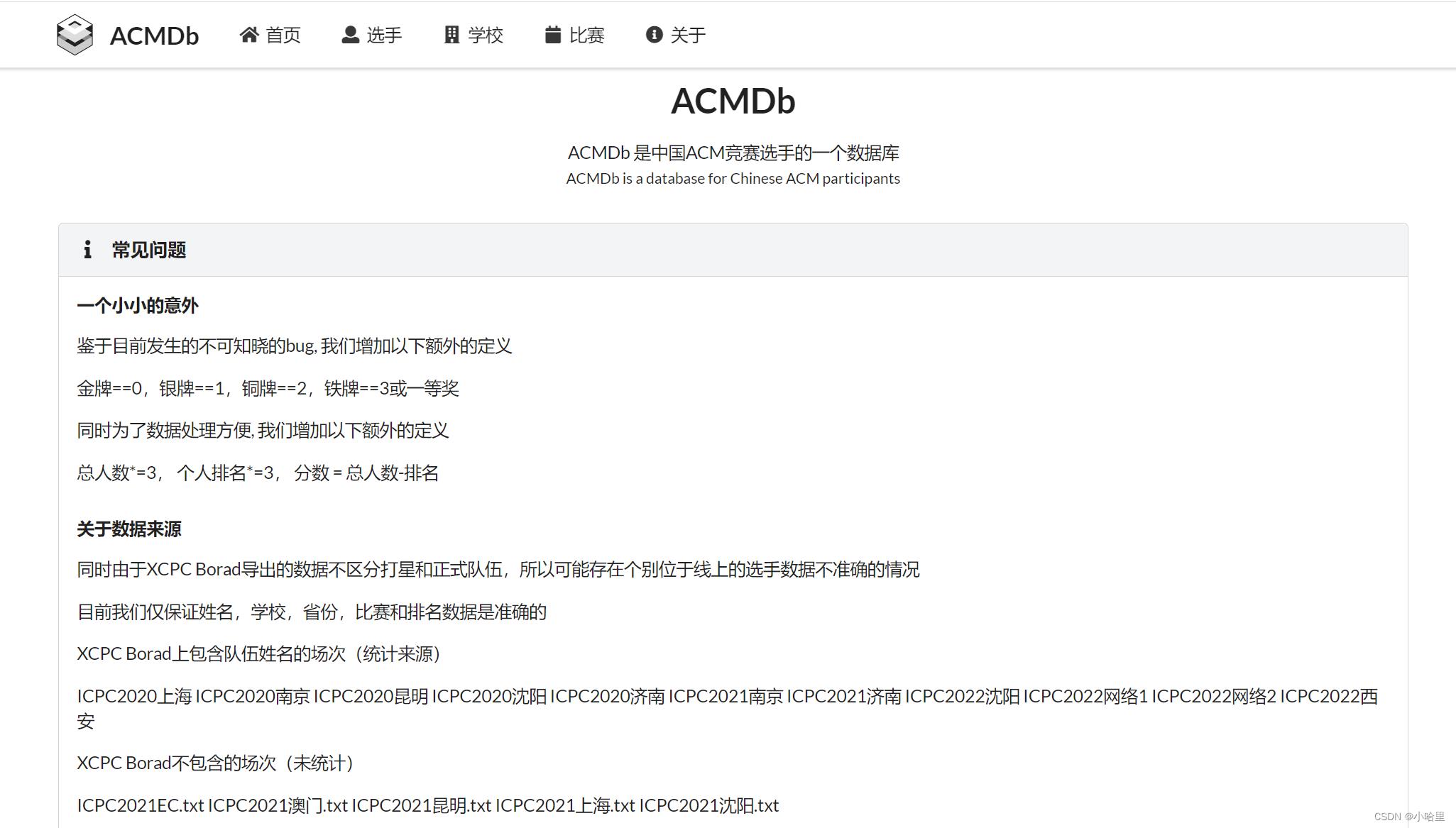
OIerDb-data-generator
本项目主要基于python
# 环境安装
pip install pypinyin requests tqdm -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
conda activate nowcoder
# 1
:= 海象运算符,py>=3.8
conda activate nowcoder
# 2 utils.py, main.py修改
open(class_file_name, 'r', encoding='utf-8')
compute_sha512不用改
# 3 windows 需要修改执行命令
node ./update_static.js
# 生成数据
python main.py

- 数据生成器的代码修改
static静态文件夹里的几个json看着改下以外
oier.py和utils.py里涉及奖牌,相关方面的也要再改下,因为是写在代码里的,没有独立出来特判

3、更换数据
-
XCPC Board
https://board.xcpcio.com/

-
目标格式为:ACMDb-data-generator的相关格式。 主要共3个文件。
-
核心部分,pandas数据处理
# 目标数据
import pandas as pd
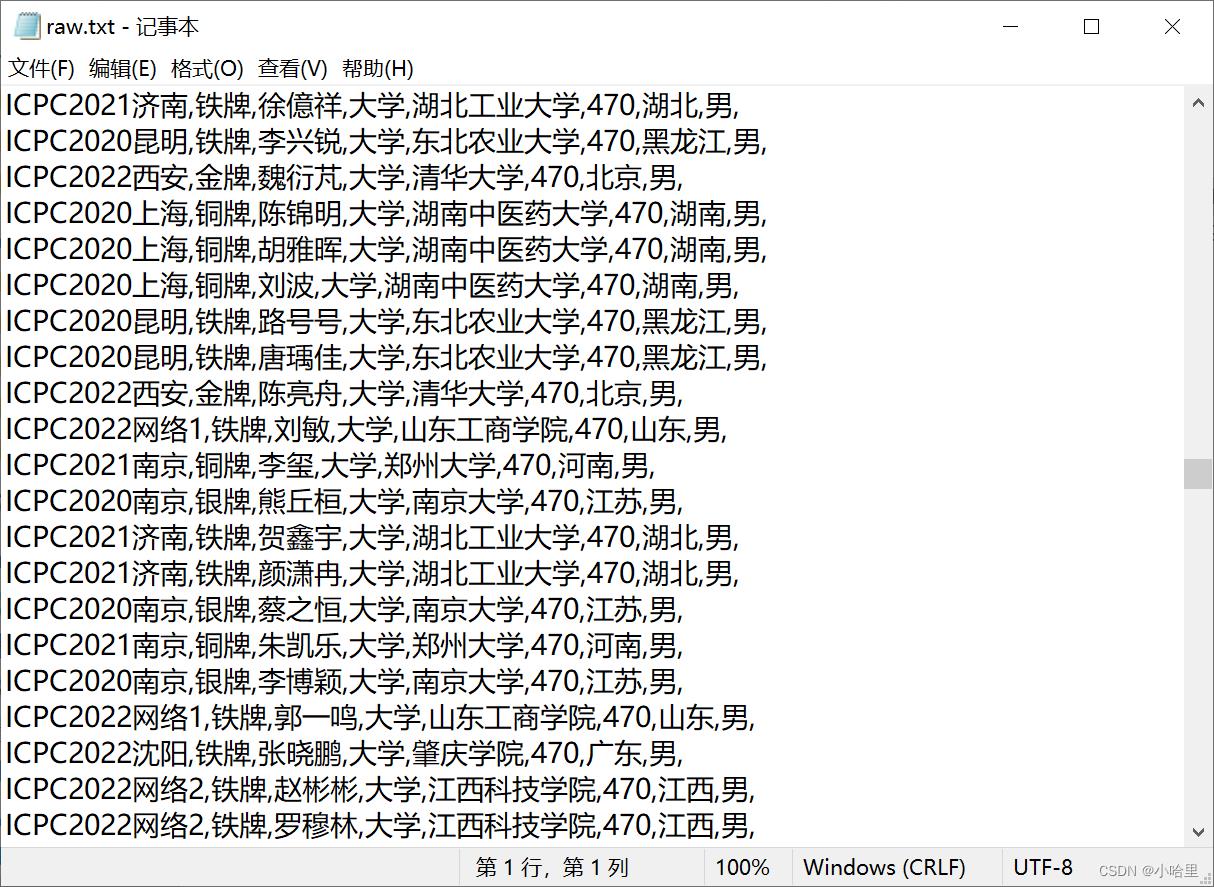
df = pd.read_csv('OIerDb-data-generator\\data\\\\raw.txt', sep = ',')
df
# 打星队,导出的数据中没有特殊标注
# 因此之后只导出正式队名单
# 原始数据
import pandas as pd
import numpy as np
import json
# df = pd.read_json('data/board_47_xian.json')
# df
# 数据读入
competition = 'ICPC2022沈阳'
with open('data/ICPC2022沈阳.txt','r', encoding='utf-8') as f:
data = json.loads(f.read())
data2 = pd.json_normalize(
data,
record_path =['teams','members'],
meta=[
# 'contestName',
['teams','organization'],
['teams','name'],
['teams','place','all']
]
)
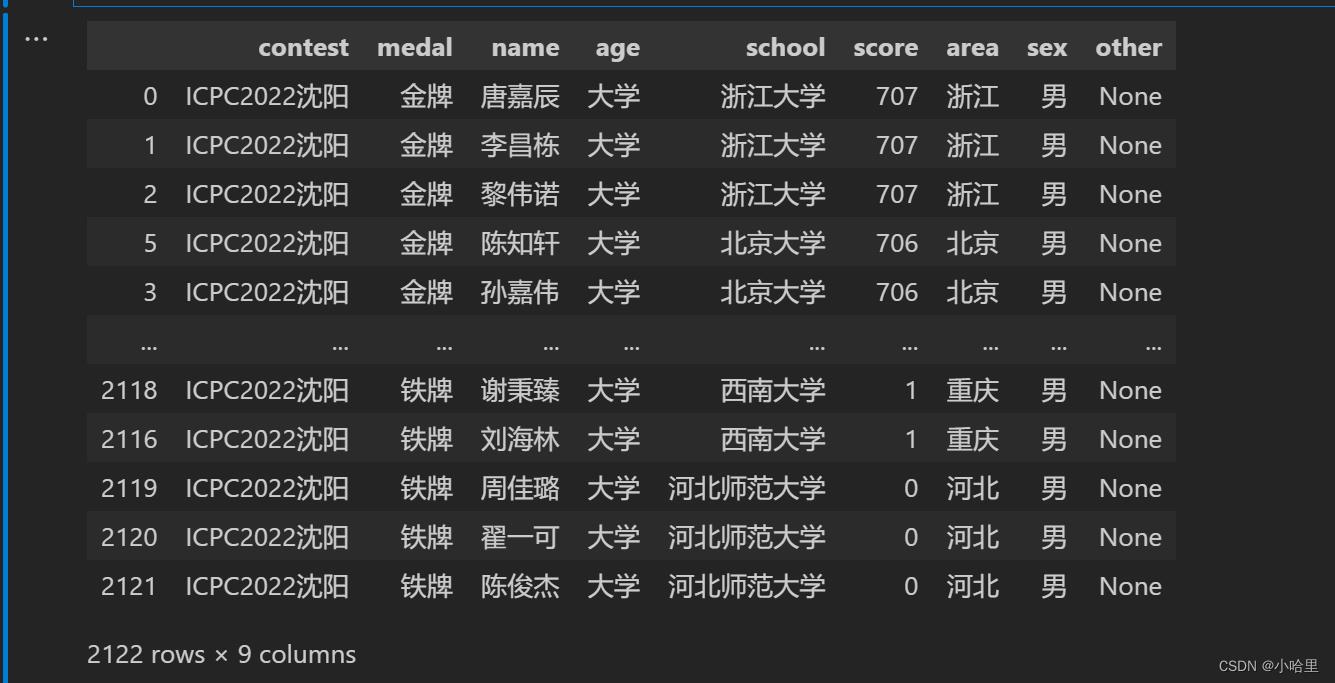
# 数据清洗
data2 = pd.DataFrame(data2)
data2.columns = ['name', 'school', 'teams','rank']
data2['contest'] = competition
data2['sex'] = '男'
data2['age'] = '大学'
data2['other'] = None
data2['medal'] = None
data2.loc[data2['rank']>210 , 'medal'] = '铁牌'
data2.loc[data2['rank']<=210, 'medal'] = '铜牌'
data2.loc[data2['rank']<=105, 'medal'] = '银牌'
data2.loc[data2['rank']<=36, 'medal'] = '金牌'
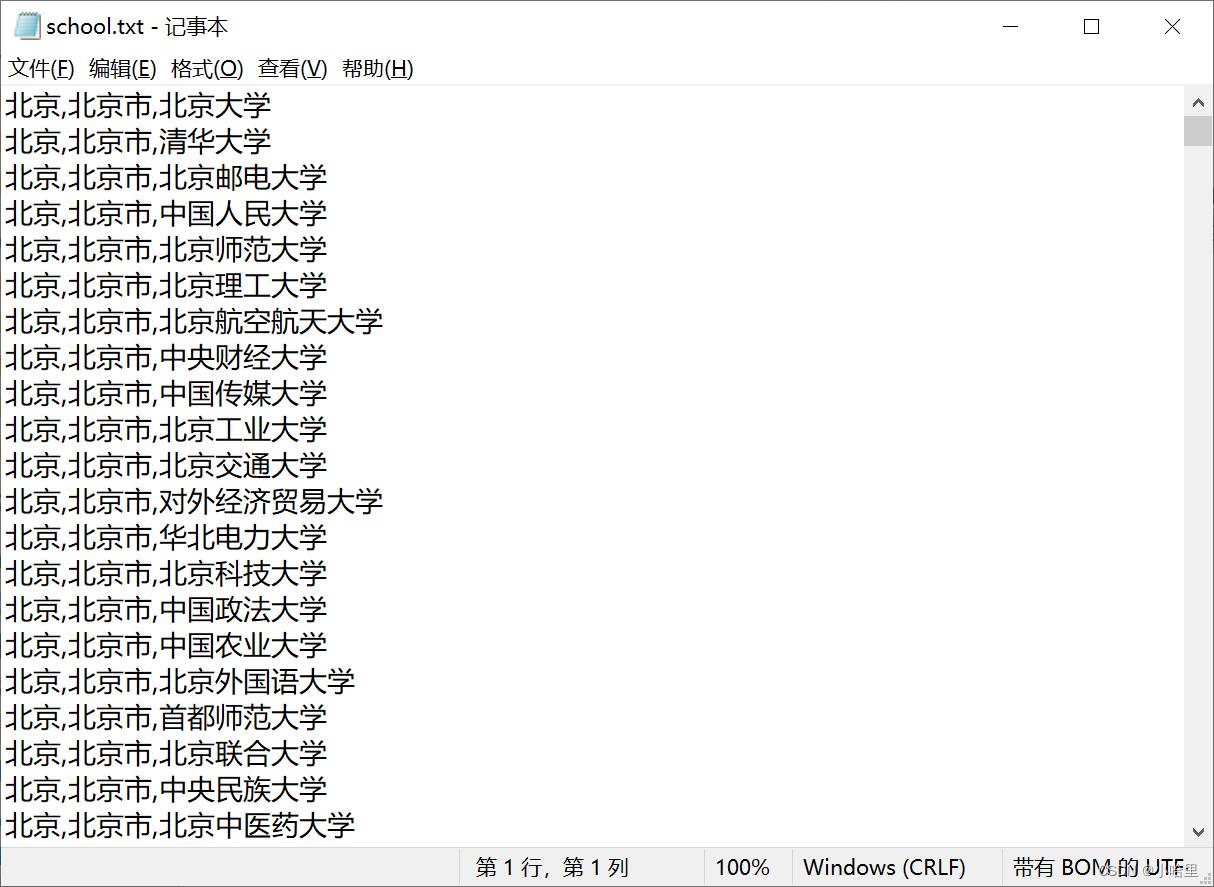
area = pd.read_csv('ACMDb-data-generator\\data\\\\school.txt', sep = ',', header=None)
del area[1]
area.columns = ['area','school']
data2 = pd.merge(data2, area, on='school', how='left') # 类似于vlookup
data2 = data2[['contest', 'medal', 'name', 'age', 'school','rank','area','teams', 'sex','other']] # 排序
del data2['teams'] # 删除teams
data2 = data2.sort_values(by=['rank'],ascending=False) # 排名倒排
mx_value = data2[:1]['rank'].values[0]
data2['rank'] = mx_value-data2['rank'] # 折成分数
data2 = data2.sort_values(by=['rank'],ascending=False) # 排名倒排
data2.columns = ['contest', 'medal', 'name', 'age', 'school','score','area', 'sex','other'] # 改个名
data2
# print(data2)
# data2[data2['rank']<=210]
# data2[data2['teams']=='这么巧,你也是 ikun']
# 写入raw
# data2.to_csv('raw.txt',index=None)
# 批量生产,合规数据
import pandas as pd
import numpy as np
import json
def calc(competition):
# 数据读入
# competition = 'ICPC2022沈阳'
with open('data/'+competition+'.txt','r', encoding='utf-8') as f:
data = json.loads(f.read())
data2 = pd.json_normalize(
data,
record_path =['teams','members'],
meta=[
# 'contestName',
['teams','organization'],
['teams','name'],
['teams','place','all']
]
)
# 数据清洗
data2 = pd.DataFrame(data2)
data2.columns = ['name', 'school', 'teams','rank']
data2['contest'] = competition
data2['sex'] = '男'
data2['age'] = '大学'
data2['other'] = None
data2['medal'] = None
data2.loc[data2['rank']>210 , 'medal'] = '铁牌'
data2.loc[data2['rank']<=210, 'medal'] = '铜牌'
data2.loc[data2['rank']<=105, 'medal'] = '银牌'
data2.loc[data2['rank']<=36, 'medal'] = '金牌'
area = pd.read_csv('ACMDb-data-generator\\data\\\\school.txt', sep = ',', header=None)
del area[1]
area.columns = ['area','school']
data2 = pd.merge(data2, area, on='school', how='left') # 类似于vlookup
data2 = data2[['contest', 'medal', 'name', 'age', 'school','rank','area','teams', 'sex','other']] # 排序
del data2['teams'] # 删除teams
data2 = data2.sort_values(by=['rank'],ascending=False) # 排名倒排
mx_value = data2[:1]['rank'].values[0]
data2['rank'] = mx_value-data2['rank'] # 折成分数
data2 = data2.sort_values(by=['rank'],ascending=False) # 排名倒排
data2.columns = ['contest', 'medal', 'name', 'age', 'school','score','area', 'sex','other'] # 改个名
return data2
# df合并
# df1 = calc("ICPC2020南京")
# df2 = calc("ICPC2020沈阳")
# df3 = pd.concat([df1,df2])
# df3
# json写入
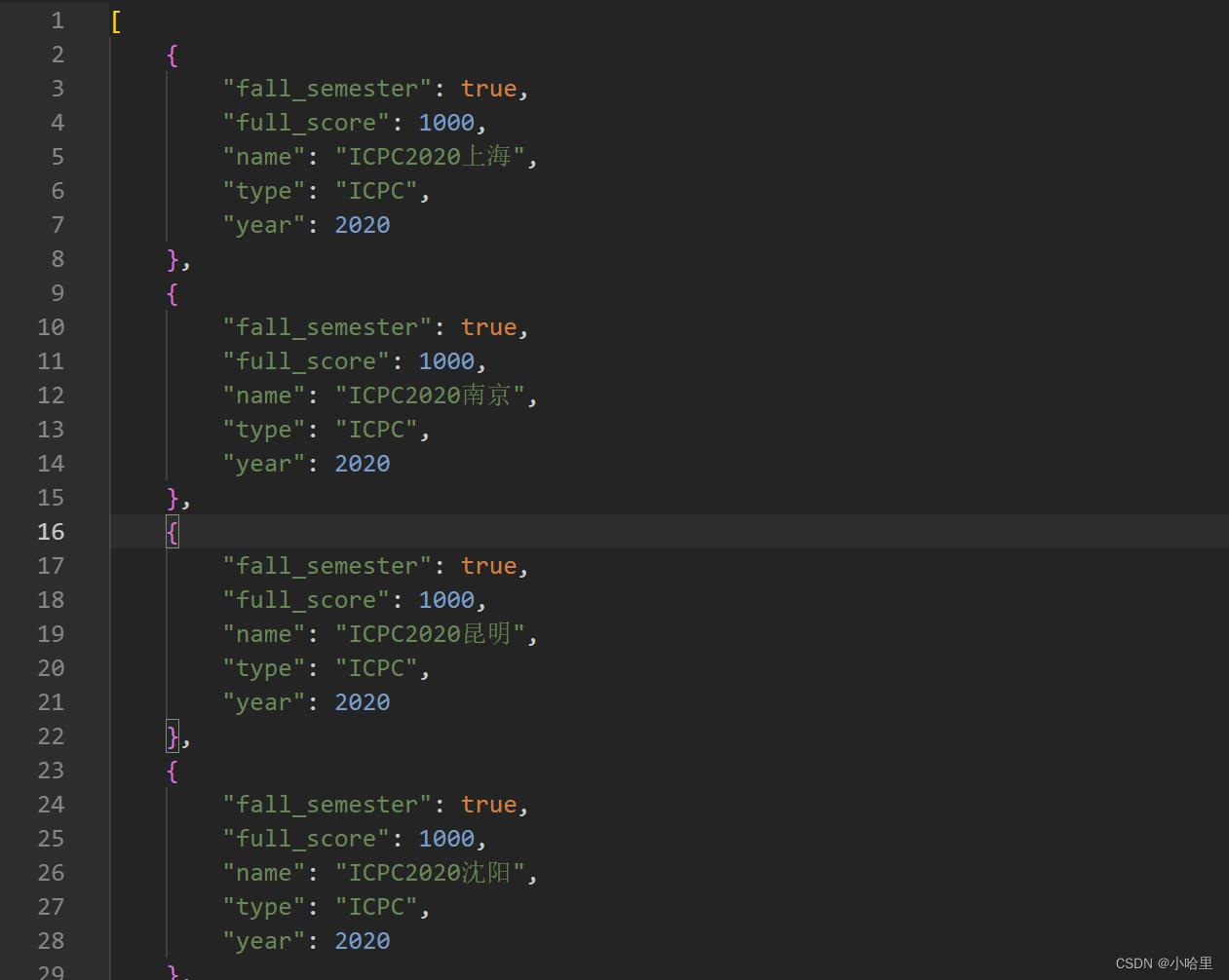
# dc1 = "fall_semester": True,"full_score": 1000,"name": "ICPC2022沈阳","type": "ICPC","year": 2022
# dc2 = "fall_semester": True,"full_score": 1000,"name": "ICPC2022沈阳","type": "ICPC","year": 2022
# dc2['name'] = "ICPC2022西安"
# dc = []
# dc.append(dc1)
# dc.append(dc2)
# print(dc)
# with open('contests.json', mode='w', encoding='utf-8') as f:
# json.dump(dc, f, ensure_ascii=False)
# 批量合并
import os
dc = []
dfx = []
ok = 1
path = os.listdir(os.getcwd()+"\\data")
for p in path:
if not os.path.isdir(p):
print(p[:-4])
dd = "fall_semester": True,"full_score": 1000,"name": "ICPC2022沈阳","type": "ICPC","year": 2022
dd['name'] = p[:-4]
dd['year'] = int(p[:-4][4:8])
dc.append(dd)
dfy = calc(p[:-4])
if ok == 1:
dfx = dfy
ok = 0
else :
dfx = pd.concat([dfx,dfy])
# print(dfx)
dfx = dfx.sort_values(by=['score'],ascending=False) # 排名倒排
dfx = dfx[dfx['name'] != 'XXX']
# 写入文件
dfx.to_csv('raw.txt',index=None)
with open('contests.json', mode='w', encoding='utf-8') as f:
json.dump(dc, f, ensure_ascii=False)
# 队伍质量判断,原始数据
import pandas as pd
import numpy as np
import json
def calc(competition):
# 数据读入
# competition = 'ICPC2022沈阳'
with open('data/'+competition+'.txt','r', encoding='utf-8') as f:
data = json.loads(f.read())
data2 = pd.json_normalize(
data,
record_path =['teams','members'],
meta=[
# 'contestName',
['teams','organization'],
['teams','name'],
['teams','place','all']
]
)
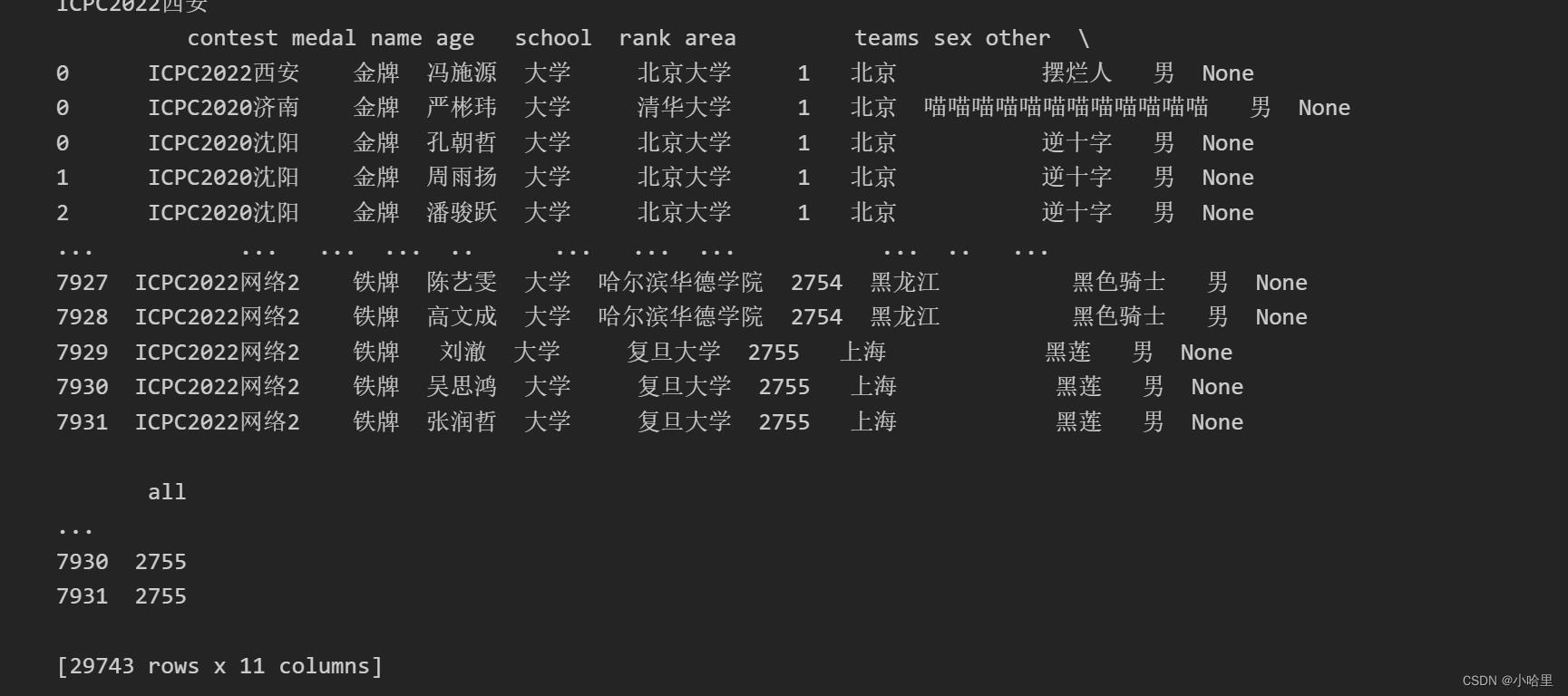
# 数据清洗
data2 = pd.DataFrame(data2)
data2.columns = ['name', 'school', 'teams','rank']
data2['contest'] = competition
data2['sex'] = '男'
data2['age'] = '大学'
data2['other'] = None
data2['medal'] = None
data2.loc[data2['rank']>210 , 'medal'] = '铁牌'
data2.loc[data2['rank']<=210, 'medal'] = '铜牌'
data2.loc[data2['rank']<=105, 'medal'] = '银牌'
data2.loc[data2['rank']<=36, 'medal'] = '金牌'
area = pd.read_csv('ACMDb-data-generator\\data\\\\school.txt', sep = ',', header=None)
del area[1]
area.columns = ['area','school']
data2 = pd.merge(data2, area, on='school', how='left') # 类似于vlookup
data2 = data2[['contest', 'medal', 'name', 'age', 'school','rank','area','teams', 'sex','other']] # 排序
# del data2['teams'] # 删除teams
data2 = data2.sort_values(by=['rank'],ascending=False) # 排名倒排
mx_value = data2[:1]['rank'].values[0]
data2['rank'] = data2['rank'] # 折成分数
data2['all'] = mx_value
# data2.loc['all'] = mx_value
# print(mx_value)
# data2['all'] = mx_value
# data2 = data2.sort_values(by=['rank'],ascending=False) # 排名倒排
# data2.columns = ['contest', 'medal', 'name', 'age', 'school', 'rank','area', 'sex','other','all'] # 改个名
return data2
# 批量合并
import os
dc = []
dfx = []
ok = 1
path = os.listdir(os.getcwd()+"\\data")
for p in path:
if not os.path.isdir(p):
print(p[:-4])
dd = "fall_semester": True,"full_score": 1000,"name": "ICPC2022沈阳","type": "ICPC","year": 2022
dd['name'] = p[:-4]
dd['year'] = int(p[:-4][4:8])
dc.append(dd)
dfy = calc(p[:-4])
if ok == 1:
dfx = dfy
ok = 0
else :
dfx = pd.concat([dfx,dfy])
# print(dfx)
dfx = dfx.sort_values(by=['rank'],ascending=True) # 排名倒排
print(dfx)
# 写入文件
dfx.to_csv('raw.csv')

以上是关于关于OIerDB部署与迁移到ACM的一些笔记的主要内容,如果未能解决你的问题,请参考以下文章