机器学习入门系列04,Gradient Descent(梯度下降法)
Posted yofer张耀琦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习入门系列04,Gradient Descent(梯度下降法)相关的知识,希望对你有一定的参考价值。
Gitbook整理地址:https://yoferzhang.gitbooks.io/machinelearningstudy/content/20170327ML04GradientDescent.html
什么是Gradient Descent(梯度下降法)?
在第二篇文章中有介绍到梯度下降法的做法,传送门:机器学习入门系列02,Regression 回归:案例研究
Review: 梯度下降法
在回归问题的第三步中,需要解决下面的最优化问题:
θ∗=argminθL(θ)
L:lossfunction(损失函数)
θ:parameters(参数)
这里的parameters是复数,即 θ 指代一堆参数,比如上篇说到的 w 和
b 。
我们要找一组参数 θ ,让损失函数越小越好,这个问题可以用梯度下降法解决:
假设 θ 有里面有两个参数 θ1,θ2
随机选取初始值 θ0=[θ01θ02] ,这里可能某个平台不支持矩阵输入,看下图就好。
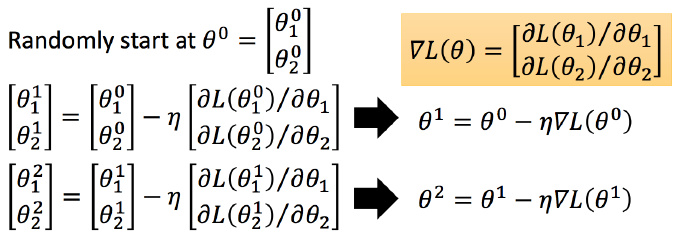
然后分别计算初始点处,两个参数对
L
的偏微分,然后
η 叫做Learning rates(学习速率)
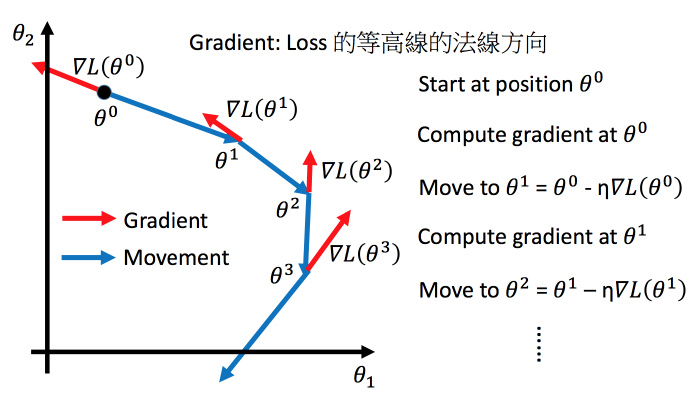
上图举例将梯度下降法的计算过程进行可视化。
Tip1:调整 learning rates(学习速率)
小心翼翼地调整 learning rate
举例:

上图左边黑色为损失函数的曲线,假设从左边最高点开始,如果 learning rate 调整的刚刚好,比如红色的线,就能顺利找到最低点。如果 learning rate 调整的太小,比如蓝色的线,就会走的太慢,虽然这种情况给足够多的时间也可以找到最低点,实际情况可能会等不及出结果。如果 learning rate 调整的有点大,比如绿色的线,就会在上面震荡,走不下去,永远无法到达最低点。还有可能非常大,比如黄色的线,直接就飞出去了,update参数的时候只会发现损失函数越更新越大。
虽然这样的可视化可以很直观观察,但可视化也只是能在参数是一维或者二维的时候进行,更高维的情况已经无法可视化了。
解决方法就是上图右边的方案,将参数改变对损失函数的影响进行可视化。比如 learning rate 太小(蓝色的线),损失函数下降的非常慢;learning rate 太大(绿色的线),损失函数下降很快,但马上就卡住不下降了;learning rate特别大(黄色的线),损失函数就飞出去了;红色的就是差不多刚好,可以得到一个好的结果。
自适应 learning rate
举一个简单的思想:随着次数的增加,通过一些因子来减少 learning rate
- 通常刚开始,初始点会距离最低点比较远,所以使用大一点的 learning rate
- update好几次参数之后呢,比较靠近最低点了,此时减少 learning rate
- 比如
ηt=η/t+1‾‾‾‾‾√
,
t
是次数。随着次数的增加,
ηt 减小
但 learning rate 不能是 one-size-fits-all ,不同的参数需要不同的 learning rate
Adagrad 算法
Adagrad 是什么?
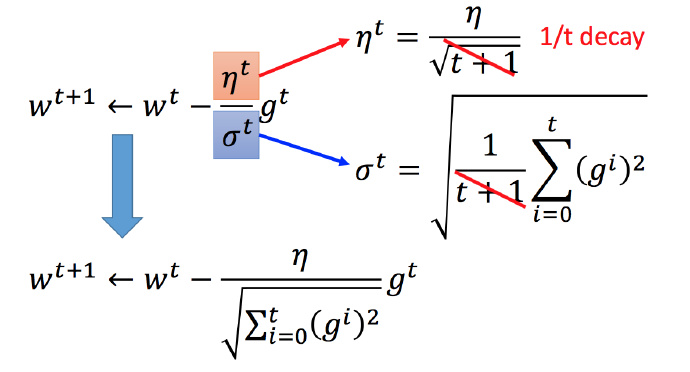
每个参数的学习率都把它除上之前微分的均方根。解释:
普通的梯度下降为:
wt+1←wt−ηtgt
ηt=ηt+1‾‾‾‾‾√
w 是一个参数
Adagrad 可以做的更好:
gt=∂L(θt)∂w
σt :之前参数的所有微分的均方根,对于每个参数都是不一样的。
Adagrad举例
下图是一个参数的更新过程

将 Adagrad 的式子进行化简:
Adagrad 存在的矛盾?
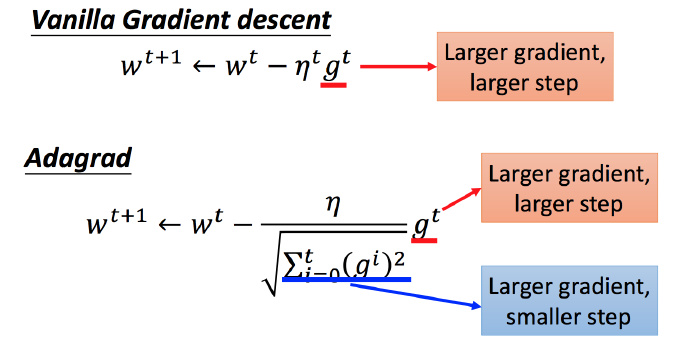
在 Adagrad 中,当梯度越大的时候,步伐应该越大,但下面分母又导致当梯度越大的时候,步伐会越小。
下图是一个直观的解释:

下面给一个正式的解释:
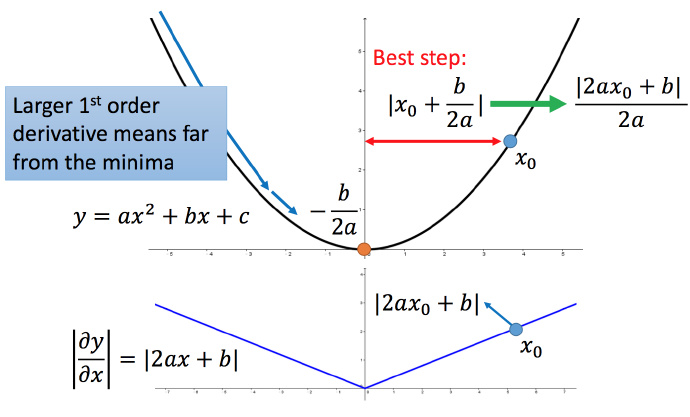
比如初始点在