K8s 场景下 Logtail 组件可观测方案升级-Logtail 事件监控发布
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K8s 场景下 Logtail 组件可观测方案升级-Logtail 事件监控发布相关的知识,希望对你有一定的参考价值。
背景
随着K8s和云的普及,越来越多的公司将业务系统部署到云上,并且使用K8s来部署应用。Logtail是SLS提供的日志采集Agent,能够非常好的适应K8s下各种场景的日志采集,支持通过DaemonSet方式和Sidecar方式采集Kubernetes集群的容器标准输出或者文件日志。Logtail作为一个K8s场景下非常重要一个组件,其自身运行状态需要有更好的可观测方案。
K8s中Logtail管控原理
K8s场景下,除了控制台管控之外,Logtail还提供了环境变量和CRD两种配置方式,用来配置容器日志采集。
环境变量方式
环境变量的配置方式,参考文档
环境变量方式管控原理:
- Logtail会去扫描所有的容器信息,并获取容器中的环境变量信息
- 过滤其中包含aliyun_logs_前缀的字段,然后组合成采集配置信息,Logtail同时会用改环境变量作为采集配置中容器过滤的条件
- Logtail端收到采集配置的变化后,会调整本地的采集配置,从而实现整个控制流程的闭环。
CRD方式


CRD方式创建采集配置流程,参考文档。
CRD配置原理如上图所示:
- K8S内部会注册自定义资源(CRD,CustomResourceDefinition)AliyunLogConfig,并部署alibaba-log-controller
- CR对象创建/变化/删除之后,alibaba-log-controller会监听到CR对象的变化,从而对CR对象中指定的logstore、采集配置进行相应的操作
- Logtail端收到采集配置的变化后,会调整本地的采集配置,从而实现整个控制流程的闭环。
无论是环境变量的配置方式,还是CRD的配置方式,Logtail的状态都是比较难观测的。
- 环境变量配置之后,无论配置的是否正确,都不会影响业务容器的正常运行。但是logtail是否读到了环境变量里的配置并且进行了正确的处理,这个用户只能看到最终的结果。如果配置错了,用户也不能拿到及时的反馈,只能看到SLS控制台上,logstore没有创建出来或者采集配置没有创建出来,中间到底哪一个步骤报错了,用户也无法感知。
- 一个CR配置之后,从K8s的角度来看,只能看到CR对象创建成功了。但是CRD对象创建成功之后,alibaba-log-controller内的处理流程,对于用户来讲,就像黑盒一样。如果出现异常,用户并不清楚究竟是中间哪一步出了问题。
基于以上的问题,SLS针对Logtail本身以及Logtail的管控组件alibaba-log-controller,采用K8s事件的方式,将处理流程中的关键事件透出,从而让用户能够更清楚的感知其中发生的异常。
Logtail事件监控实战
限制说明
- alibaba-log-controller版本大于等于0.3.2
- logtail版本大于等于1.1.2
- logtail中目前涵盖的事件
- 创建project、创建logstore、创建采集配置
- alibaba-log-controller中涵盖的事件
- 创建project、创建logstore、创建采集配置、创建索引、创建ingress日志中心、checkpoint写入
开启Logtail事件监控
未开启过K8s事件中心
步骤一:创建K8s事件中心
- 登录日志服务控制台。

- 在日志应用区域的云产品Lens页签中,单击K8s事件中心。
- 在事件中心管理页面,单击添加。
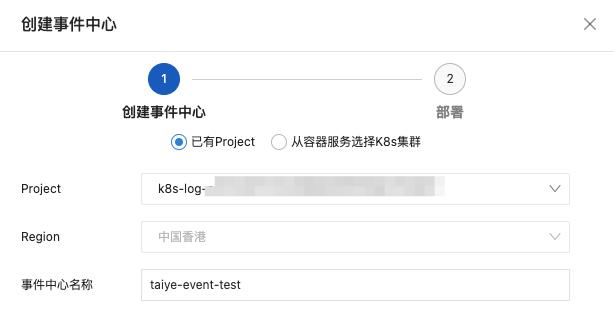
- 在添加事件中心页面,配置相关参数。
- 如果选择已有Project,则从Project下拉框中选择已创建的Project,用于管理K8s事件中心相关资源(Logstore、仪表盘等)。
- 如果选择从容器服务选择K8s集群,则从K8s集群下拉框中选择已创建的K8s集群。通过此方式创建K8s事件中心,日志服务默认创建一个名为k8s-log-cluster-id的Project,用于管理K8s事件中心相关资源(Logstore、仪表盘等)。
- 单击下一步。
步骤二:部署eventer和node-problem-detector
您需要在Kubernetes集群中配置eventer和node-problem-detector后才能正常使用K8s事件中心。
- 阿里云Kubernetes配置方式阿里云Kubernetes应用市场中的ack-node-problem-detector已集成eventer和node-problem-detector功能,您只需要部署该组件即可,该组件详细部署请参见事件监控。
- 登录容器服务控制台。
- 在左侧导航栏中,选择运维管理 > 组件管理,日志与监控下,单击ack-node-problem-detector。

- 单击安装、确认。

- 自建Kubernetes配置方式
- 部署eventer。更多信息,请参见采集Kubernetes事件。
- 部署node-problem-detector。更多信息,请参见Github。
已开启过K8s事件中心
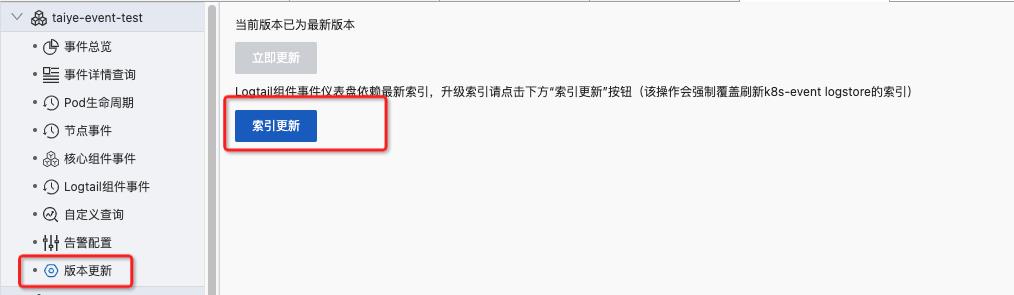
由于Logtail事件监控依赖了比较新的索引,因此可以在K8s事件中心页面,点击版本升级的选项,里面有一个索引更新的按钮,点击之后,即可以开启新的索引字段。
Logtail事件监控大盘

Logtail事件监控大盘将各个步骤的结果完整展示出来,并且以时间轴的方式,展示各个事件的先后顺序,同时支持用Project、Logstore、采集配置名参数进行过滤。

针对异常的事件,Logtail事件监控大盘会把异常事件的详情展示出来:
| 详情字段 | 含义 |
| time | 事件发生的时间 |
| source | 事件来源,主要有alibaba-log-controller和logtail |
| resourceName | 主要针对CRD场景下,CRD的名字 |
| configName | 采集配置的名字 |
| project | 采集配置所属的project |
| logstore | 采集配置所属的logstore |
| reason | 事件产生的原因 |
| message | 事件的详细信息 |
| errorCode | 异常步骤的错误码 |
| errorMessage | 异常步骤的报错信息 |
| requestId | 异常步骤的请求标识 |

针对采集配置的创建、变更、删除操作,Logtail事件监控提供了相关的记录,用于进行操作审计
| 详情字段 | 含义 |
| time | 事件发生的时间 |
| source | 事件来源,主要有alibaba-log-controller和logtail |
| action | 创建、变更或者删除 |
| level | normal或者warning |
| configName | 采集配置的名字 |
| project | 采集配置所属的project |
| logstore | 采集配置所属的logstore |
| logtailconfig | 采集配置详情 |
应用案例
场景1: 通过CRD配置,logstore数量超过quota限制
一个CRD配置如下:
apiVersion: log.alibabacloud.com/v1alpha1
kind: AliyunLogConfig
metadata:
name: simple-index-crd-example-0909-no-1
spec:
logstore: logstore-quota-test-0909-no-1
logtailConfig:
inputType: plugin
configName: simple-index-crd-example-0909-no-1
inputDetail:
plugin:
inputs:
-
type: service_docker_stdout
detail:
Stdout: true
Stderr: true
IncludeEnv:
collect_crd_index_out: trueapply之后发现CRD已经创建成功,但是logstore没有创建出来。
通过限制Project、Logstore和采集配置名的条件

打开异常事件详情列表,可以清楚看到创建logstore步骤的异常情况,错误码是ProjectQuotaExceed,报错详情是:project k8s-log-c4551a67027d248bfb049765de783e647, shard count quota exceed。由此,可以直接找到SLS值班的同学,提升quota,从而解决这个问题

场景2: 通过CRD配置,关键参数填写错误
一个CRD配置如下:
apiVersion: log.alibabacloud.com/v1alpha1
kind: AliyunLogConfig
metadata:
name: simple-index-crd-example-0909-mock-4
spec:
logstore: logstore-quota-test-0909-mock-4
logtailConfig:
inputType: pluginss
configName: simple-index-crd-example-0909-mock-4
inputDetail:
plugin:
inputs:
-
type: service_docker_stdout
detail:
Stdout: true
Stderr: true
IncludeEnv:
collect_crd_index_out: trueapply之后发现CRD已经创建成功,但是logstore和采集配置也都是没有创建出来。
通过限制Project、Logstore和采集配置名的条件

打开异常事件详情列表,可以清楚看到创建采集配置步骤的异常情况,错误信息里提示:invalid input type : pluginss

由此可以知道原来是CRD里inputType字段的取值有问题,通过采集配置事件详情列表里的记录,也可以清楚看到通过CRD转换之后的采集配置数据。

场景3: 通过环境变量和CRD方式针对同一个Project/Logstore采集配置进行变更,导致的配置冲突
在多人维护一个K8s集群的时候,有可能两个人针对同一份采集配置,通过不同的配置方式进行了修改,这样的问题排查起来往往很麻烦。
我们模拟这样一个场景:
- 部署一个测试的Pod,环境变量配置如下:


可以看到logstore和采集配置已经创建成功
- CRD配置如下:
apiVersion: log.alibabacloud.com/v1alpha1
kind: AliyunLogConfig
metadata:
name: taiye-test-0707
spec:
logstore: taiye-test-0707
logtailConfig:
inputType: plugin
configName: taiye-test-0707
inputDetail:
plugin:
inputs:
-
type: service_docker_stdout
detail:
Stdout: true
Stderr: true
IncludeEnv:
conflict-test: trueapply之后发现CRD已经创建成功,采集配置也被覆盖掉了。

通过Logtail事件大盘里的事件时间轴,我们可以清楚的看到两次配置变更操作,一次是通过Logtail产生的,一次是通过alibaba-log-controller产生的。


通过事件详情,我们也可以看到两次变更的配置参数是不一样的,有了这样的监控数据,能够知道什么时间的配置变更导致了冲突。

通过命令行查看实时事件
K8s event在K8s中默认只保留一小时,在进行命令行操作的时候,可以通过kubectl命令直接查看实时的事件
kubectl get event -A
这样可以得到当前集群中实时的事件列表,如果想查看事件的详细信息,可以使用如下命令,输出json格式的事件,里面包含了详细的信息
kubectl get events -o json
本文为阿里云原创内容,未经允许不得转载
以上是关于K8s 场景下 Logtail 组件可观测方案升级-Logtail 事件监控发布的主要内容,如果未能解决你的问题,请参考以下文章