4Redis高级数据结构(BitmapsHyperLogLogGEO)
Posted *King*
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了4Redis高级数据结构(BitmapsHyperLogLogGEO)相关的知识,希望对你有一定的参考价值。
一、Bitmaps
1、Bitmaps
Bitmaps 本身不是一种数据结构,实际上它就是字符串,但是它可以对字符 串的位进行操作。
Bitmaps 单独提供了一套命令,所以在 Redis中使用 Bitmaps和使用字符串的 方法不太相同。可以把 Bitmaps 想象成一个以位为单位的数组,数组的每个单元只能存储 0 和 1,数组的下标在 Bitmaps 中叫做偏移量。
(1)setbit设置值
设置键的第offset个位的值(从0算起)
setbit key offset value
假设现在有20个用户,userid=0,2,5,6,10的用户对网站进行了访问,存储键名为u:v:日期

(2)getbit获取值
获取键的第offset位的值(从0开始算)
getbit key offset
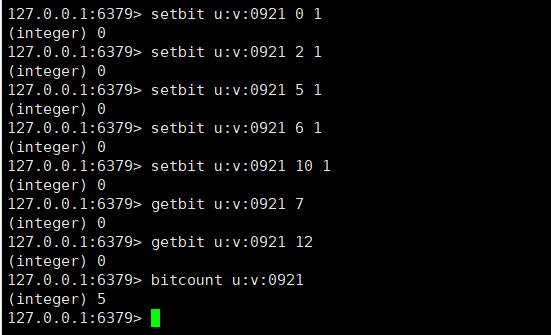
比如获取第7位用户是否在09-21这天访问过,返回0说明没有访问,当offset不存在时,也会返回0

(3)bitcount获取Bitmaps指定范围值为1的个数
bitcount [start] [end]
比如计算09-21这天的独立访问用户数量
[start]和[end]代表起始和结束字节数
(4)bitop Bitmaps 间的运算
bitop 是一个复合操作,它可以做多个 Bitmaps 的 and(交集)or(并 集)not(非)xor(异或)操作并将结果保存在 destkey 中。
bitops 有两个选项[start]和[end],分别代表起始字节和结束字节。
bitop op destkey key [key . ...]
比如计划09-21当天访问网站的最小用户id
Bitmaps优势:
假设网站有 1 亿用户,每天独立访问的用户有 5 千万,如果每天用集合类型 和 Bitmaps 分别存储活跃用户,很明显,假如用户 id 是 Long 型,64 位,则集合类型占据的空间为 64 位 x50 000 000= 400MB,而 Bitmaps 则需要 1 位×100 000 000=12.5MB,使用 Bitmaps 能节省很多的内存空间。
2、布隆过滤器
使用场景:
1、目前有10亿数量的自然数,乱序排列,需要对其排序
2、快速在亿级黑名单中定位URL地址是否在黑名单内
3、需要进行用户登录行为分析,来确定用户的活跃情况
4、网络爬虫-如何判断 URL 是否被爬过
5、快速定位用户属性(黑名单、白名单等)
6、数据存储在磁盘中,如何避免大量的无效 IO
位图法:
位图法就是bitmap的缩写,就是用每一位来存放某种状态,适用于大规模数据,但数据状态又不是很多的情况,通常是用来判断某个数据存不存在的
布隆过滤器详解:
bitmap相比于传统的List、Set、Map等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
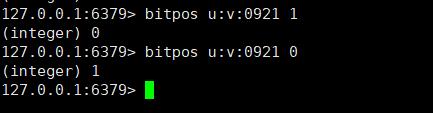
通过一个 Hash 函数将一个元素映射成一个位阵列(Bit Array)中的一个点。这样一来,我们只要看看这个点是不是 1 就知道可以集合中有没有它了。这就是布隆过滤器的基本思想。
Hash 面临的问题就是冲突。假设 Hash 函数是良好的,如果我们的位阵列 长度为 m 个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能 容纳 m/100 个元素。显然这就不叫空间有效了(Space-efficient)。解决方法也简单,就是使用多个 Hash,如果它们有一个说元素不在集合中,那肯定就不在。
布隆过滤器的缺点
为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了1 ,那么程序还是会判断 这个值存在。
布隆过滤器判断存在的不一定存在,但是判断不存在的一定不存在。
布隆过滤器的实现
(1)Redis 中的布隆过滤器
插件形式:
下载redisbloom插件:
wget https://github.com/RedisLabsModules/rebloom/archive/v1.1.1.tar.gz
解压并安装,生成.so文件:
tar -zxvf v1.1.1.tar.gz
cd redisbloom-1.1.1/
make
在redis配置文件(redis.conf)中加入该模块:
vim redis.conf
loadmodule /usr/local/redis/redisbloom-1.1.1/rebloom.so
相关的操作命令:
bf.reserve 创建 Filter,其有 3 个参数,key,error_rate, initial_size,错误 率越低,需要的空间越大,error_rate 表示预计错误率,initial_size 参数表示预计 放入的元素数量,当实际数量超过这个值时,误判率会上升,所以需要提前设置 一个较大的数值来避免超出。默认的 error_rate 是 0.01,initial_size 是 100 bf.add 增加
bf.exists 判断是否存在
bf.madd 批量增加
bf.mexists 批量判断
目前 jedis 不支持布隆过滤器,需要 JRedisBloom
https://github.com/RedisLabs/JReBloom
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>jrebloom</artifactId>
<version>2.1.0</version>
</dependency>
(2)访Google的布隆过滤器实现
加入maven依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1.1-jre</version>
</dependency>
RedisBloomFilter
import com.google.common.hash.Funnels;
import com.google.common.hash.Hashing;
import com.google.common.primitives.Longs;
import org.springframework.beans.factory.annotation.Autowired;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.Pipeline;
import java.nio.charset.Charset;
/*仿Google的布隆过滤器实现,基于redis支持分布式*/
public class RedisBloomFilter
public final static String RS_BF_NS = "rbf:";
private int numApproxElements; /*预估元素数量*/
private double fpp; /*可接受的最大误差*/
private int numHashFunctions; /*自动计算的hash函数个数*/
private int bitmapLength; /*自动计算的最优Bitmap长度*/
@Autowired
private JedisPool jedisPool;
/**
* 构造布隆过滤器
* @param numApproxElements 预估元素数量
* @param fpp 可接受的最大误差
* @return
*/
public RedisBloomFilter init(int numApproxElements,double fpp)
this.numApproxElements = numApproxElements;
this.fpp = fpp;
/*位数组的长度*/
this.bitmapLength = (int) (-numApproxElements*Math.log(fpp)/(Math.log(2)*Math.log(2)));
/*算hash函数个数*/
this.numHashFunctions = Math.max(1, (int) Math.round((double) bitmapLength / numApproxElements * Math.log(2)));
return this;
/**
* 计算一个元素值哈希后映射到Bitmap的哪些bit上
* 用两个hash函数来模拟多个hash函数的情况
* * @param element 元素值
* @return bit下标的数组
*/
private long[] getBitIndices(String element)
long[] indices = new long[numHashFunctions];
/*会把传入的字符串转为一个128位的hash值,并且转化为一个byte数组*/
byte[] bytes = Hashing.murmur3_128().
hashObject(element, Funnels.stringFunnel(Charset.forName("UTF-8"))).
asBytes();
long hash1 = Longs.fromBytes(bytes[7],bytes[6],bytes[5],bytes[4],bytes[3],bytes[2],bytes[1],bytes[0]);
long hash2 = Longs.fromBytes(bytes[15],bytes[14],bytes[13],bytes[12],bytes[11],bytes[10],bytes[9],bytes[8]);
/*用这两个hash值来模拟多个函数产生的值*/
long combinedHash = hash1;
for(int i=0;i<numHashFunctions;i++)
indices[i]=(combinedHash&Long.MAX_VALUE) % bitmapLength;
combinedHash = combinedHash + hash2;
System.out.print(element+"数组下标");
for(long index:indices)
System.out.print(index+",");
System.out.println(" ");
return indices;
/**
* 插入元素
*
* @param key 原始Redis键,会自动加上前缀
* @param element 元素值,字符串类型
* @param expireSec 过期时间(秒)
*/
public void insert(String key, String element, int expireSec)
if (key == null || element == null)
throw new RuntimeException("键值均不能为空");
String actualKey = RS_BF_NS.concat(key);
try (Jedis jedis = jedisPool.getResource())
try (Pipeline pipeline = jedis.pipelined())
for (long index : getBitIndices(element))
pipeline.setbit(actualKey, index, true);
pipeline.syncAndReturnAll();
catch (Exception ex)
ex.printStackTrace();
jedis.expire(actualKey, expireSec);
/**
* 检查元素在集合中是否(可能)存在
*
* @param key 原始Redis键,会自动加上前缀
* @param element 元素值,字符串类型
*/
public boolean mayExist(String key, String element)
if (key == null || element == null)
throw new RuntimeException("键值均不能为空");
String actualKey = RS_BF_NS.concat(key);
boolean result = false;
try (Jedis jedis = jedisPool.getResource())
try (Pipeline pipeline = jedis.pipelined())
for (long index : getBitIndices(element))
pipeline.getbit(actualKey, index);
result = !pipeline.syncAndReturnAll().contains(false);
catch (Exception ex)
ex.printStackTrace();
return result;
@Override
public String toString()
return "RedisBloomFilter" +
"numApproxElements=" + numApproxElements +
", fpp=" + fpp +
", numHashFunctions=" + numHashFunctions +
", bitmapLength=" + bitmapLength +
'';
测试类
import cn.enjoyedu.redis.redisbase.advtypes.RedisBloomFilter;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
public class TestRedisBloomFilter
private static final int DAY_SEC = 60 * 60 * 24;
@Autowired
private RedisBloomFilter redisBloomFilter;
@Test
public void testInsert() throws Exception
System.out.println(redisBloomFilter);
redisBloomFilter.insert("topic_read:8839540:20210810", "76930242", DAY_SEC);
redisBloomFilter.insert("topic_read:8839540:20210810", "76930243", DAY_SEC);
redisBloomFilter.insert("topic_read:8839540:20210810", "76930244", DAY_SEC);
redisBloomFilter.insert("topic_read:8839540:20210810", "76930245", DAY_SEC);
redisBloomFilter.insert("topic_read:8839540:20210810", "76930246", DAY_SEC);
@Test
public void testMayExist() throws Exception
System.out.println(redisBloomFilter.mayExist("topic_read:8839540:20210810", "76930242"));
System.out.println(redisBloomFilter.mayExist("topic_read:8839540:20210810", "76930244"));
System.out.println(redisBloomFilter.mayExist("topic_read:8839540:20210810", "76930246"));
System.out.println(redisBloomFilter.mayExist("topic_read:8839540:20210810", "86930250"));
测试结果:

二、HyperLogLog
HyperLogLog并不是一种数据结构,而是一种基数算法,通达HyperLogLog可以利用极小的内存空间完成独立总数的统计,数据集可以是IP、Email、ID等。
HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不精确,Redis 官方给出标准误差是 0.81%。
1、操作命令
HyperLogLog提供了3个命令:pfadd、pfcount、pfmerge
pfadd
pfadd 用于向 HyperLogLog 添加元素,如果添加成功返回 1:
pfadd key element [element …]
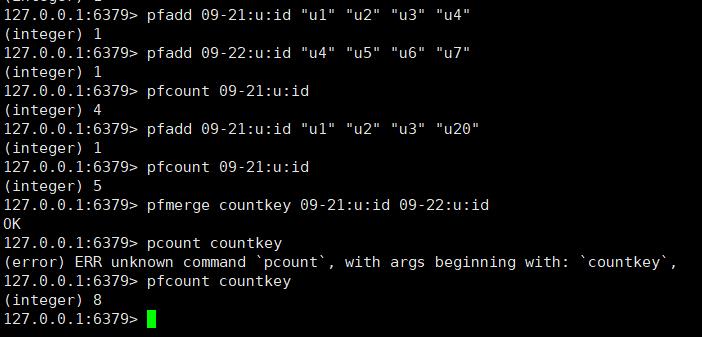
例如09-21的访问用户是u1、u2、u3、u4,09-22的访问用户是u4、u5、u6、u7

pfcount
pfcount 用于计算一个或多个 HyperLogLog 的独立总数
pfcount key [key ...]
例如09-21:u:id的独立总数为4,如果继续往里插入数据,比如插入 100 万条用户记录。内存增加非常少,但是 pfcount 的统计结果会出现误差


pfmerge
pfmerge 可以求出多个 HyperLogLog 的并集并赋值给 destkey
pfmerge destkey sourcekey [sourcekey ... ]
2、原理概述
HyperLogLog 基于概率论中伯努利试验并结合了极大似然估算方法,并做了分桶优化。
概率算法不直接存储数据集合本身,通过一定的概率统计方法预估值,这种方法可以大大节省内存,同时保证误差控制在一定范围内。
实例理解
统计网页每天的 UV 数据
1、转为比特串 :通过 hash 函数,将数据转为比特串,例如输入 5,便转为:101。
2、分桶: 分桶就是分多少轮。抽象到计算机存储中去,就是存储的是一个以单位是比特(bit),长度为 L 的大数组 S ,将 S 平均分为 m 组,注意这个 m 组,就是对应多少轮,然后每组所占有的比特个数是平均的,设为 P。容易得出下面的关系:
L = S.length
L = m * p
以 K 为单位,S 占用的内存 = L / 8 / 1024
3、对应:不同的用户 id 标识了一个用户,那么我们可以把用户的id 作为被 hash 的输入。即: hash(id) = 比特串,不同的用户 id,拥有不同的比特串。每一个比特串,也必然会至少出现一次1 的位置。我们类比每一个比特串为一次伯努利试验。
假设比特串的低两位用来计算桶下标志,总共有 4 个桶,此时有一个用户的 id 的比特串是:1001011000011。它的所在桶下标为:12^1 + 12^0 = 3,处于第 3 个桶,即第 3 轮中。计算出桶号后,剩下的比特是:10010110000,从低位到高 位看,第一次出现 1 的位置是 5 。也就是说,此时第 3 个桶中,k_max = 5。5对应的二进制是:101,将 101存入第 3 个桶。模仿上面的流程,多个不同的用户 id,就被分散到不同的桶中去了,且每个桶有其k_max。最终结合所有桶中的 k_max,代入估算公式,便能得出估算值。
Redis 中的 HyperLogLog 实现
Redis 的实现中,HyperLogLog 占据 12KB 的大小,共设有 16384 个桶,即:2^14 = 16384,每个桶有 6 位,每个桶可以表达的最大数字是:25+24+…+1 = 63 ,二进制为: 111 111 。
对于命令:pfadd key value
在存入时,value 会被 hash 成 64 位,即 64 bit 的比特字符串,前 14 位用来分桶,剩下 50 位用来记录第一个 1 出现的位置。
之所以选 14 位 来表达桶编号是因为,分了 16384 个桶,而 2^14 = 16384, 刚好最大的时候可以把桶利用完,不造成浪费。假设一个字符串的前 14 位是:00 0000 0000 0010 (从右往左看) ,其十进制值为 2。那么 value 对应转化后的值放到编号为 2 的桶。
index 的转化规则
因为完整的
value 比特字符串是 64 位形式,减去 14 后,剩下 50 位,
假设极端情况,出现 1 的位置,是在第 50 位,即位置是 50。此时 index = 50。此时先将 index转为 2 进制,它是:110010 。
因为 16384 个桶中,每个桶是 6 bit 组成的。于是 110010 就被设置到了第 2 号桶中去了。50 已经是最坏的情况,且它都被容纳进去了。那么其他的不用想也肯定能被容纳进去。
不同的 value,会被设置到不同桶中去,如果出现了在同一个桶的,即前 14 位值是一样的,但是后面出现 1 的位置不一样。那么比较原来的 index 是否比新 index 大。是,则替换。否,则不变。
最终,一个 key 所对应的 16384 个桶都设置了很多的 value 了,每个桶有一个 k_max。此时调用pfcount 时,按照调和平均数进行估算,同时加以偏 差修正,便可以计算出 key的设置了多少次 value,也就是统计值,具体的估算
公式如下

value 被转为 64 位的比特串,最终被按照上面的做法记录到每个桶中去。64 位转为十进制就是:2^64,HyperLogLog 仅用了:16384 * 6 /8 / 1024 =12K 存 储空间就能统计多达 2^64 个数。
三、GEO
Redis 3.2 版本提供了 GEO(地理信息定位)功能,支持存储地理位置信息用来 实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能。
地图元素的位置数据使用二维的经纬度表示,经度范围 (-180, 180],纬度范围(-90, 90],纬度正负以赤道为界,北正南负,经度正负以本初子午线 (英国格林尼治天文台) 为界,东正西负。
在 Redis 里面,经纬度使用 52 位的整数进行编码,放进了 zset 里面,zset 的value 是元素的 key,score 是 GeoHash 的 52 位整数值。
1、操作命令
增加地理位置信息
geoadd key longitude latitude member [longitude latitude member ...J
longitude、latitude、member 分别是该地理位置的经度、纬度、成员
例如:添加北京的地理位置:北京的经度是116.28,纬度是39.55
geoadd cities:locations 116.28 39.55 beijing

获取地理位置信息
geopos key member [member ...]
例如:获取天津的经纬度
geopos cities:locations tianjin

获取两个地理位置的距离
geodist key member1 member2 [unit]
unit 代表返回结果的单位,包含以下四种:
- m (meters)代表米。
- km (kilometers)代表公里。
- mi (miles)代表英里。
- ft(feet)代表尺。
例如:计算天津到北京的距离,并以公里为单位
geodist cities:locations tianjin beijing km

获取指定位置范围内的地理信息位置集合
georadius key longitude latitude radius m|km|ft|mi [withcoord][withdist] [withhash][COUNT count] [ascldesc] [store key] [storedist key]
georadiusbymember key member radius m|km|ft|mi [withcoord][withdist] [withhash] [COUNT count][ascldesc] [store key] [storedist key]
georadius 和 georadiusbymember 两个命令的作用是一样的,都是以一个地理位置为中心算出指定半径内的其他地理信息位置,不同的是 georadius 命令的中心位置给出了具体的经纬度,georadiusbymember 只需给出成员即可。其中radius m | km |ft |mi 是必需参数,指定了半径(带单位)。
withcoord:返回结果中包含经纬度。
withdist:返回结果中包含离中心节点位置的距离。
withhash:返回结果中包含 geohash,有关 geohash 后面介绍。
COUNT count:指定返回结果的数量。
asc l desc:返回结果按照离中心节点的距离做升序或者降序。
store key:将返回结果的地理位置信息保存到指定键。
storedist key:将返回结果离中心节点的距离保存到指定键。
例如:计算五座城市中,距离北京150公里以内的城市
georadiusbymember cities:locations beijing 150 km

获取 geohash
geohash key member [member ...]
Redis 使用 geohash 将二维经纬度转换为一维字符串,
例如:返回 beijing的 geohash 值。
geohash cities:locations beijing

删除地理位置信息
GEO 没有提供删除成员的命令,但是因为 GEO 的底层实现是 zset,所以可以借用 zrem 命令实现对地理位置信息的删除。
zrem key member

以上是关于4Redis高级数据结构(BitmapsHyperLogLogGEO)的主要内容,如果未能解决你的问题,请参考以下文章