强化学习理论入门(Trust Region Policy Optimization介绍)
Posted Jie Qiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习理论入门(Trust Region Policy Optimization介绍)相关的知识,希望对你有一定的参考价值。
介绍
本文主要介绍Trust Region Policy Optimization这篇文章,这篇文章主要回答了如下2个问题:
- 两个不同策略的value function,他们的差异是多少?
- 有什么办法可以保证,一个策略相比于另外一个策略一定能够提升呢?
针对这两个问题,我们先定义一些基本的概念,
基本定义
下图是一个较为一般的强化学习MDP框架下的概率图模型
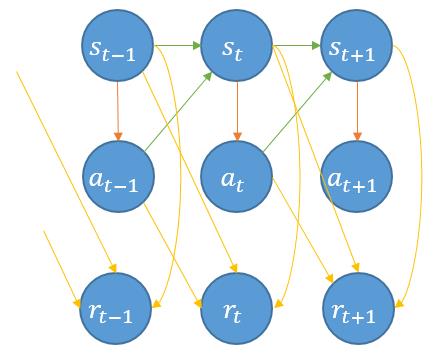
注意,这个图并不一定通用,特别是reward(比如 s t + 1 s_t+1 st+1可以不指向 r t + 1 r_t+1 rt+1),可能是需要考虑具体场景,但这是一个较为一般化结构。基于此,我们有:
马尔科夫性质
P ( S t + 1 = s ′ , R t + 1 = r ′ ∣ s t , a t , r t , … , r 1 , s 0 , a 0 ) = P ( S t + 1 = s ′ , R t + 1 = r ′ ∣ s t , a t ) P\\left( S_t+1 =s^\\prime ,R_t+1 =r^\\prime \\mid s_t ,a_t ,r_t ,\\dotsc ,r_1 ,s_0 ,a_0\\right) =P\\left( S_t+1 =s^\\prime ,R_t+1 =r^\\prime \\mid s_t ,a_t\\right) P(St+1=s′,Rt+1=r′∣st,at,rt,…,r1,s0,a0)=P(St+1=s′,Rt+1=r′∣st,at)
状态转移矩阵:
P s s ′ a = ∑ r ′ P ( S t + 1 = s ′ , R t + 1 = r ′ ∣ S t = s , A t = a ) \\mathcalP_ss'^a =\\sum _r' P\\left( S_t+1 =s^\\prime ,R_t+1 =r^\\prime \\mid S_t =s,A_t =a\\right) Pss′a=r′∑P(St+1=s′,Rt+1=r′∣St=s,At=a)
下一时刻的reward:
R s s ′ a = E [ R t + 1 ∣ S t = s , A t = a , S t + 1 = s ′ ] = 1 P s s ′ a ∑ r ′ r ′ P ( S t + 1 = s ′ , R t + 1 = r ′ ∣ S t = s , A t = a ) \\mathcalR_ss'^a =E[ R_t+1 \\mid S_t =s,A_t =a,S_t+1 =s'] =\\frac1\\mathcalP_ss'^a\\sum _r' r'P\\left( S_t+1 =s^\\prime ,R_t+1 =r^\\prime \\mid S_t =s,A_t =a\\right) Rss′a=E[Rt+1∣St=s,At=a,St+1=s′]=Pss′a1r′∑r′P(St+1=s′,Rt+1=r′∣St=s,At=a)
轨迹序列联合概率:
p ( τ ∣ π ) = p ( s 0 ) ∏ t = 0 T − 1 p ( s t + 1 , r t + 1 ∣ s t , a t ) π ( a t ∣ s t ) p(\\tau \\mid \\pi )=p( s_0)\\prod _t=0^T-1 p( s_t+1 ,r_t+1 \\mid s_t ,a_t) \\ \\pi ( a_t \\mid s_t) p(τ∣π)=p(s0)t=0∏T−1p(st+1,rt+1∣st,at) π(at∣st)
State Value Function:
V
π
(
s
)
=
E
τ
∼
π
[
∑
l
=
0
∞
γ
l
r
t
+
l
+
1
∣
S
t
=
s
]
=
∑
a
t
,
r
t
+
1
,
s
t
+
1
.
.
.
.
p
(
s
t
)
∏
t
∞
p
(
s
t
+
1
∣
s
t
,
a
t
)
p
(
r
t
+
1
∣
s
t
,
a
t
,
s
t
+
1
)
π
(
a
t
∣
s
t
)
∑
l
=
0
∞
γ
l
r
t
+
l
+
1
=
∑
a
t
,
r
t
+
1
,
s
t
+
1
以上是关于强化学习理论入门(Trust Region Policy Optimization介绍)的主要内容,如果未能解决你的问题,请参考以下文章