Kafka生产者是如何发送消息的?
Posted Java鱼仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka生产者是如何发送消息的?相关的知识,希望对你有一定的参考价值。
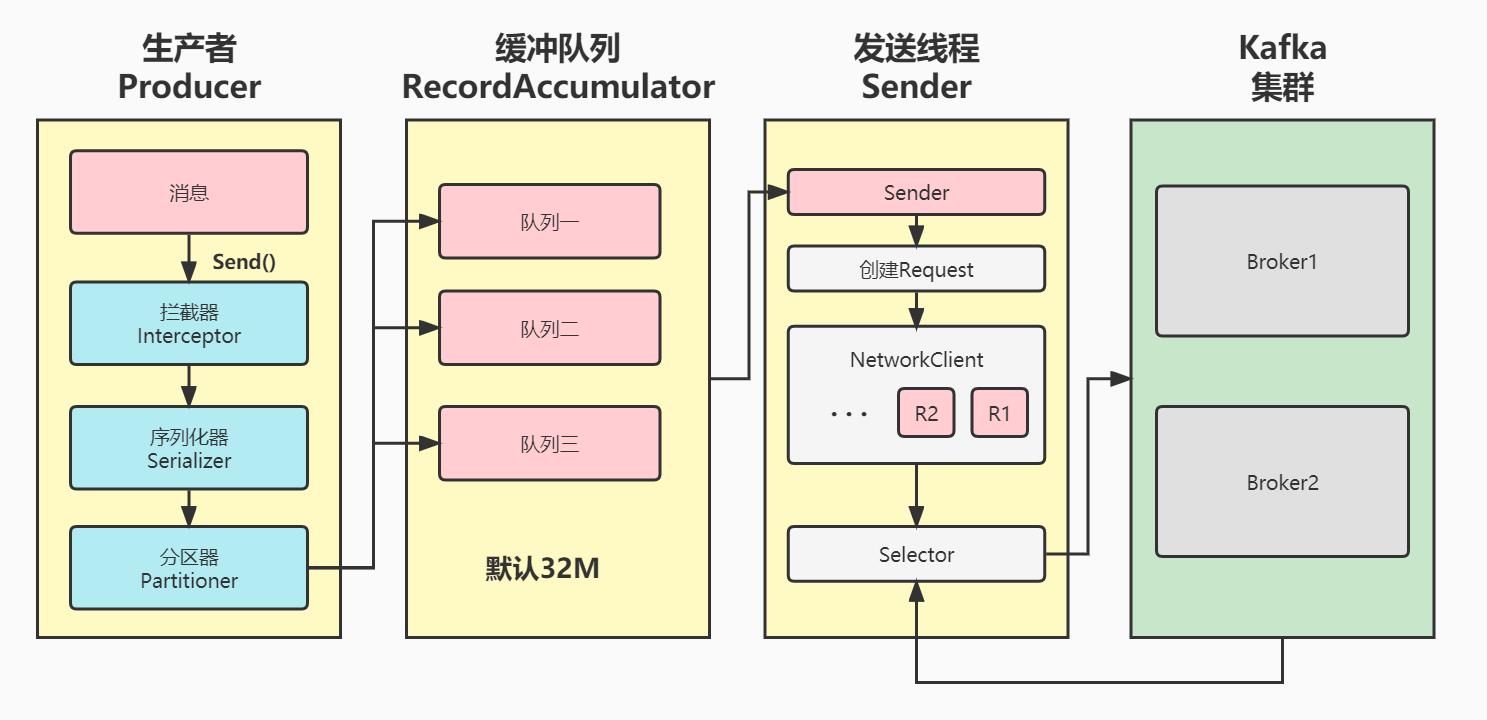
(一)生产者的原理
当有数据要从生产者发往消费者的时候,在kafka底层有这样一套流程。首先生产者调用send方法发送消息后,会先经过一层拦截器,接着进入序列化器。序列化器主要用于对消息的Key和Value进行序列化。接着进入分区器选择消息的分区。
上面这几步完成之后,消息会进入到一个名为RecordAccumulator的缓冲队列,这个队列默认32M。当满足以下两个条件的任意一个之后,消息由sender线程发送。
条件一:消息累计达到batch.size,默认是16kb。
条件二:等待时间达到linger.ms,默认是0毫秒。
所以在默认情况下,由于等待时间是0毫秒,所以只要消息来一条就会发送一条。
Sender线程首先会通过sender读取数据,并创建发送的请求,针对Kafka集群里的每一个Broker,都会有一个InFlightRequests请求队列存放在NetWorkClient中,默认每个InFlightRequests请求队列中缓存5个请求。接着这些请求就会通过Selector发送到Kafka集群中。
当请求发送到发送到Kafka集群后,Kafka集群会返回对应的acks信息。生产者可以根据具体的情况选择处理acks信息。比如是否需要等有回应之后再继续发送消息,还是不管发送成功失败都继续发送消息。
(二)消息发送实例
在使用kafka发送消息前首先需要引入相关依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.0</version>
</dependency>
2.1 简单异步发送
首先是最简单的发送方式,通过Properties配置kafka的连接方式以及Key和Value的序列化方式,接着调用send方法将消息发送到指定的topic中。
public class Producer
public static void main(String[] args)
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.78.128:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
kafkaProducer.send(new ProducerRecord<>("testTopic","hello"));
kafkaProducer.close();
2.2 带回调的异步发送
上面的这种方式是无法获取消息的发送情况的,因此可以使用带有回调函数的send方法:
public class ProducerCallback
public static void main(String[] args)
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.78.128:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
kafkaProducer.send(new ProducerRecord<>("testTopic", "hello"), new Callback()
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e)
System.out.println(recordMetadata.topic()+" "+recordMetadata.partition());
);
kafkaProducer.close();
通过回调函数可以拿到一系列发送后的数据信息,比如topic和分区等。
2.3 同步发送
一般来说消息队列会采用异步的方式,但是如果项目中有同步发送的需求,kafka也可以使用。实现方式比较简单,只需要在send方法后加上get方法即可:
public static void main(String[] args) throws ExecutionException, InterruptedException
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.78.128:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
kafkaProducer.send(new ProducerRecord<>("testTopic","hello")).get();
kafkaProducer.close();
(三)消息发送时的分区策略
3.1 kafka的分区策略
kafka通过分区实现了大数据量下的消息队列,当kafka集群中有多个分区时,发送消息可以指定将一条消息发送到某个分区上。
观察ProducerRecord方法的几个入参:
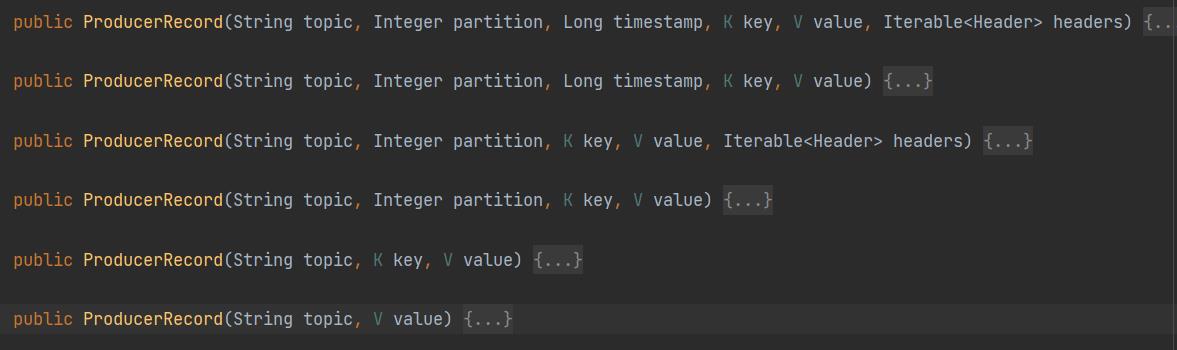
当指定了分区partition时,消息会发送到指定的分区上;
当没有指定partition但是存在Key时,会采用将Key的hash值与分区数取余的方式得到指定分区;
当只存在Value的情况下,Kafka内部会采用Sticky partition,随机选择一个分区使用,等该分区的batch满了或者linger.ms时间到之后,再随机选择一个分区使用。
3.2 自定义分区
有时候我们可能想实现一些自定义的分区规则,比如当key为某个值的时候发送到指定分区,这种情况下就可以使用自定义分区。
新建一个类实现Partitioner接口,在partition方法中定义自己的逻辑,这里是当key等于aaa时,发送到分区0,否则发送到分区1。
public class MyPartition implements Partitioner
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster)
if (key.toString().equals("aaa"))
return 0;
else
return 1;
@Override
public void close()
@Override
public void configure(Map<String, ?> map)
接着配置分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.javayz.kafka.producer.MyPartition");
(四)生产者的优化方案
4.1 提高发送吞吐量
前面讲到,从RecordAccumulator发送数据到kafka集群要满足两个条件,batch.size达到某个数量级或者linger.ms达到等待的时间。
由于默认的batch.size=16k,linger.ms=0ms,意味着每次有消息过来的时候,直接就发往了kafka集群中,这样的吞吐量是不高的。因此可以略微提高linger.ms等待时间,等一些消息进来之后再一起发送到kafka集群中,吞吐量就提高了。
除此之外,还可以设置消息的压缩方式,或者调整RecordAccumulator的大小等方式实现吞吐量的提升。
//设置批次大小
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
//设置linger.ms
properties.put(ProducerConfig.LINGER_MS_CONFIG,10);
//设置压缩方式,可选gzip,snappy,lz4,zstd
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");
//设置缓冲区大小
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
4.2 提高数据可靠性
数据发送到kafka集群后,kafka集群有三种应答方式:
acks=0,生产者发送过来的数据不管是否成功都不管。
acks=1,只有当kafka的分区Leader节点应答后才会继续发送数据。
acks=-1,只有当Leader和ISR队列里所有节点都应答后才继续发消息。
ISR队列是和Leader节点保持同步的Follower和Leader节点的集合队列,比如Leader节点是0,另外两个Follower节点是1和2,则ISR队列就是0,1,2。如果某个Follow节点在指定时间内没有应答Leader,则将这个节点从ISR队列中踢出。
一般来讲会根据应用场景选择三种应答方式,如果是数据需要强可靠性的情况,就会使用acks=-1的情况,如果对数据的可靠性没有要求,则可以选择0和1。
//设置应答ack,0、1、-1
properties.put(ProducerConfig.ACKS_CONFIG,"0");
4.3 消息的事务管理
在mysql中,有的时候会通过事务保证数据的插入同时成功或者全部失败。
在Kafka中消息的发送同样支持事务。在kafka中开启事务需要首先指定事务的ID。
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"transaction_01");
再通过几个事务API发送事务消息
kafkaProducer.initTransactions();
kafkaProducer.beginTransaction();
try
kafkaProducer.send(new ProducerRecord<>("testTopic", "aaab","hello"), new Callback()
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e)
System.out.println(recordMetadata.topic()+" "+recordMetadata.partition());
);
kafkaProducer.commitTransaction();
catch (Exception e)
kafkaProducer.abortTransaction();
以上是关于Kafka生产者是如何发送消息的?的主要内容,如果未能解决你的问题,请参考以下文章