关于Unity C# 的Value Type (值类型) vs. Reference Type (引用类型),优缺点?GC ? ECS?
Posted u010019717
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于Unity C# 的Value Type (值类型) vs. Reference Type (引用类型),优缺点?GC ? ECS?相关的知识,希望对你有一定的参考价值。
声明: 前面都是语言很基础的废话, 可直接跳到后面查看内容
官方文档的总结:Value Types and Reference Types
.Net下数据类型分为三大类︰
- Value Type (值类型) ︰常见的型别是struct、int、char、double等,基类System.ValueType,这些类型的大小是固定的。例如,声明一个int变量会使编译器分配4个字节的内存(32位)来保存整数值。
- Reference Type (参引用类型) ︰典型的例子就是使用class关键字定义的类型,基类Object类
- Pointer Type (指针类型):不安全代码,较少使用
C# (或说大部份的高级语言) 会将内存分为两大用途︰Stack 与Heap。
整理一下重点如下︰
- 在C# 中,内存用途分为Stack 与Heap 两种,所有的区域变数(不管是Value Type 或是Reference Type) 都储存于Stack 下,使用new 关键字实体化的类型实例,则储存于Heap 中
- Value Type 储存的是实际值,Reference 储存的是地址/引用
- 由于Value Type 与Reference Type 在内存储存值上的差异,在使用上若不理解,有时会造成意料外的问题
注意不准确的描述:值类型存储在栈上,引用类型存储在托管堆上。 准确的描述: 引用类型一定存储在托管堆上(目前为止是这样,后面内容会提到另外一种可能), 值类型可能存储在栈上,也可能存储在堆上,因为值类型作为引用类型的字段,肯定就存储在堆上了。
首先看下面书的中的总结
Microsoft Visual C# Step by Step (8th Edition)
int i = 42; // 声明并初始化i
int copyi = i; /* copyi包含i中数据的副本:
i和copyi都是值42 */
i++; /* 增加i对copyi没有影响;
我现在包含43,但copyi仍然包含42 */
Circle c = new Circle(42);
Circle refc = c;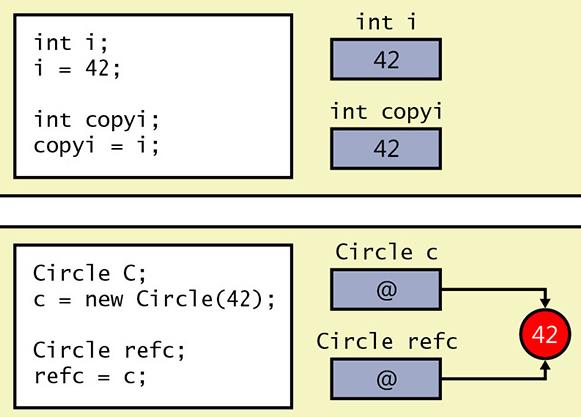
WrappedInt wi = new WrappedInt();
Console.WriteLine(wi.Number);
Pass.Reference(wi);
Console.WriteLine(wi.Number);
public static void Reference(WrappedInt param)
param.Number = 42;

变量被作为参数向Pass.Reference方法。因为WrappedInt是一个类(引用类型),所以wi和param都引用同一个WrappedInt实例对象。通过Pass.Reference中的param变量对对象的内容所做的任何更改方法完成后,直接影响到wi变量。上图说明了将WrappedInt对象作为参数传递给Pass.Reference方法时发生的情况:
计算机内存的组织方式
计算机使用内存来保存正在执行的程序以及这些程序使用的数据。要了解值和引用类型之间的差异,了解内存中数据的组织方式将很有帮助。
诸如C#使用的操作系统和语言运行时经常将用于保存数据的内存划分为两个单独的区域,每个区域以不同的方式进行管理。传统上,这两个内存区域称为栈stack 和堆heap。栈和堆有不同的用途,在此进行描述:
-
调用方法时,总是从栈中获取其参数及其局部变量所需的内存。当方法完成时(因为它返回或引发异常),为参数和局部变量获取的内存将自动释放回栈,并在调用另一个方法时再次可用。方法参数和堆栈上的局部变量具有明确定义的生命周期:它们在方法开始时就存在,而在方法完成时就消失。
注意
实际上,相同的生命周期适用于在用花括号括起来的任何代码块中定义的变量。在以下代码示例中,变量i在while循环的主体开始时创建,但是在while循环结束时消失,并且在右括号之后继续执行:
while (...) int i = ...; // i 在这里的栈上创建 ... // i 从这里的栈中消失了 - 使用new关键字创建对象(类的实例)时,始终从堆中获取构建对象所需的内存。您已经看到可以使用引用变量从多个地方引用同一对象。当对对象的最后一个引用消失时,该对象使用的内存将成为垃圾(尽管可能不会立即对其进行回收)。因此,在堆上创建的对象的生存期更加不确定。使用new关键字创建一个对象,但是该对象仅在删除对该对象的最后一个引用之后的某个时间才会消失。
注意
所有值类型都在栈上创建。所有引用类型(对象)都在堆上创建(尽管引用本身在堆栈上(说的是变量))。可空类型实际上是引用类型,它们是在堆上创建的。
栈和堆来自运行时管理内存的方式:
- 栈存储器的组织方式就像一堆箱子堆叠在一起。调用方法时,每个参数都放在栈顶部的框中。同样为每个局部变量分配了一个框,并将它们放置在堆栈中已经存在的框的顶部。方法完成后,您可以考虑将盒子从栈中删除。
- 堆内存就像是一大堆箱子散布在房间周围,而不是整齐地堆叠在一起。每个盒子上都有一个标签,指示是否正在使用它。创建新对象时,运行时将搜索一个空框并将其分配给该对象。对对象的引用存储在堆栈上的局部变量中。运行时跟踪每个框的引用数。(请记住,两个变量可以引用同一对象。)当最后一个引用消失时,运行时会将框标记为未使用,并且在将来的某个时候,它将清空该框并使之可用。
使用堆栈和堆
现在让我们检查一下调用Method的方法时会发生什么:
void Method(int param)
Circle c;
c = new Circle(param);
...
假设传递给param的参数是值42。调用该方法时,会从堆栈中分配一个内存块(足够用于int)并用值42初始化。当执行在方法内部移动时,另一个块还从堆栈中分配了足以容纳引用的内存(一个内存地址),但未初始化。这是针对Circle变量c的。接下来,从堆中分配另一块足够用于Circle对象的内存。这就是new关键字的作用。该Circle 的构造函数运行到这个原始堆内存转换为Circle 对象。对这个Circle 的引用对象存储在变量c中。下图显示了这种情况:

此时,您应该注意两点:
- 尽管对象存储在堆中,但对对象的引用(变量c)存储在堆栈中。
- 堆内存不是无限的。如果堆内存已用完,则new操作符将抛出OutOfMemoryException异常,并且不会创建该对象。
注意该Circle 的构造也可以抛出异常。如果是这样,将回收分配给Circle对象的内存,并且构造函数返回的值将为null。
方法结束后,参数和局部变量将超出范围。为c和param获取的内存将自动释放回堆栈。运行时指出,不再引用Circle对象,将来某个时候它将安排其内存被堆回收。
下面变量c和o都引用同一个Circle对象。实际上,c的类型为Circle且o的类型为object(System.Object的别名)这一事实实际上在内存中是一个数据。
Circle c;
c = new Circle(42);
object o;
o = c;下图说明了变量c和o如何引用堆上的同一项目。

Boxing装箱
如您所见,object类型的变量可以引用任何引用类型的任何item。但是,对象类型的变量也可以引用值类型。例如,以下两个语句将变量i(类型为int,值类型)初始化为42,然后将变量o(类型为object,引用类型)初始化为i:
int i = 42;
object o = i;第二个语句需要一些解释,以了解实际发生的情况。请记住,i是一个值类型,它存在于栈中。如果o内部的引用直接引用i,则引用将引用栈。但是,所有引用都必须引用堆上的对象。在栈上创建对items 的引用可能会严重损害运行时的健壮性并创建潜在的安全漏洞,因此不允许这样做。因此,运行时从堆中分配一块内存,将整数i的值复制到该内存中,然后将对象o引用到此副本。将items 从栈自动复制到堆的过程称为boxing。下图显示了结果:

分析IL代码时很明显:

注意:您可以使用ReSharper的堆分配查看器插件来检测代码中的装箱。
重要
如果修改变量i的原始值,则通过o引用的堆上的值将不会更改。同样,如果您修改堆上的值,则变量的原始值不会更改。
Unboxing拆箱
由于类型为object的变量可以引用值的装箱副本,因此仅允许您通过变量获取该装箱值是合理的。您可能希望能够通过使用如下简单的赋值语句来访问变量o所引用的装箱的int值:
int i = o;但是,如果尝试使用此语法,则会出现编译时错误。如果您考虑一下,就不能使用int = i是很明智的。毕竟,o可能会引用任何东西,而不仅仅是int。考虑如果允许该语句,以下代码将发生什么:
Circle c = new Circle();
int i = 42;
object o;
o = c; // o表示一个circle
i = o; // i中存储了什么?
要获取装箱副本的值,必须使用称为cast的内容。此操作在实际制作副本之前检查将一种类型的item转换为另一种item是否安全。您可以在对象变量的前面加上括号的类型名称,如以下示例所示:
int i = 42;
object o = i; // 装箱
i = (int)o; // 正常编译编译器注意到您已经在类型转换中指定了int类型。接下来,编译器生成代码以检查o在运行时实际指的是什么。(在此示例中,装箱的值然后存储在i中。)这称为unboxing拆箱。。下图显示了正在发生的情况:

另一方面,如果o没有引用boxed int,则类型不匹配,从而导致强制转换失败。编译器生成的代码在运行时引发InvalidCastException异常。这是拆箱失败的示例:
Circle c = new Circle(42);
object o = c; // //因为Box是一个引用变量而没有装箱
int i = (int)o; // 编译正常,但在运行时引发异常下图说明了这种情况:
 请记住,装箱和拆箱是昂贵的操作,因为需要进行大量检查,并且需要分配额外的堆内存。装箱有其用途,但使用不当会严重损害程序的性能。
请记住,装箱和拆箱是昂贵的操作,因为需要进行大量检查,并且需要分配额外的堆内存。装箱有其用途,但使用不当会严重损害程序的性能。
=========================================================== 上面说的都是语言基础相关的废话
C# 值类型与引用类型 的底层逻辑
structs具有更好的数据局部性。与引用类型相比,值类型给GC施加的压力要小得多。但是大型值类型的复制成本很高,而且您可能会意外装箱,这是不好的。
值类型和引用类型在性能特征方面有很大不同。可以查看文章: ref returns and locals,ValueTask<T>和Span<T> https://adamsitnik.com/ref-returns-and-ref-locals/。
内存布局
引用类型的每个实例都有两个额外的字段,供CLR在内部使用。
ObjectHeader是一个位掩码,CLR使用它来存储一些其他信息。例如:如果您锁定给定的对象实例,则此信息存储在中ObjectHeader。MethodTable是指向“方法表”的指针,该表是有关给定类型的一组元数据。如果您调用虚拟方法,则CLR会跳转到“方法表”并获取实际实现的地址并执行实际调用。
两个隐藏字段的大小都等于指针的大小。因此,对于32 bit体系结构,我们有8个字节(因为一个字段是四个字节)的开销和64 bit16个字节。

值类型没有任何其他开销成员。你所看到的就是你得到的。这就是为什么它们在功能方面受到更多限制的原因。您不能从中导出它struct,也不能lock为其编写终结器。

CPU缓存
CPU实现了许多性能优化。其中之一是缓存,它只是具有最近使用的数据的内存。

注意:多线程会影响CPU缓存性能。为了更易于理解,以下描述假定采用单核。
每当您尝试读取值时,CPU都会检查高速缓存的第一级(L1)。如果命中hit,则返回值。否则,它将检查第二级缓存(L2)。如果存在该值,则将其复制到L1并返回。否则,它将检查L3(如果存在)。
如果数据不在高速缓存中,则CPU转到主内存并将其复制到高速缓存中。这称为缓存未命中cache miss。
每个程序员都应该知道的延迟数
根据延迟数,每个程序员都应该知道,与引用缓存相比,进入主存储器确实非常昂贵。

| 运作方式 | 时间 |
| L1缓存参考 | 1ns |
| L2缓存参考 | 4ns |
| 主内存参考 | 100毫微秒 |
那么如何降低缓存未命中率呢?
数据局部性
CPU很聪明,它了解以下数据局部性原则:
- 空间空间
如果在特定时间引用了特定的存储位置,则很可能在不久的将来引用附近的存储位置。
- Temporal
如果在某一时刻引用了特定的存储位置,则很可能在不久的将来再次引用同一位置。
CPU正在利用这一知识。每当CPU将值从主内存复制到缓存时,它就复制整个缓存行,而不仅仅是复制该值。高速缓存行通常为64个字节。因此,如果您要求附近的存储位置,它已经做好了充分的准备。
.NET故事
每个引用类型实例的两个额外字段如何影响数据局部性?让我们看一下下图,该图显示了架构的单个缓存行中有多少个实例,ValueTuple<int, int>并且Tuple<int, int>可以容纳多少个实例64bit。
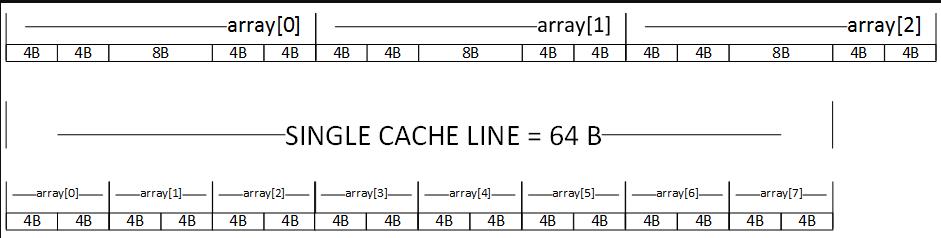
对于这个简单的示例,差异确实很大。在我们的例子中,我们可以容纳8个值类型和2.66引用类型的实例。
GC影响
引用类型始终分配在托管堆上(将来可能会更改, 将来可能分配在栈上)。堆由垃圾收集器(GC)管理。堆内存的分配很快。问题在于,重新分配是通过不确定的GC执行的。GC实施自己的启发式方法,使其可以决定何时执行清除。清理本身需要一些时间。这意味着您无法预测何时进行清理,这会增加额外的开销。
值类型可以在栈和堆上分配。栈不受GC管理。每当您声明局部值类型变量时,它都会在堆栈中分配。这种重新分配非常快。总体而言,我们对GC的压力较小!压力不等于零,因为无论如何,GC遍历stacks,因此stacks越深,可能进行的工作越多。
但是,还可以在托管堆上分配值类型。如果分配字节数组,则该数组将分配到托管堆上。此内容对GC透明。它们不是引用类型实例,因此GC不会以任何方式跟踪它们。但是,当较小的值类型数组提升为旧版GC时,内容将由GC复制。
注意:如果值类型包含引用类型,则GC将发出写屏障,以对引用字段进行写访问。因此,对于包含引用的值类型,No GC并非100%正确。
调用具有值类型的接口方法
前面的例子很明显。但是,当我们尝试将结构传递给接受接口实例的方法时,会发生什么?让我们来看看。
[MemoryDiagnoser]
[RyuJitX64Job, LegacyJitX86Job]
public class ValueTypeInvokingInterfaceMethod
interface IInterface
void DoNothing();
class ReferenceTypeImplementingInterface : IInterface
public void DoNothing()
struct ValueTypeImplementingInterface : IInterface
public void DoNothing()
private ReferenceTypeImplementingInterface reference = new ReferenceTypeImplementingInterface();
private ValueTypeImplementingInterface value = new ValueTypeImplementingInterface();
[Benchmark(Baseline = true)]
public void ValueType() => AcceptingInterface(value);
[Benchmark]
public void ReferenceType() => AcceptingInterface(reference);
void AcceptingInterface(IInterface instance) => instance.DoNothing();
会发生装箱!
如何避免使用实现接口的值类型装箱?
我们需要使用通用约束。该方法不应接受,IInterface但应T实现IInterface。
void Trick<T>(T instance)
where T : IInterface
instance.Method();
通过应用这个简单的技巧,我们不仅能够避免装箱,而且还能胜过引用类型接口方法的调用!由于JIT进行了优化,因此有可能。我将其称为方法虚拟化,因为我对此没有更好的名字。它是如何工作的?让我们考虑以下示例:
注意:不需要额外的struct约束来避免装箱。
public void Method<T>(T instance)
where T : IDisposable
instance.Dispose();
当T约束为时where T : INameOfTheInterface,C#编译器会发出IL称为constrained(Docs)的附加指令。
.method public hidebysig
instance void Method<([mscorlib]System.IDisposable) T> (
!!T 'instance'
) cil managed
.maxstack 8
IL_0000: ldarga.s 'instance'
IL_0002: constrained. !!T
IL_0008: callvirt instance void [mscorlib]System.IDisposable::Dispose()
IL_000d: ret
// end of method C::Method
如果该方法不是通用方法,则没有约束,并且实例可以是任何值:值或引用类型。如果是值类型,则JIT执行装箱。当该方法是通用方法时,JIT将为每种值类型编译该方法的单独版本。这可以防止拳击!它是如何工作的?
JIT处理值类型的方式与引用类型不同。对于所有引用类型而言,传递给方法或从方法返回的操作都是相同的。我们始终会处理所有引用类型具有相同大小的指针。因此,JIT将编译后的通用代码用于引用类型,因为它可以以相同的方式处理它们。想象一个由objects或组成的数组strings。从JIT的角度来看,它只是一个指针数组。因此,数组的索引器实现对于所有引用类型都是相同的。
值类型不同。它们每个可以具有不同的大小。例如,将带有两个整数字段的传递integer和定制传递struct给方法具有不同的本机实现。在一种情况下,我们将单个int推入堆栈,在另一种情况下,我们可能需要将两个字段移至寄存器,然后将它们推入堆栈。因此,每种值类型都不同。
这就是JIT为通用值类型参数分别编译通用方法/类型的原因。
Method<object>(); // JIT compiled code is common for all reference types Method<string>(); // JIT compiled code is common for all reference types Method<int>(); // dedicated version for int Method<long>(); // dedicated version for long Method<DateTime>(); // dedicated version for DateTime
这可能会导致通用代码膨胀。但是很棒的是,在这个时候,JIT可以为每种类型编译定制的代码。并且由于类型是已知的,因此可以将虚拟调用替换为直接调用。正如Victor Baybekov在评论中提到的那样,它甚至可以删除呼叫的不必要的null检查。它是值类型,因此不能为null。内联也是可能的。对于经常执行的小型方法(例如.Equals()在自定义词典实现中),可以大大提高性能。
注意:如果您想玩生成的IL代码,可以使用很棒的SharpLab。
复制中
默认情况下,在C#中,值类型按值传递给方法。这意味着,每次我们将Value Type实例传递给方法时,都会复制该实例。或当我们从方法返回它时。值类型越大,复制它的成本就越高。对于小值类型,JIT编译器可能会优化复制(内联方法,使用寄存器进行复制等)。
传递和返回引用类型与大小无关。仅传递指针的副本。而且指针总是可以放入CPU寄存器中。```
我们如何避免复制大的值类型?我们应该通过引用将其退回! 我将把它留在这里, 值类型越大,复制越昂贵。
摘要
- 引用类型的每个实例都有两个CLR在内部使用的额外字段。
- 值类型没有隐藏的开销,因此它们具有更好的数据局部性。
- 引用类型由GC管理。它跟踪引用,提供快速分配和昂贵的,不确定的释放。
- 值类型不受GC管理。值类型=无GC。而且没有GC比任何GC都要好!
- 每当需要引用时,都将装箱值类型。装箱昂贵,给GC增加了额外的压力。如果可以的话,应该避免装箱。
- 通过使用通用约束,我们可以避免装箱,甚至可以取消对值类型的接口方法调用的虚拟化!
- 值类型通过值传递给方法并从方法返回。因此,默认情况下,它们始终被复制。
资料
- Pro .NET Performance book by Sasha Goldshtein, Dima Zurbalev, Ido Flatow
- How does Object.GetType() really work? blog post by Konrad Kokosa
- Safe Systems Programming in C# and .NET video by Joe Duffy
- Memory Systems article by University Of Mary Washington
- Latency Numbers Every Programmer Should Know article by Berkeley University
- Types of locality definition by Wikipedia
- Understanding How General Exploration Works in Intel® VTune™ Amplifier XE by Jackson Marusarz (Intel)
- A new stackalloc operator for reference types with CoreCLR and Roslyn blog post by Alexandre Mutel
- Boxing and Unboxing article by MSDN
- Heap Allocations Viewer plugin blog post by Matt Ellis (JetBrains)
- SharpLab.io
- OpCodes.Constrained Field article by MSDN
- .NET Generics and Code Bloat article by MSDN
- What happens with a generic constraint that removes this requirement? Stack Overflow answer by Eric Lippert
- https://www.microsoftpressstore.com/articles/article.aspx?p=2454676&seqNum=10
- https://docs.microsoft.com/en-us/dotnet/visual-basic/programming-guide/language-features/data-types/value-types-and-reference-types
以上是关于关于Unity C# 的Value Type (值类型) vs. Reference Type (引用类型),优缺点?GC ? ECS?的主要内容,如果未能解决你的问题,请参考以下文章