Java实现一个简单的GitHub仓库信息爬取
Posted adventure.Li
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java实现一个简单的GitHub仓库信息爬取相关的知识,希望对你有一定的参考价值。
一、基本背景
邻近期末,各科开始布置实践作业。云计算实践作业需要采用Spark,Flink实现,其中需要用到爬虫进行数据的的爬取,来保证数据的来源和有效且“大量”。
二、技术选型
由于丰富的库和更贴切人的语言的特性,python在数据爬取方面应该具有top1的地位,并且GitHub里面也大量的可复用代码,因此大家也会首选python。而实际上爬虫的实现,任何高级语言都可以去实现的。作为Java出身,此次来采用Java进行简单的实现。
要素分析
对于数据获取方式:
- 网页分析,通过jsoup等框架进行对html文件的解析,并采用浏览器调试去分析所需数据
- 直接API调用,其实对于一些网站是对外提供API接口的。例如GitHub,api.github.com。而其返回结果则是JSON类型,这样为爬取数据提供了极大便利。
注:数据的获取方式则是通信方式的体现,应用软件的一般呈现交互接口为web,api,shell等,甚至基于socket的数据报。不过一般来说从应用层爬数据,因为对于爬虫来说一般是去处理客户直观可见而细微海量积累的数据。
对于通信框架方式:
无论通过什么数据获取,都需要通过网络框架去调用相应的API。该API或者说URL也一般为基于HTTP的。而Java的网络框架有很多,此处我推荐一个比较好用的封装框架: hutool工具,它的网络框架(基于HttpURLConnection 实现),之所以选择它并不是因为它性能,而是它的 简易性,更方便上手,另外它封装的JSON库也是十分方便。
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.1.4</version>
</dependency>
对于数据解析方式:
- 网页的dom,jsoup框架
- JSON串,hutool工具(推荐)/fastjson
对于数据存储方式:
- 文件保存,csv
- 关系数据库存重要数据,mysql
其他考虑
- 通信,考虑请求超时,安全认证(+token,例如github会限流,放反爬),考虑返回错误结果处理
- 爬虫的效率性,可控性。对爬虫的执行设计开关,定时开启\\执行\\结束,设计多线程来异步存储以及并行爬取(一致性问题),提升爬取效率
- 设计shell,webcontroller对进度展示和对其管理
- 批量插入问题,避免重复查询,加大数据库开销
三、核心代码
package com.nju.crawler;
import cn.hutool.http.HttpUtil;
import cn.hutool.json.JSONArray;
import cn.hutool.json.JSONNull;
import cn.hutool.json.JSONObject;
import org.junit.jupiter.api.Test;
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.OutputStreamWriter;
import java.util.ArrayList;
import java.util.Iterator;
/**
* @authorliyunfei
* @date2022/11/11
**/
public class CrawlGithubTests
private static final String USER_INFO_URL = "https://api.github.com/users?repos%3E0&since=";// index
private static final String REPO_INFO_URL = "https://api.github.com/users/username/repos";
private static final String LIMIT_TOKEN = "token your_token";
private static final String SAVE_PATH_PREFIX = "";
@Test
public void test()
//String userName = "hello";
//System.out.println( REPO_INFO_URL.replace("username",userName));
@Test
public void testCrawlRepo()
crawl(0);
void crawl(int index)
//int index = 0;//init index
// 网络IO处理
String json = HttpUtil.createGet(USER_INFO_URL+index)
.header("Authorization",LIMIT_TOKEN)
.execute().body();
/**
限流--
解决思路:如何伪造IP,跳板》》》 虚拟机去》》》?
采用token(换用-.-token 采用同一台机器不同的token去抓?)
"message":"API rate limit exceeded for 157.0.72.74. (But here's the good news: Authenticated requests get a higher rate limit. Check out the documentation for more details.)",
"documentation_url":"https://docs.github.com/rest/overview/resources-in-the-rest-api#rate-limiting"
*/
JSONArray jsonArray = new JSONArray(json);
Iterator iterator = jsonArray.iterator();
// 注意位置,处理的粒度
ArrayList<ArrayList<String>> arrayList = new ArrayList<>();
while (iterator.hasNext())
JSONObject userInfoResp = new JSONObject(iterator.next());
String userName = userInfoResp.getStr("login");
System.out.println("crawl>>>>>>>>>>>>>>>>>>"+userName+":repo>>>>>>>>>>>>>>>>>>>");
System.out.println(userName);
// 对仓库进行处理分析
json = HttpUtil.createGet( REPO_INFO_URL.replace("username",userName))
.header("Authorization",LIMIT_TOKEN)
.execute().body();
JSONArray jsonArray1 = new JSONArray(json);
Iterator iterator1 = jsonArray1.iterator();
System.out.println(userName+" repos size :"+jsonArray1.size());
while (iterator1.hasNext())
JSONObject jsonObject = new JSONObject(iterator1.next());
System.out.println(jsonObject);
ArrayList<String> row = new ArrayList<>();
for(Object o:jsonObject.values())
// 处理文件类型---
if(o instanceof Boolean)
row.add((Boolean) o ?"true":"false");
continue;
else if(o instanceof Integer)
row.add(((Integer)o)+"");
continue;
else if(o instanceof JSONObject || o instanceof JSONArray)
continue;
else if(o instanceof JSONNull)
row.add("");
continue;
row.add((String) o);
arrayList.add(row);
if(!iterator.hasNext())
// 为空了 需要发起新的请求
int firstIndex = index;
index = userInfoResp.getInt("id");
try
Thread.sleep(1000);
catch (InterruptedException e)
throw new RuntimeException(e);
System.out.println("save to file>>>>");
// 异步处理
arrayList.add(null);// 空行
saveToFile(arrayList,SAVE_PATH_PREFIX+"\\\\repo_info_"+firstIndex+"_"+index+".csv",null);
System.out.println(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>");
System.out.println(">>>>>>>>>>>>>>>start new crawl (new index:"+index+")>>>>>>>>>>>>>>>>>>>>");
crawl(index);
// 默认type csv,后续拓展其他类型
void saveToFile(ArrayList<ArrayList<String>> data,String path,String type)
try
//追加写
BufferedWriter out =new BufferedWriter(new OutputStreamWriter(new FileOutputStream(path,true),"UTF-8"));
for (int i = 0; i < data.size(); i++)
ArrayList<String> row=data.get(i);
for (int j = 0; j < row.size(); j++)
out.write(delQuota(row.get(j)));
out.write(",");
out.newLine();
out.flush();
out.close();
catch (Exception e)
e.printStackTrace();
String delQuota(String str)
String result = str;
String[] strQuota = "~", "!", "@", "#", "$", "%", "^", "&", "*", "(", ")", "`", ";", "'", ",", ".", "/", ":", "/,", "<", ">", "?" ;
for (int i = 0; i < strQuota.length; i++)
if (result.indexOf(strQuota[i]) > -1)
result = result.replace(strQuota[i], "");
return result;
void saveToDb()
四、拓展设计
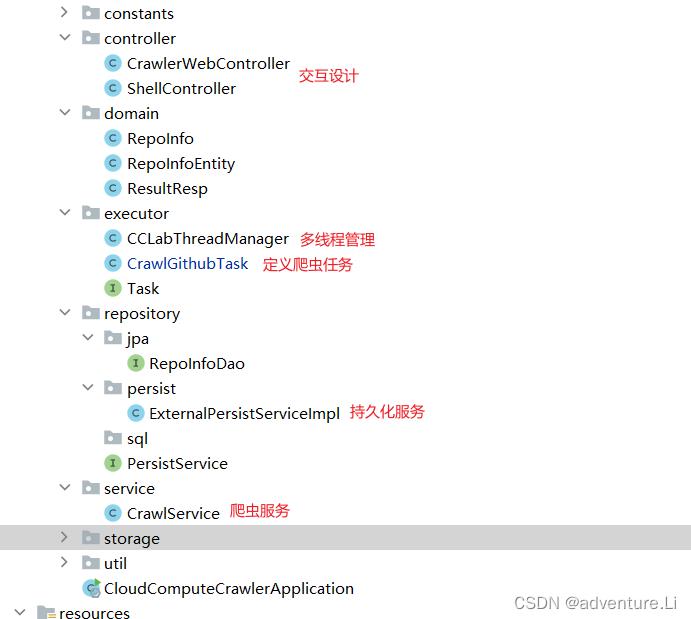
- 爬虫任务
package com.nju.crawler.executor;
import cn.hutool.http.HttpUtil;
import cn.hutool.json.JSONArray;
import cn.hutool.json.JSONNull;
import cn.hutool.json.JSONObject;
import com.nju.crawler.repository.PersistService;
import com.nju.crawler.storage.FileUtil;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/**
* @authorliyunfei
* @date2022/11/11
**/
public class CrawlGithubTask implements Runnable,Task
private static final String USER_INFO_URL = "https://api.github.com/users?repos%3E0&since=";// index
private static final String REPO_INFO_URL = "https://api.github.com/users/username/repos";
// 灵活、动态 -- 暂时先通过传参,后续可通过存MySQL动态去修改
private static final String LIMIT_TOKEN = "token ";
private static final String SAVE_PATH_PREFIX = "E:\\\\JavaProjects\\\\CourseProjects\\\\cloud-compute-lab\\\\cloud-compute-crawler\\\\src\\\\main\\\\resources\\\\files";
private volatile boolean isStop = false;
private String name;
private Integer startIndex;
private String savePathPrefix;
private PersistService persistService;
public CrawlGithubTask( String name,Integer startIndex,String savePathPrefix) //boolean isStop,
this.name = name;
this.startIndex = startIndex;
this.savePathPrefix = savePathPrefix;
public void setPersistService(PersistService persistService)
this.persistService = persistService;
@Override
public void run()
execute();
@Override
public void init()
//
void crawl(int index)
// 处理超时、反应结果
String json = HttpUtil.createGet(USER_INFO_URL+index)
.header("Authorization",LIMIT_TOKEN)
.execute()
.body();
if(json.contains("limit"))
// 限流--,请切换token执行
JSONArray jsonArray = new JSONArray(json);
Iterator iterator = jsonArray.iterator();
ArrayList<ArrayList<String>> arrayList = new ArrayList<>();
List<String> coreData = new ArrayList<>();// db value
ArrayList<ArrayList<String>> coreArrayList = new ArrayList<>();
List<Object[]> argsList = new ArrayList<>();
while (!isStop&&iterator.hasNext())
JSONObject userInfoResp = new JSONObject(iterator.next());
String userName = userInfoResp.getStr("login");
System.out.println("crawl>>>>>>>>>>>>>>>>>>"+userName+":repo>>>>>>>>>>>>>>>>>>>");
System.out.println(userName);
// 对仓库进行处理分析
json = HttpUtil.createGet( REPO_INFO_URL.replace("username",userName))
.header("Authorization",LIMIT_TOKEN)
.execute().body();
JSONArray jsonArray1 = new JSONArray(json);
Iterator iterator1 = jsonArray1.iterator();
System.out.println(userName+" repos size :"+jsonArray1.size());
while (!isStop&&iterator1.hasNext())
JSONObject jsonObject = new JSONObject(iterator1.next());
//System.out.println(jsonObject);
// 提取关键信息至数据库
String language = jsonObject.getStr("language");
String repoName = jsonObject.getStr("name");
String description=jsonObject.getStr("description");
Integer forks = jsonObject.getInt("forks");
Integer stargazers_count = jsonObject.getInt("stargazers_count");
Integer issues = jsonObject.getInt("open_issues_count");
Integer watchers = jsonObject.getInt("watchers");
Integer size = jsonObject.getInt("size");
String licenseName = jsonObject.getJSONObject("license").getStr("name");
String createTime = jsonObject.getStr("created_at");
String updateTime = jsonObject.getStr("updated_a以上是关于Java实现一个简单的GitHub仓库信息爬取的主要内容,如果未能解决你的问题,请参考以下文章