多目标跟踪算法 | DeepSort
Posted 一颗小树x
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多目标跟踪算法 | DeepSort相关的知识,希望对你有一定的参考价值。
前言
本文分享多目标跟踪算法的经典算法DeepSort,它是一个两阶段的算法,达到实时跟踪效果,曾被应用于工业开发。DeepSort是基于Sort目标跟踪进行的改进,它引入深度学习模型,在实时目标跟踪过程中,提取目标的外观特征进行最近邻近匹配。
目的:改善有遮挡情况下的目标追踪效果;同时,也减少了目标ID跳变的问题。
核心思想:使用递归的卡尔曼滤波和逐帧的匈牙利数据关联。
论文名称:(ICIP2017)Single-Simple Online and Realtime Tracking with a Deep Association Metric
论文地址:https://arxiv.org/abs/1703.07402
开源地址:https://github.com/nwojke/deep_sort

目录
一、通常的多目标跟踪工作流程
(1)给定视频的原始帧;
(2)运行对象检测器以获得对象的边界框;
(3)对于每个检测到的物体,计算出不同的特征,通常是视觉和运动特征;
(4)之后,相似度计算步骤计算两个对象属于同一目标的概率;
(5)最后,关联步骤为每个对象分配数字ID。
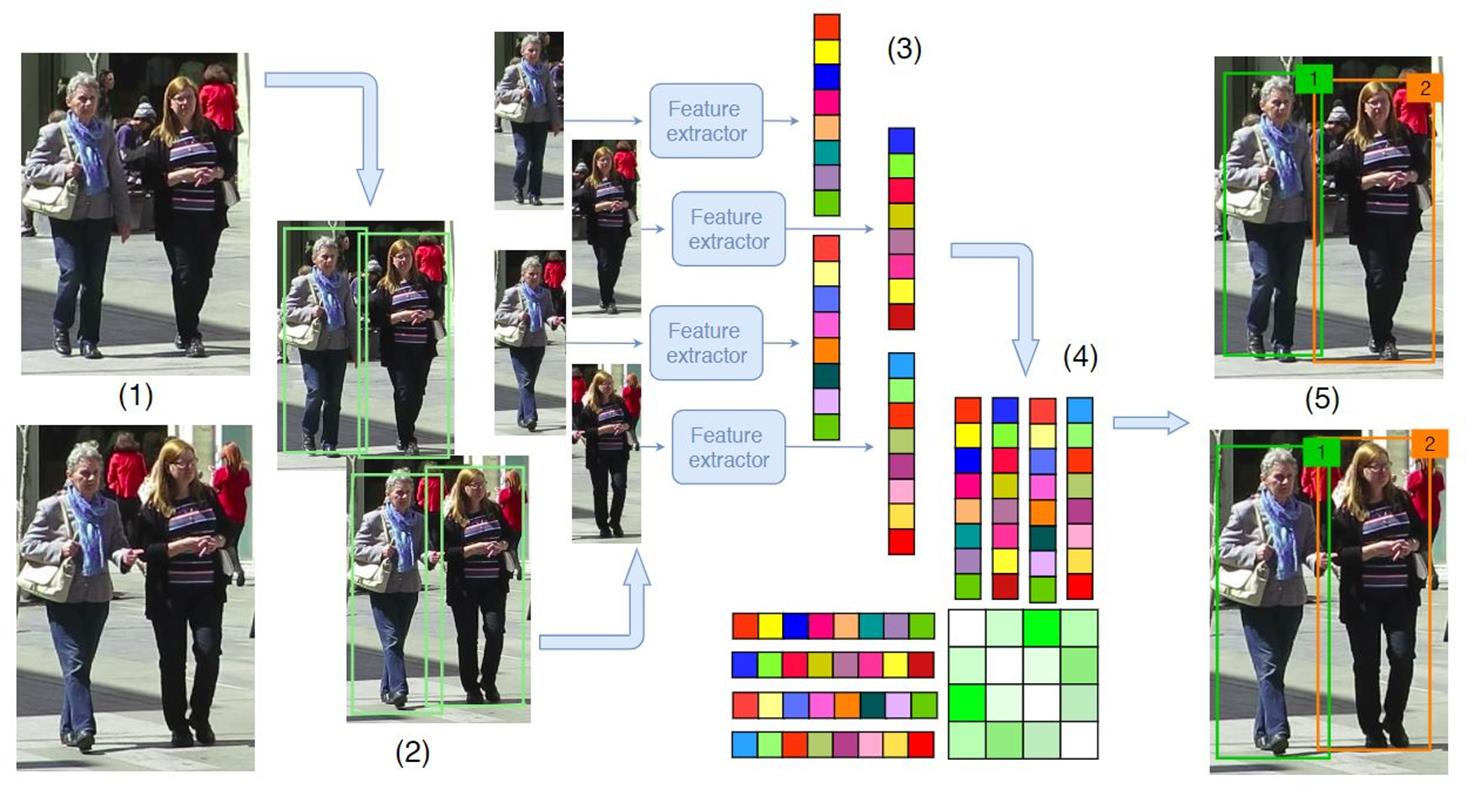
二、前提知识:Sort 多目标跟踪
四个核心步骤
1. 获取目标检测框,( 检测器: Faster R-CNN 、 YOLO )。 2. 卡尔曼滤波器预测当前位置 ,获得预测框。 3. 进行相似度计算,计算 前面的帧和当前帧目标 之间的匹配程度。(只考虑运动信息) 4. 通过匈牙利算法进行 数据关联,为每个对象分配目标的 ID 。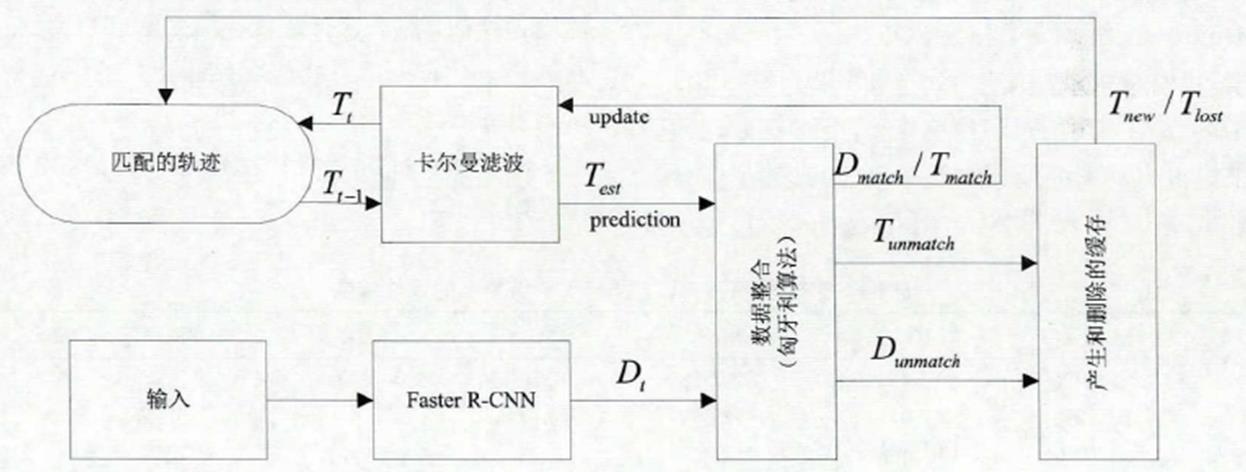
它以“每个检测框”与“现有目标的所有预测框”之间的IOU作为前后帧之间目标关系的度量指标。
算法核心
- 卡尔曼滤波的预测和更新过程。
- 匹配的过程。
其中,卡尔曼滤波可以基于目标前面时刻的位置,来预测当前时刻的位置。匈牙利算法可以告诉我们当前帧的某个目标,是否与前面帧的某个目标相同。
优点:Sort目标跟踪算法速度很快;在没有遮挡的情况下准确度很高。
缺点:它对物体遮挡几乎没有处理,导致ID switch 次数很高;在有遮挡情况下,准确度很低。
三、DeepSort 多目标跟踪
背景:DeepSort是基于Sort目标跟踪进行的改进,它引入深度学习模型,在实时目标跟踪过程中,提取目标的外观特征进行最近邻近匹配。
目的:改善有遮挡情况下的目标追踪效果;同时,也减少了目标ID跳变的问题。
核心思想:使用递归的卡尔曼滤波和逐帧的匈牙利数据关联。
四、卡尔曼滤波器——跟踪场景定义
假定跟踪场景是定义在 8 维状态空间(u, v, γ, h, ẋ, ẏ, γ̇, ḣ)中, 边框中心(u, v),宽高比 γ,高度 h 和和它们各自在图像坐标系中的速度。
这里依旧使用的是匀速运动模型,并把(u,v,γ,h)作为对象状态的直接观测量。

在目标跟踪中,需要估计目标的以下两个状态:
• 均值 (Mean) :包含目标的位置和速度信息,由 8 维向量( u, v, γ, h, ẋ, ẏ, γ̇, ḣ )表示,其中每个速度值初始化为 0 。均值 Mean 可以通过观测矩阵 H 投影到测量空间输出( u , v , γ , h )。 • 协方差 (Covariance) :表示估计状态的不确定性,由 8x8 的对角矩阵表示,矩阵中数字越大则表明不确定性越大。4.1 卡尔曼滤波器——预测阶段
•step1 :首先利用上一时刻 k-1 的后验估计值 ,通过 状态转移矩阵 F 变换,得到 当前时刻 k 的先验估计状态
其中,状态转移矩阵 F如下:

•step2:然后使用上一时刻 k-1 的后验估计协方差来计算当前时刻 k 的先验估计协方差

通过上一时刻的后验估计均值和方差 估计 当前时刻的先验估计均值x和协方差P
实现代码如下:
def predict(self, mean, covariance):
# mean, covariance 相当于上一时刻的后验估计均值和协方差
std_pos = [
self._std_weight_position * mean[3],
self._std_weight_position * mean[3],
1e-2,
self._std_weight_position * mean[3]]
std_vel = [
self._std_weight_velocity * mean[3],
self._std_weight_velocity * mean[3],
1e-5,
self._std_weight_velocity * mean[3]]
# 初始化噪声矩阵 Q
motion_cov = np.diag(np.square(np.r_[std_pos, std_vel]))
# x' = Fx
mean = np.dot(self._motion_mat, mean)
# P' = FPF^T + Q
covariance = np.linalg.multi_dot((
self._motion_mat, covariance, self._motion_mat.T)) + motion_cov
# 返回当前时刻的先验估计均值 x 和协方差 P
return mean, covariance4.2 卡尔曼滤波器——更新阶段
- step1:首先利用先验估计协方差矩阵 P 和观测矩阵 H 以及测量状态协方差矩阵 R 计算出卡尔曼增益矩阵 K

- step2:然后将卡尔曼滤波器的先验估计值 x 通过观测矩阵 H 投影到测量空间,并计算出与测量值 z 的残差 y


- step3:将卡尔曼滤波器的预测值和测量值按照卡尔曼增益的比例相融合,得到后验估计值 x

- step4:计算出卡尔曼滤波器的后验估计协方差

卡尔曼滤波器更新阶段,代码实现:
def update(self, mean, covariance, measurement):
# 将先验估计的均值和协方差映射到检测空间,得到 Hx' 和 HP'
projected_mean, projected_cov = self.project(mean, covariance)
chol_factor, lower = scipy.linalg.cho_factor(
projected_cov, lower=True, check_finite=False)
# 计算卡尔曼增益 K
kalman_gain = scipy.linalg.cho_solve(
(chol_factor, lower), np.dot(covariance, self._update_mat.T).T,
check_finite=False).T
# y = z - Hx'
innovation = measurement - projected_mean
# x = x' + Ky
new_mean = mean + np.dot(innovation, kalman_gain.T)
# P = (I - KH)P'
new_covariance = covariance - np.linalg.multi_dot((
kalman_gain, projected_cov, kalman_gain.T))
# 返回当前时刻的后验估计均值 x 和协方差 P
return new_mean, new_covariance总结一下:
在目标跟踪中,需要估计目标的以下两个状态:
• 均值 (Mean) :包含目标的位置和速度信息,由 8 维向量( u, v, γ, h, ẋ, ẏ, γ̇, ḣ )表示,其中每个速度值初始化为 0 。均值 Mean 可以通过观测矩阵 H 投影到测量空间输出( u , v , γ , h )。 • 协方差 (Covariance) :表示估计状态的不确定性,由 8x8 的对角矩阵表示,矩阵中数字越大则表明不确定性越大。predict 阶段和 update 阶段都是为了计算出卡尔曼滤波的估计均值 x 和协方差 P,不同的是前者是基于上一历史状态做出的先验估计,而后者则是融合了测量值信息并作出校正的后验估计。
五、匈牙利匹配——跟踪场景定义
解决卡尔曼滤波器的预测状态和测量状态之间的关联,可以通过构建匈牙利匹配来实现。
两个状态关联
- 卡尔曼滤波器的预测状态,后验的结果
- 测量状态,检测器的结果。
两个指标来实现关联
- 运动信息(用“马氏距离” 来计算)
- 外观特征(用“余弦距离” 来计算)
最后,使用线性加权和,将两个指标结合起来。
5.1、匈牙利匹配——马氏距离 关联 运动状态
马氏距离又称为协方差距离,是一种有效计算两个未知样本集相似度的方法,度量预测和检测的匹配程度。为了整合物体的运动信息,使用了预测状态和测量状态之间的(平方)马氏距离:
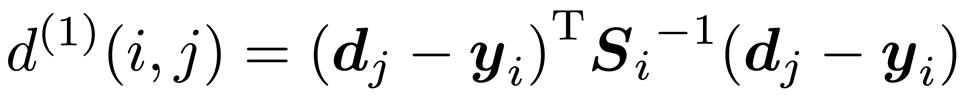
其中,d 和 y 分别代表测量分布和预测分布;S 为两个分布之间的协方差矩阵,它是一个实对称正定矩阵,可以使用 Cholesky 分解来求解马氏距离。
作用:马氏距离通过计算“预测框”距离“检测框”有多远的偏差,来估计跟踪器状态的不确定性。
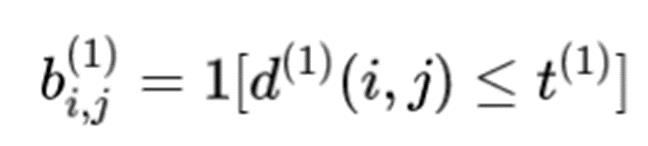
这是一个指示器,比较的是马氏距离和卡方分布的阈值,9.4877,如果马氏距离小于该阈值,代表成功匹配。
注意:由于测量分布的维度(4 维)和预测分布的维度(8 维)不一致,因此需要先将预测分布通过观测矩阵 H 投影到测量空间中(这一步其实就是从 8 个估计状态变量中取出前 4 个测量状态变量。),代码实现:
# Project state distribution to measurement space.
def project(self, mean, covariance):
std = [
self._std_weight_position * mean[3],
self._std_weight_position * mean[3],
1e-1,
self._std_weight_position * mean[3]]
# 初始化测量状态的协方差矩阵 R
innovation_cov = np.diag(np.square(std)) # 使用的是对角矩阵,不同维度之间没有关联
# 将均值向量映射到检测空间 得到 Hx
mean = np.dot(self._update_mat, mean)
# 将协方差矩阵映射到检测空间,得到 HP'H^T
covariance = np.linalg.multi_dot((
self._update_mat, covariance, self._update_mat.T))
return mean, covariance + innovation_cov # 加上测量噪声计算马氏距离,代码实现:
# Compute gating distance between state distribution and measurements.
def gating_distance(self, mean, covariance, measurements,
only_position=False):
# 首先需要先将预测状态分布的均值和协方差投影到测量空间
mean, covariance = self.project(mean, covariance)
# 假如仅考虑中心位置
if only_position:
mean, covariance = mean[:2], covariance[:2, :2]
measurements = measurements[:, :2]
# 对协方差矩阵进行 cholesky 分解
cholesky_factor = np.linalg.cholesky(covariance)
# 计算两个分布之间对差值
d = measurements - mean
# 通过三角求解计算出马氏距离
z = scipy.linalg.solve_triangular(
cholesky_factor, d.T, lower=True, check_finite=False,
overwrite_b=True)
# 返回平方马氏距离
squared_maha = np.sum(z * z, axis=0)
return squared_maha5.2、匈牙利匹配——余弦距离 关联 外观特征
背景:
当物体运动状态的不确定性比较低时,使用马氏距离确实是一个不错的选择。由于卡尔曼滤波器使用的是匀速运动模型,它只能对物体的运动位置提供一个相对粗略的线性估计。当物体突然加速或减速时,跟踪器的预测框和检测框之间的距离就会变得比较远,这时仅使用马氏距离就会变得非常不准确。
设计:
DeepSort 还对每个目标设计了一个深度外观特征描述符,它其实是一个在行人重识别数据集上离线训练的 ReID 网络提取到的 128 维单位特征向量(模长为 1 )。对于每个追踪器 tracker,保留它最后 100 个与检测框关联成功的外观特征描述符集合 R 并计算出它们和检测框的最小余弦距离:
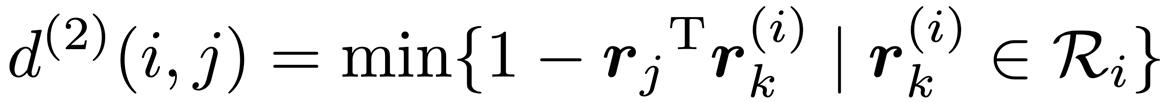
然后,可以设置一个合适的阈值来排除那些外观特征相差特别大的匹配。
ReID 网络:
Deep Sort 采用了经过大规模人员重新识别数据集训练的 Cosine 深度特征网络,该数据集包含 1,261 位行人的 1,100,000 多张图像,使其非常适合在人员跟踪环境中进行深度度量学习。
Cosine 深度特征网络使用了宽残差网络,该网络具有 2 个卷积层和 6 个残差块,L2 归一化层能够计算不同行人间的相似性,以与余弦外观度量兼容。通过计算行人间的余弦距离,余弦距离越小,两行人图像越相似。Cosine 深度特征网络结构如下图所示。
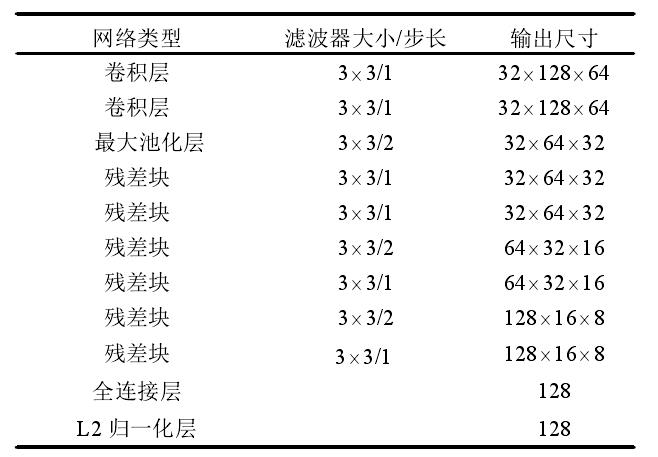
使用 Cosine 深度特征网络参数,将每个检测框 内图片压缩为最能表征图片特异信息的128维向量,并归一化后得到外观描述向量。
内图片压缩为最能表征图片特异信息的128维向量,并归一化后得到外观描述向量。
这里轨迹使用外观特征向量库保存近期匹配成功的外观特征向量,并在匹配时去余弦距离中最小距离可以适应短时遮挡情况。比如:当前被遮挡,则使用以往外观信息判别,只要进30帧中有出现过较好的匹配,则匹配上该轨迹和检测,较好地减少了遮挡问题。
余弦距离关联外观特征 具体展开:
使用余弦距离来度量表观特征之间的距离,reid模型抽出得到一个128维的向量,使用余弦距离来进行比对:
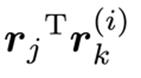 是余弦相似度,而余弦距离=1-余弦相似度,通过余弦距离来度量卡尔曼预测的表观特征和检测器对应的表观特征,来更加准确地预测ID。SORT中仅仅用运动信息进行匹配会导致ID Switch比较严重,引入外观模型+级联匹配可以缓解这个问题。
是余弦相似度,而余弦距离=1-余弦相似度,通过余弦距离来度量卡尔曼预测的表观特征和检测器对应的表观特征,来更加准确地预测ID。SORT中仅仅用运动信息进行匹配会导致ID Switch比较严重,引入外观模型+级联匹配可以缓解这个问题。
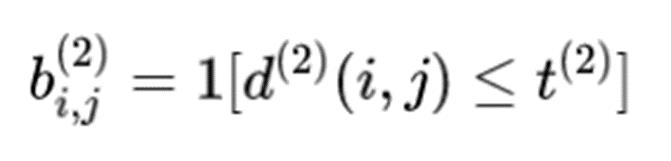
同上,余弦距离这部分也使用了一个指示器,如果余弦距离小于,则认为匹配上。这个阈值在代码中被设置为0.2(由参数max_dist控制),这个属于超参数,在人脸识别中一般设置为0.6。
5.3、匈牙利匹配——相互补充
两个指标可以互相补充从而解决关联匹配的不同问题:
一方面,马氏距离基于运动可以提供有关可能的物体位置的信息,这对于短期预测特别有用;
另一方面,当运动的判别力较弱时,余弦距离会考虑外观信息,这对于长时间遮挡后恢复身份特别有用。
为了建立关联问题,我们使用加权和将两个指标结合起来:

可以通过超参数 λ 来控制每个指标对合并成本的影响。在论文的实验过程中,发现当摄像机运动较大时,将 λ=0 是合理的选择(此时仅用到了外观信息)。
六、级联匹配——跟踪场景
当物体被长时间遮挡时,卡尔曼滤波器不能对目标状态准确预测。因此,概率质量在状态空间中散布,并且观察似然性的峰值降低。但是,当两个轨迹竞争同一检测结果时,马氏距离会带来较大的不确定性。因为它有效地减少了任何检测的标准偏差与投影轨迹均值之间的距离,而且可能导致轨迹碎片化增加和不稳定的轨迹。因此,Deep Sort引入了级联匹配,来更加频繁出现的目标赋予优先权,具体算法伪代码如下:

在级联匹配的花费矩阵里,元素值为马氏距离和余弦距离的加权和。实现代码:
def matching_cascade(
distance_metric, max_distance, cascade_depth, tracks, detections,
track_indices=None, detection_indices=None):
if track_indices is None:
track_indices = list(range(len(tracks)))
if detection_indices is None:
detection_indices = list(range(len(detections)))
unmatched_detections = detection_indices
matches = []
# 遍历不同年龄
for level in range(cascade_depth):
if len(unmatched_detections) == 0: # No detections left
break
# 挑选出对应年龄的跟踪器
track_indices_l = [
k for k in track_indices
if tracks[k].time_since_update == 1 + level
]
if len(track_indices_l) == 0: # Nothing to match at this level
continue
# 将跟踪器和尚未匹配的检测框进行匹配
matches_l, _, unmatched_detections = \\
min_cost_matching(
distance_metric, max_distance, tracks, detections,
track_indices_l, unmatched_detections)
matches += matches_l
# 挑选出未匹配的跟踪器
unmatched_tracks = list(set(track_indices) - set(k for k, _ in matches))
return matches, unmatched_tracks, unmatched_detections该匹配的精髓在于:挑选出所有 confirmed tracks,优先让那些年龄较小的 tracks 和未匹配的检测框相匹配,然后才轮得上那些年龄较大的 tracks 。
这就使得在相同的外观特征和马氏距离的情况下,年龄较小的跟踪器更容易匹配上。至于年龄 age 的定义,跟踪器每次 predict 时则 age + 1。
七、IOU匹配——跟踪场景
这个阶段是发生在级联匹配之后,匹配的跟踪器对象为那些 unconfirmed tracks 以及上一轮级联匹配失败中 age 为 1 的 tracks. 这有助于解决因上一帧部分遮挡而引起的突然出现的外观变化,从而减少被遗漏的概率。
# 从所有的跟踪器里挑选出 unconfirmed tracks
unconfirmed_tracks = [
i for i, t in enumerate(self.tracks) if not t.is_confirmed()]
# 从上一轮级联匹配失败的跟踪器中挑选出连续 1 帧没有匹配上(相当于age=1)
# 的跟踪器,并和 unconfirmed_tracks 相加
iou_track_candidates = unconfirmed_tracks + [
k for k in unmatched_tracks_a if
self.tracks[k].time_since_update == 1]
# 将它们与剩下没匹配上的 detections 进行 IOU 匹配
matches_b, unmatched_tracks_b, unmatched_detections = \\
linear_assignment.min_cost_matching(
iou_matching.iou_cost, self.max_iou_distance, self.tracks,
detections, iou_track_candidates, unmatched_detections)八、实验结果
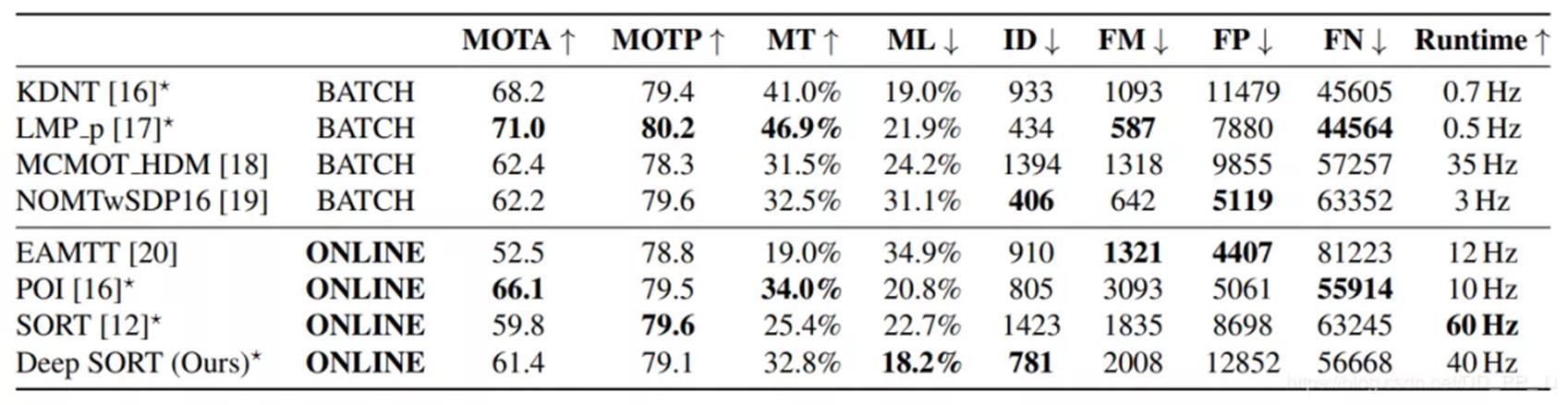
- 选用MOTA、MOTP、MT、ML、FN、ID swiches、FM等指标进行评估模型。
- 相比SORT, Deep SORT的ID Switch指标下降了45%,达到了当时的SOTA。经过实验,发现Deep SORT的MOTA、MOTP、MT、ML、FN指标对于之前都有提升。
- FP很多,主要是由于Detection和Max age过大导致的。
- 速度达到了20Hz,其中一半时间都花费在表观特征提取。
九、Deep Sort开源代码
基于YOLO的Deep-Sort算法,网络上有不同版本的开源代码,下面三个分别是基于YOLOv5、YOLOv4、YOLOv3 实现的Deep Sort 多目标跟踪系统。
【1】YOLOv5+Pytorch+Deep Sort
开源代码地址:Yolov5_DeepSort_Pytorch
YOLOv5生成的检测结果是一系列在 COCO 数据集上预训练的对象检测架构和模型,被传递到Deep Sort多目标跟踪对象算法。
开发环境:
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3.1
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
seaborn>=0.11.0
pandas
easydict模型效果:

【2】YOLOv4+TF+Deep Sort
开源代码地址:Deep-SORT-YOLOv4-tf
开发环境:
# $ conda create --name <env> --file <this file>
# platform: linux-64
imutils=0.5.3=pypi_0
keras=2.3.1=pypi_0
matplotlib=3.2.1=pypi_0
numpy=1.18.4=pypi_0
opencv-python=4.2.0.34=pypi_0
pillow=7.1.2=pypi_0
python=3.6.10=h7579374_2
scikit-learn=0.23.1=pypi_0
scipy=1.4.1=pypi_0
tensorboard=2.2.1=pypi_0
tensorflow=2.0.0=pypi_0
tensorflow-estimator=2.1.0=pypi_0
tensorflow-gpu=2.2.0=pypi_0模型效果:

【3】YOLOv3+Pytorch+Deep Sort
开源代码地址:Deep-Sort_pytorch-yolov3
开发环境:
python 3 (python2 not sure)
numpy
scipy
opencv-python
sklearn
torch >= 0.4
torchvision >= 0.1
pillow
vizer
edict模型效果:

本文参考
[1] 包俊,董亚超,刘宏哲.基于Deep_Sort的目标跟踪算法综述.北京联合大学北京市信息服务工程重点实验室.
[2] 朱镇坤,戴德云,王纪凯,陈宗海.基于FasterR_CNN的多目标跟踪算法设计.中国科学技术大学自动化系.
[3] 谢佳形.拥挤场景下视频多目标跟踪算法研究.浙江大学.
[4] 谷燕飞.基于改进YOLO_V3+Deepsort多目标跟踪系统的研究与实现.辽宁大学.
网络文章参考:
参考1:https://zhuanlan.zhihu.com/p/97449724
参考2:https://yunyang1994.gitee.io/2021/08/27/DeepSort-%E5%A4%9A%E7%9B%AE%E6%A0%87%E8%B7%9F%E8%B8%AA%E7%AE%97%E6%B3%95-SORT-%E7%9A%84%E8%BF%9B%E9%98%B6%E7%89%88/
参考3:https://mp.weixin.qq.com/s?__biz=MzA4MjY4NTk0NQ==&mid=2247485748&idx=1&sn=eb0344e1fd47e627e3349e1b0c1b8ada&chksm=9f80b3a2a8f73ab4dd043a6947e66d0f95b2b913cdfcc620cfa5b995958efe1bb1ba23e60100&scene=126&sessionid=1587264986&key=1392818bdbc0aa1829bb274560d74860b77843df4c0179a2cede3a831ed1c279c4603661ecb8b761c481eecb80e5232d46768e615d1e6c664b4b3ff741a8492de87f9fab89805974de8b13329daee020&ascene=1&uin=NTA4OTc5NTky&devicetype=Windows+10+x64&version=62090069&lang=zh_CN&exportkey=AeR8oQO0h9Dr%2FAVfL6g0VGE%3D&pass_ticket=R0d5J%2BVWKbvqy93YqUC%2BtoKE9cFI22uY90G3JYLOU0LtrcYM2WzBJL2OxnAh0vLo
参考4:https://zhuanlan.zhihu.com/p/80764724
论文地址:https://arxiv.org/abs/1703.07402
开源地址:https://github.com/nwojke/deep_sort
本文只供大家参考学习,谢谢。如有错误,欢迎指出~
以上是关于多目标跟踪算法 | DeepSort的主要内容,如果未能解决你的问题,请参考以下文章