Redis的缓存穿透和缓存雪崩
Posted 未来.....
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis的缓存穿透和缓存雪崩相关的知识,希望对你有一定的参考价值。
Redis的缓存穿透和缓存雪崩
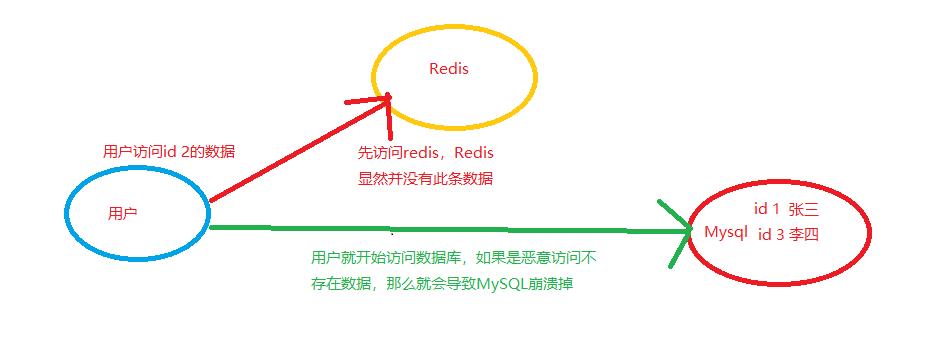
先想一想,redis缓存作为数据库前面的一道门槛,它能极大的减少了直接访问数据库而造成的数据库崩溃,但是此时缓存中没有所访问的数据,用户是会直接访问数据库,那么此时就出现问题了,缓存中没有,就会去查询数据库,每一次查询都会检索一次数据库信息,那么此时有人如果恶意大量访问这条不存在的数据呢?
没错,就是想象的那样,数据库会因为大量访问而崩溃,进而导致整个系统停止运行。
上面这个问题所说的就是缓存穿透,那么该如何解决呢?
1、Redis的缓存穿透
现象:缓存穿透是指查询一个根本不存在的数据,缓存层和持久层都不会命中。在日常工作中出于容错的考虑,如果从持久层查不到数据则不写入缓存层,缓存穿透将导致不存在的数据每次请求都要到持久层去查询,失去了缓存保护后端持久的意义。
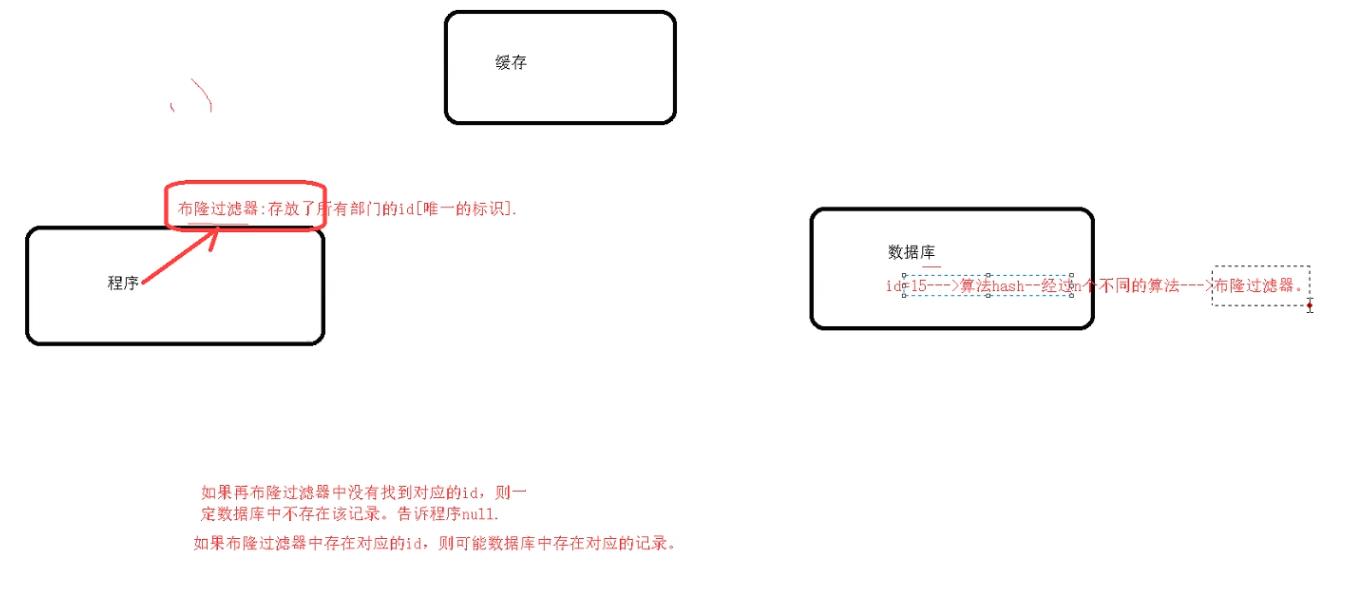
解决方案:
- 如果数据库中不存在该对象,则往缓存中放入一个空对象,并且设置很短的过期时间。
但是这样不方便,如果每次访问都是不存在该对象,然后在缓存中放入一个空对象,这样会占用大量的key和value,需要更多的内存空间。**有没有更好的解决方法呢?**答案是有的 - 使用布隆过滤器拦截
布隆过滤器:
简单介绍一下吧:
布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置的合理,它的精确度可以控制的相对足够精确,只会有小小的误判概率。
 为什么说会有误判呢?
为什么说会有误判呢?
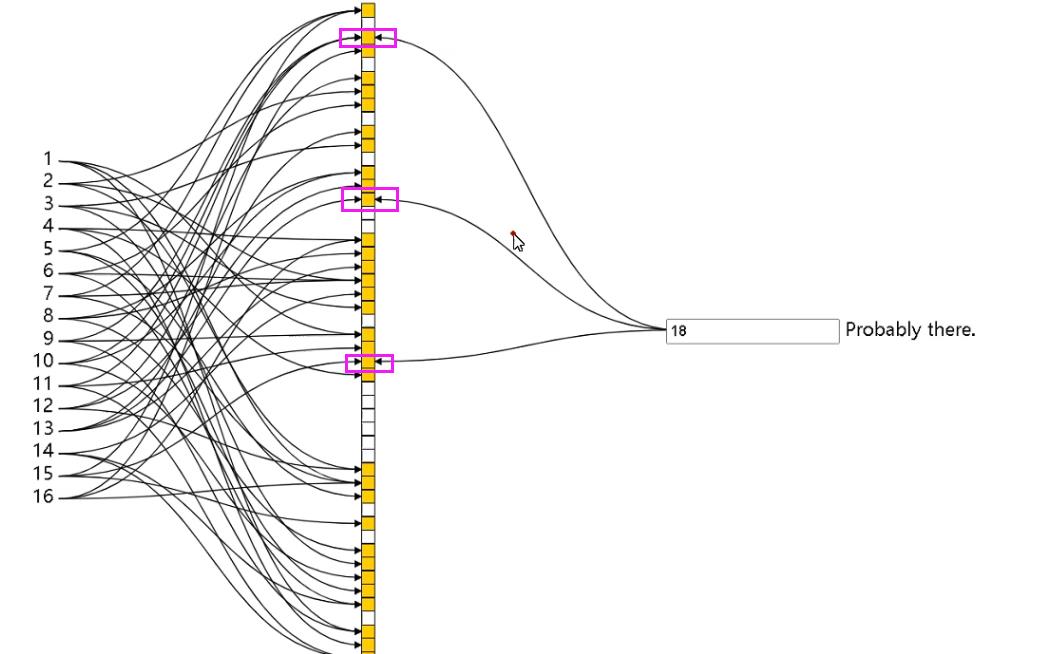
每个布隆过滤器对应到 Redis 的数据结构里面就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组比较稀疏,判断正确的概率就会很大,如果这个位数组比较拥挤,判断正确的概率就会降低。
如果所示,此时左边是已经存在的数据,而右边是模拟出来的,此时就会出现误判现象,此时使用的三次hash算法,可以使用4次或者更高的次数进行加密计算,误判的几率机会下降。
在说缓存雪崩之前先想一个问题,如果你的项目刚上线,你的Redis里面是没有任何数据的,此时大量的用户会直接访问数据库,此时数据库会因为访问量过大,导致宕机,又或者你的Redis里面同一时间有大量的缓存时间到了,大量数据消失,此时也会大量访问你的数据库,那么该如何解决呢?
2、Redis的缓存雪崩
解决方法:
- 在项目上线前,提前预加载热点数据,保证用户不会因为缓存不存在而直接访问数据库。
- 采用Redis集群,保证节点因为访问数量过大,导致缓存雪崩。
- 使用队列,使得每次请求的是数据库所能承受的。
以上是关于Redis的缓存穿透和缓存雪崩的主要内容,如果未能解决你的问题,请参考以下文章