自动搜索数据增强方法分享——fast-autoaugment
Posted 随煜而安
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动搜索数据增强方法分享——fast-autoaugment相关的知识,希望对你有一定的参考价值。
前言
简短的介绍下分享fast-autoaugment的原因
毫无疑问数据增强对于训练CNN非常有效,大家也在不断发明新的数据增强方法
拿到一份数据集,我们凭借之前的经验组合不同的增强方法形成一个数据增强策略,通常可以得到一个还不错的baseline。但如何更进一步,让模型再提升1-2个百分点就很困难了。通常我是进行一些数据增强效果的可视化,选定一个潜在的优化方向(比如旋转的幅度是否过大了),然后调整对应的超参数进行一组对比实验。
当问题发展到这个阶段时,人工优化的成本已经很高而且很可能收效甚微了。针对这个问题,开始有人尝试借助AutoML这个新技术来进行数据增强策略的筛选。
这里面最有代表性的应该算是2019年google提出的AutoAugment,该方法借助强化学习来自动的在给定的数据集上探索最优的数据增强策略。AutoAugment在包括ImageNet,CIFAR-10等在内的多个数据集上,与人工设计的数据增强策略所训练出的baseline相比,都取得了显著提升。
但AutoAugment即使是在CIFAR-10这样的小数据集上,探索出一个数据增强策略,都要花费5000个GPU hours,这显然是个致命的缺点。
截至到今天,我发现了两篇优秀的paper,他们都在借鉴AutoAugment的基础上,实现了大幅的提速,分别是:
PBA: Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules
Fast AutoAugment 提出了一种方法,避免了调整不同数据增强参数不停的重复训练网络这个超级消耗GPU的步骤,从而获得了100-1000倍的速度提升,并且能够和AutoAugment取得近似的效果,这也是我打算学习和分享这篇paper的原因。
至于PBA,由于这篇paper我还没看,所以暂时不讨论,当然PBA和Fast AutoAugment哪个效果好,也是之后值得讨论的问题。
em… 前两天google又出来一个RandAugment,一个个跟进
现有数据增强方法总结
ShearX, ShearY

TranslateX, TranslateY

Rotate

AutoContrast
调整图像对比度。计算一个输入图像的直方图,从这个直方图中去除最亮和最暗的部分,然后重新映射图像,以便保留的最暗像素变为黑色,即0,最亮的变为白色,即255。

Invert
将输入图像转换为反色图像。

Equalize
直方图均衡化,产生像素值均匀分布的图像

Solarize
反转在阈值threshold范围内的像素点(>threshold的像素点取反)
例如一个像素的取值为124=01111100
如果threshold=100,返回的结果为131=10000011
如果threshold=200,返回结果为124 (124<200)

Posterize
色调分离,将每个颜色通道上像素值对应变量的最低的(8-x)个比特位置0,x的取值范围为[0,8]

Contrast
调整图片的对比度
ImageEnhance.Contrast(img).enhance(v)
v = 1 保持原始图像, v < 1 像素值间差距变小, v > 1 增强对比度,像素值间差异变大

Color
调整图片的饱和度
ImageEnhance.Color(img).enhance(v)
v = 1 保持原始图像, v < 1 饱和度减小趋于灰度图, v > 1 饱和度增大色情更饱满

Brightness
调整图片的亮度
ImageEnhance.Brightness(img).enhance(v)
v = 1 保持原始图像, v < 1 亮度减小, v > 1 亮度增大

Sharpness
调整图片锐度
ImageEnhance.Sharpness(img).enhance(v)
v = 1 保持原始图像, v < 1 产生模糊图片, v > 1 产生锐化后的图片

Cutout
Improved Regularization of Convolutional Neural Networks with Cutout
对训练图像进行随机遮挡,该方法激励神经网络在决策时能够更多考虑次要特征,而不是主要依赖于很少的主要特征


Cutout是一种类似于DropOut的正则化方法,被证明对于模型涨点非常有效。
Random erasing
Random erasing其实和cutout非常类似,也是一种模拟物体遮挡情况的数据增强方法。区别在于,cutout每次裁剪掉的区域大小是固定的,Random erasing替换掉的区域大小是随机的, 使用随机数替换。

Sample Pairing
Data Augmentation by Pairing Samples for Images Classification
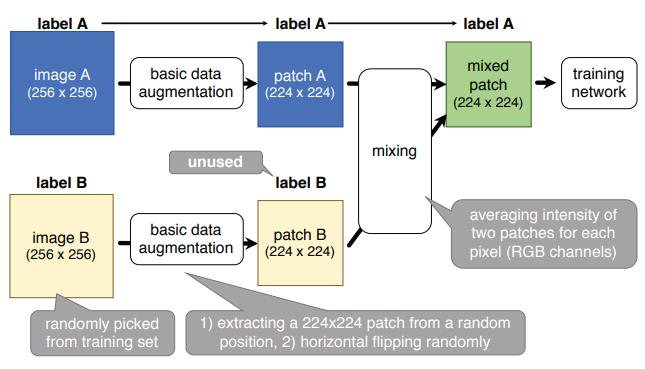
Mixup
mixup: BEYOND EMPIRICAL RISK MINIMIZATION
原理可以简单概括为随机抽取两个样本进行简单的随机加权求和,同时样本的标签也对应加权求和
Bag of Freebies for Training Object Detection Neural Networks中将mixup应用在目标检测算法上,同样效果也很好。
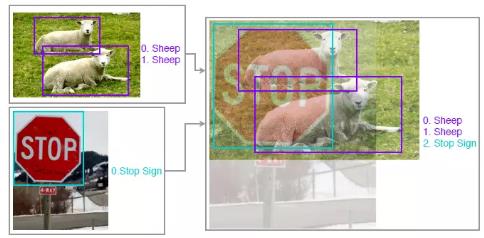
CutMix
Cutmix: Regularization strategy to train strong classifiers with localizable features

Ricap
Data Augmentation using Random Image Cropping and Patching for Deep CNNs
Fast AutoAugment
搜索空间
将paper中的公式简化成如下描述,按照最终的实验设置:
我们最终要搜索的总的数据增强方案,包含若干个策略policies
每个策略包含5个子策略sub-policies
每个子策略包含两个数据增强操作operations
每个operation对应了一种数据增强方法,有3个需要调整的参数,使用的具体数据增强方法,使用的概率p和使用的强度λ
每个子策略中的operations是串行结合在一起的。
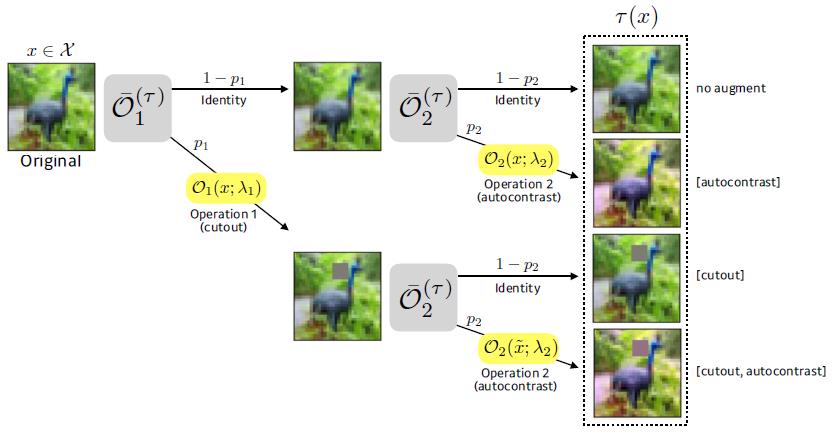
按照paper介绍,实验包含16个可选的operations(ShearX, ShearY, TranslateX, TranslateY, Rotate, AutoContrast, Invert,
Equalize, Solarize, Posterize, Contrast, Color, Brightness, Sharpness, Cutout, Sample Pairing),对于最后一个是否使用我目前存疑,因为我看作者给出的代码把这个方法注释掉了。
搜索空间与一个策略对应,因此按照实验的配置,对应了30个特征=(5个sub-policies)* (2个operations)* (每个operation三个参数:使用的数据增强方法,p和λ)
策略的搜索算法:Bayesian Optimization
策略的搜索算法使用Bayesian Optimization,即贝叶斯优化器采样出一组参数(对应了一个数据增强策略police),然后对这个策略的优劣进行评估(后面会介绍如何评估),将评估结果反馈给贝叶斯优化器进行学习,然后重新采样,反复迭代这个过程直到达到停止条件(paper中设置迭代次数B=200)。
采集函数使用的是Expected Improvement (EI),代理函数使用的是tree-structured Parzen estimator (TPE) algorithm。
贝叶斯优化的原理和流程之前已经介绍过了,稍有区别的是,作者将这个数据集拆分成了K个子数据集(K=5),然后在K个子数据集上分别进行上述的贝叶斯优化过程,每次贝叶斯优化选出最优的N次采样作为候选策略(N=10),在同一个子数据集上贝叶斯优化重复T次(T=2)。
因此,整个过程中会产生 100 = K * T * N = 5 * 2 * 10 个候选的策略集合,最终的训练使用全部的数据集,并从候选集合中随机挑选策略进行数据增强。
整个搜索框架如下图所示:
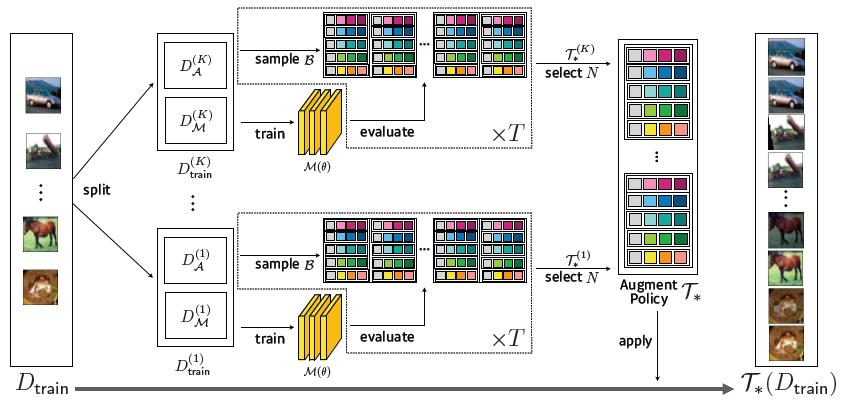
流程图如下图所示:

评价方法:Density Matching
评价一个数据增强策略好坏的最直接且准确的方法就是用这个策略在训练集上,使用最终要使用的网络执行完整的训练流程,然后看验证集的准确率,为了减小随机误差通常还要进行重复实验取平均。这个过程会非常耗时,通常会使用一个小得多的代理CNN网络,并缩小训练数据集的规模,来减少搜索策略的耗时,但这也会引入很大的误差,导致效果不好。
本文的作者从另一个角度来看待数据增强方法优劣的评估问题。按文中所述:
对于任何给定的训练集Dtrain和验证集Dvalid,我们的目标是搜索能够让未增强的Dtrain与增强后的Dvalid密度匹配的数据增强策略来提高泛化能力。但是,直接比较这两个数据集的分布以评估每个候选策略是不切实际的。因此,我们通过在Dtrain上不使用数据增强时训练的模型,并在加上数据增强后的Dvalid上进行预测,使用预测结果的loss或者accuracy来评估一个数据集遵循另一个数据集的程度。
可以这样理解,一个已经尽可能拟合训练集(真实数据,未使用数据增强)的模型,如果去预测一个使用了数据增强后的测试集,并且能够取得很好的准确率,就认为这种数据增强方法是自然的,符合真实分布的,密度匹配的。
对于密度匹配,其实就是作者试图对提出方法进行的理论解释,我理解就是数据分布一致的含义。就像Mixup一样,有些方法原理其实很难解释,效果好就行。
这个基于“密度匹配”的评估方法是这篇paper最灵魂的贡献,实现起来也很简单,虽然原理很难去解释,但是这种方法巧妙的大幅降低了每次评估所需的计算量。
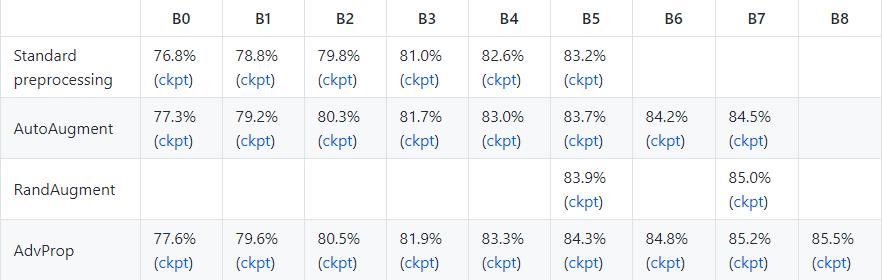
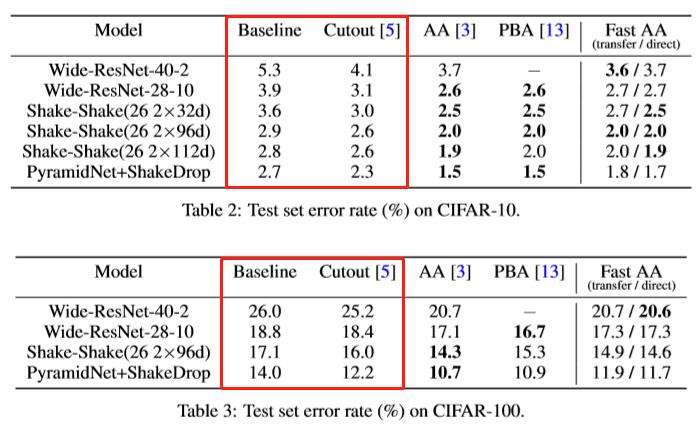
实验结果
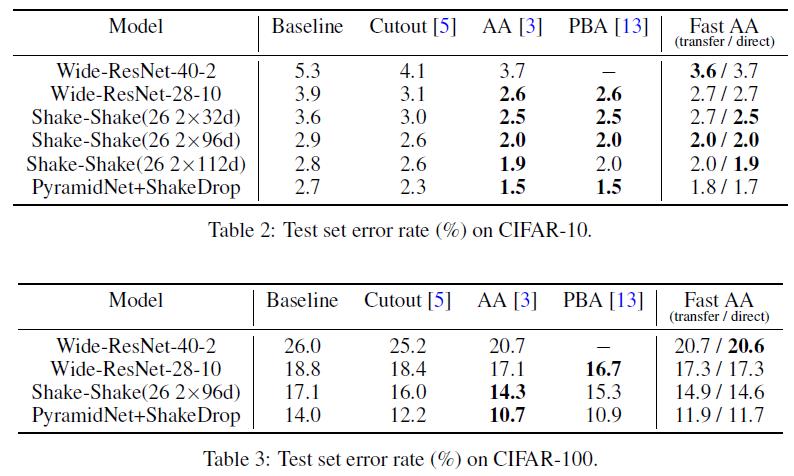
作者已经开源,方法到底好坏还要后面实际验证过才知道。先看看paper中给出的一些结果:

TodoList
1.几乎在所有任务上,Cutout都被证明有效,进行尝试
2.包括AutoAugment、PBA、Fast AutoAugment、RandAugment在内的这些方法,它们在ImageNet上已经搜出的策略,迁移到自己的任务上是否也能在baseline上获得提升。
3.阅读其它几篇论文,确认一个实验目标,尝试验证效果。
参考文献
数据增强方法 | 基于随机图像裁剪和修补的方式(文末源码共享)
Improved Regularization of Convolutional Neural Networks with Cutout
mixup: BEYOND EMPIRICAL RISK MINIMIZATION
Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules
以上是关于自动搜索数据增强方法分享——fast-autoaugment的主要内容,如果未能解决你的问题,请参考以下文章