Caffe详解Caffe的lenet_solver.prototxt
Posted Taily老段
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Caffe详解Caffe的lenet_solver.prototxt相关的知识,希望对你有一定的参考价值。
solver算是caffe的核心的核心,它协调着整个模型的运作。caffe程序运行必带的一个参数就是solver配置文件。
运行代码一般为:
caffe train --solver=*_slover.prototxt一般新建sh文件,添加caffe的绝对路径;在mobilenet.caffemodel基础上进行训练finetuning;
#!/usr/bin/env sh
/usr/local/Cellar/caffe/build/tools/caffe train -solver /Users/taily/meizu/mobilenet/solver.prototxt \\
-weights="/Users/taily/mobilenet/mobilenet.caffemodel" \\caffe程序的命令行执行格式如下:
caffe <command> <args>
其中的<command>有这样四种:
train
test
device_query
time
对应的功能为:
train----训练或finetune模型(model),
test-----测试模型
device_query---显示gpu信息
time-----显示程序执行时间
其中的<args>参数有:
-solver
-gpu
-snapshot
-weights
-iteration
-model
-sighup_effect
-sigint_effectsolver的主要作用就是交替调用前向(forward)算法和后向(backward)算法来更新参数,从而最小化loss,实际上就是一种迭代的优化算法。
到目前的版本,caffe提供了六种优化算法来求解最优参数,在solver配置文件中,通过设置type类型来选择。
Solver就是用来使loss最小化的优化方法。
Stochastic Gradient Descent (type: "SGD"),
AdaDelta (type: "AdaDelta"),
Adaptive Gradient (type: "AdaGrad"),
Adam (type: "Adam"),
Nesterov’s Accelerated Gradient (type: "Nesterov") and
RMSprop (type: "RMSProp")具体的每种方法的介绍,请看文章后半部分,前半部分着重介绍solver配置文件的编写。
Solver的流程:
1. 设计好需要优化的对象,以及用于学习的训练网络和用于评估的测试网络。(通过调用另外一个配置文件prototxt来进行)
2. 通过forward和backward迭代的进行优化来跟新参数。
3. 定期的评价测试网络。 (可设定多少次训练后,进行一次测试)
4. 在优化过程中显示模型和solver的状态
在每一次的迭代过程中,solver做了这几步工作:
1、调用forward算法来计算最终的输出值,以及对应的loss
2、调用backward算法来计算每层的梯度
3、根据选用的slover方法,利用梯度进行参数更新
4、记录并保存每次迭代的学习率、快照,以及对应的状态。
# The train/test net protocol buffer definition
# 训练和测试网络的协议定义(网络结构)
net: "examples/mnist/lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
#测试迭代次数;前向传播
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
#在MNIST中,批次100,迭代100
# covering the full 10,000 testing images.
#测试10000张
test_iter: 100
# Carry out testing every 500 training iterations.
#每500次训练迭代 进行一次测试;interval-间隔
#测试的间隔
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
#基础学习率,网络的动量和权值衰减
#学习率
base_lr: 0.01
#动量?直观上讲就是梯度高度敏感于参数空间的某些方向;加速学习;
momentum: 0.9
#权值衰减;代表损失函数中参数的正则化系数;
weight_decay: 0.0005
# The learning rate policy
#学习率的策略;方法不同,计算方式不一样;
lr_policy: "inv"
#如果设置为inv,还需要设置一个power, 返回base_lr * (1 + gamma * iter) ^ (- power)
gamma: 0.0001
power: 0.75
# Display every 100 iterations
#每100次迭代显示一次
display: 100
# The maximum number of iterations
#最大迭代次数
max_iter: 10000
# snapshot intermediate results
#截图中间结果;每 5000 iterations就可以得到
#model_iter_xxx.caffemodel 和model_iter_xxx.solverstate
#可以在已经训练好的基础上继续训练 -snapshot
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
# solver mode: CPU or GPU
#方式:CPU还是GPU
solver_mode: CPU
lr_policy:学习率的衰减策略
// The learning rate decay policy. The currently implemented learning rate
// policies are as follows:
// - fixed: always return base_lr.
// - step: return base_lr * gamma ^ (floor(iter / step))
// - exp: return base_lr * gamma ^ iter
// - inv: return base_lr * (1 + gamma * iter) ^ (- power)
// - multistep: similar to step but it allows non uniform steps defined by
// stepvalue
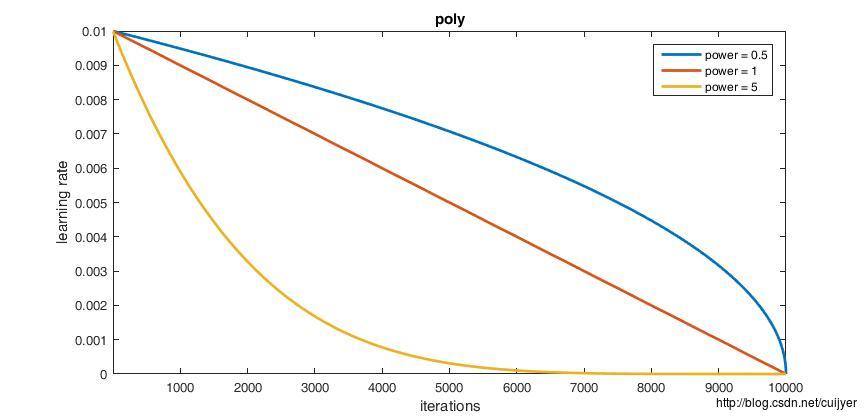
// - poly: the effective learning rate follows a polynomial decay, to be
// zero by the max_iter. return base_lr (1 - iter/max_iter) ^ (power)
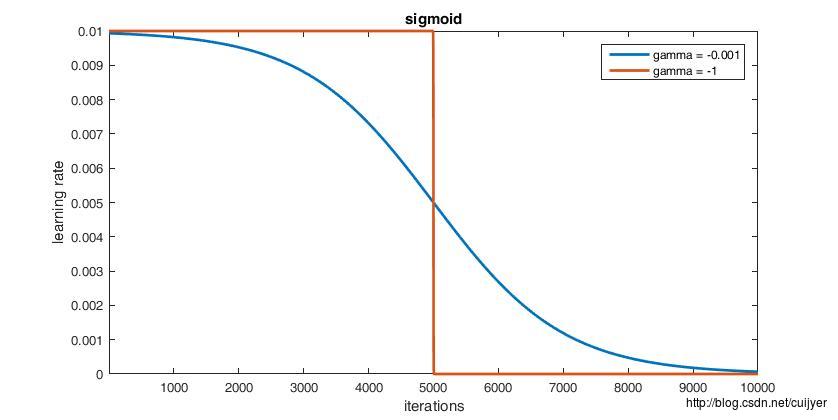
// - sigmoid: the effective learning rate follows a sigmod decay
// return base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))
//
// where base_lr, max_iter, gamma, step, stepvalue and power are defined
// in the solver parameter protocol buffer, and iter is the current iteration.

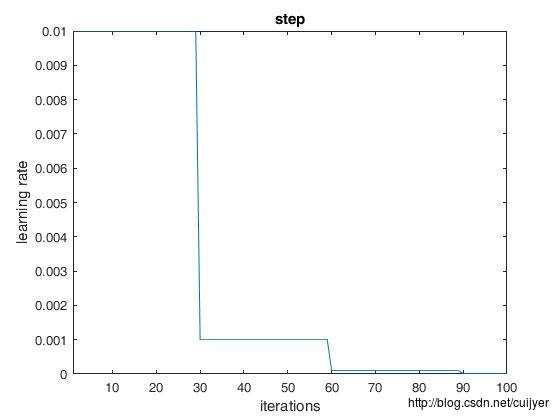
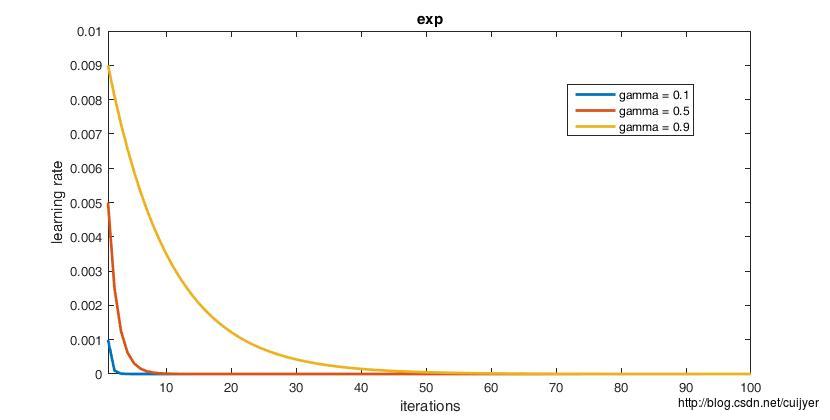
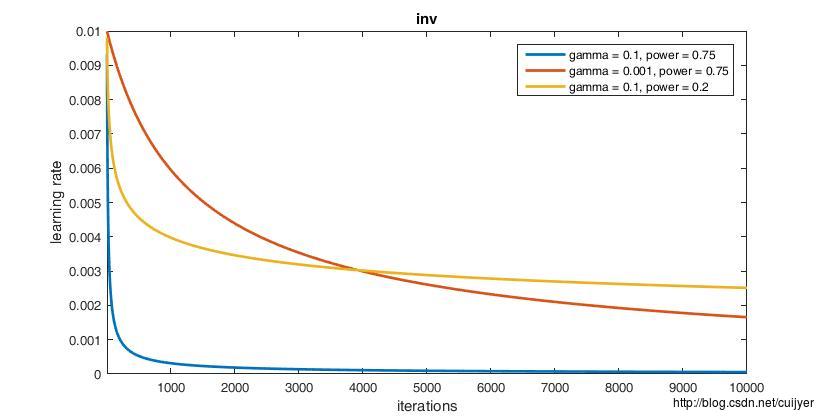
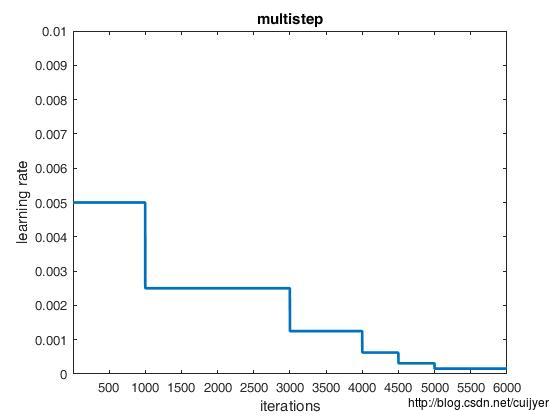
经验之谈
- 对于稀疏数据,尽量使用学习率可自适应的优化方法,不用手动调节,而且最好采用默认值
- SGD通常训练时间更长,但是在好的初始化和学习率调度方案的情况下,结果更可靠
- 如果在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用学习率自适应的优化方法。
- Adadelta,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多。
- 在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果


以上是关于Caffe详解Caffe的lenet_solver.prototxt的主要内容,如果未能解决你的问题,请参考以下文章