R 语言基础知识
Posted 大大大大大桃子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R 语言基础知识相关的知识,希望对你有一定的参考价值。
数据结构
先放一张 R 的基本数据结构,表被吓得吼 ☺️
代码地址: R-Basics
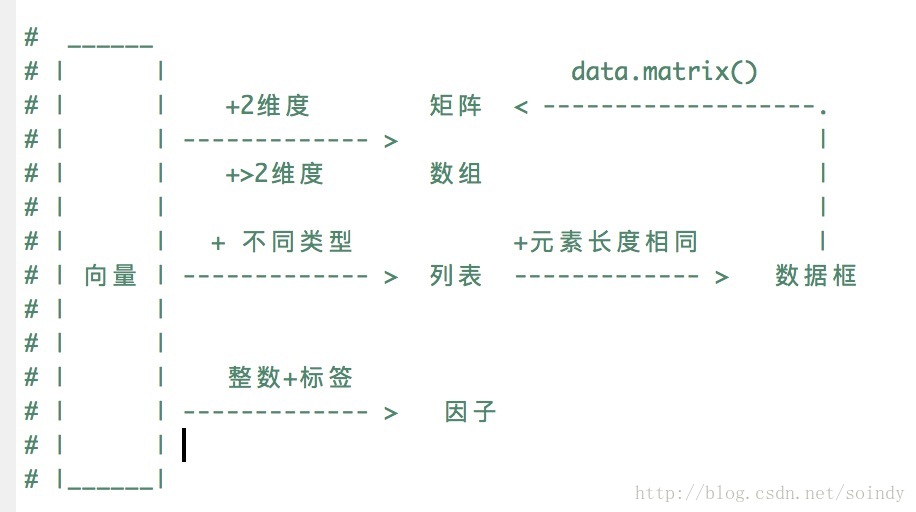
R 赋值
赋值 :
x <- 2console :
[1] 2 注: index 从 1 开始
向量 (vector)
只能包含同一类型的对象
# vector(mode = "logical", length = 0L) (类型,长度)
x <- vector("character",length = 4)console :
chr [1:4] "" "" "" ""或
x1 <- 1:4 console :
int [1:4] 1 2 3 4或
x2 <- c(1,2,3,4)console :
num[1:4] 1 2 3 4如果 c() 传的类型不一样,会内隐强制转换字符型 :
x3 <- c(TRUE, 2, "A", "2L")console :
chr [1:4] "TRUE" "2" "A" "2L"显式类型转换
as.numeric(x3)
as.logical(x3)
as.character(x3)属性 (attribute)
类型 (class)
查看类型 :
class(x)console :
[1] "numeric"- “numeric” 数值型;
- 2L: “integer”;
- TRUE: 大写;
- 2+2i: “complex”
长度 (length)
length(x3)console :
[1] 4维度 (dimensions: matrix, array)
如下, x3 是一个一维数组 :
matrix(x3)console :
[1,] "TRUE"
[2,] "2"
[3,] "A"
[4,] "2L"名称 (name)
names(x3) <- c("a","b","c","d")console :
/*
a b c d
"TRUE" "2" "A" "2L"
*/矩阵 (matrix)
向量 + 维度属性 (整数向量 : nrow,ncol)
# matrix(data = NA, nrow = 1, ncol = 1, byrow = FALSE, dimnames = NULL)x <- matrix(nrow = 3, ncol = 2)console :
# [,1] [,2]
# [1,] NA NA
# [2,] NA NA
# [3,] NA NAdim(x) console :
# [1] 3 2 3行2列维度
attributes(x)
# $dim
# [1] 3 2 y <- 1:6 #创建一个向量
dim(y) <- c(2,3) #添加维度信息console :
# > y
# [,1] [,2] [,3]
# [1,] 1 3 5
# [2,] 2 4 6 注意以上矩阵是按照列填充的
y2 <- matrix(1:6, nrow = 2,ncol = 3) # 和上面 y 是一样的行拼接
rbind(y,y2)console :
# [,1] [,2] [,3]
# [1,] 1 3 5
# [2,] 2 4 6
# [3,] 1 3 5
# [4,] 2 4 6列拼接
cbind(y,y2)console :
# [,1] [,2] [,3] [,4] [,5] [,6]
# [1,] 1 3 5 1 3 5
# [2,] 2 4 6 2 4 6数组
与矩阵类似,但是维度可以大于2 (矩阵维度只能等于2)
# array(data = NA, dim = length(data), dimnames = NULL)
x <- array(1:24, dim = c(4,6))console :
# [,1] [,2] [,3] [,4] [,5] [,6]
# [1,] 1 5 9 13 17 21
# [2,] 2 6 10 14 18 22
# [3,] 3 7 11 15 19 23
# [4,] 4 8 12 16 20 24x1 <- array(1:24,dim = c(2,3,4))console :
# , , 1
# [,1] [,2] [,3]
# [1,] 1 3 5
# [2,] 2 4 6
# , , 2
# [,1] [,2] [,3]
# [1,] 7 9 11
# [2,] 8 10 12
# , , 3
# [,1] [,2] [,3]
# [1,] 13 15 17
# [2,] 14 16 18
# , , 4
# [,1] [,2] [,3]
# [1,] 19 21 23
# [2,] 20 22 24列表 (list)
可以包含不同类型的对象 list()
l <- list("a",2,10L,3+4i,TRUE)console :
# [[1]]
# [1] "a"
# [[2]]
# [1] 2
# [[3]]
# [1] 10
# [[4]]
# [1] 3+4i
# [[5]]
# [1] TRUE
l1 <- list(a = 1, b = 2, c = 3)
# $a
# [1] 1
# $b
# [1] 2
# $c
# [1] 3
l2 <- list(c(1,2,3),c(4,5,6,7))
# [[1]]
# [1] 1 2 3
# [[2]]
# [1] 4 5 6 7命名
x <- matrix(1:6,nrow = 2,ncol = 3)
dimnames(x) <- list(c("a","b"),c("c","d","e"))console :
# > x
# c d e
# a 1 3 5
# b 2 4 6因子 (factor)
# ---- 分类数据 / 有序 vs 无序
# ---- 整数向量 + 标签(label) (优于整数向量)
# Male / Female vs 1 / 2
# 常用于 lm(), glm()# factor(x = character(), levels, labels = levels, exclude = NA, ordered = is.ordered(x), nmax = NA)
x <- factor(c("male","female","female","male","male"))console :
# > x
# [1] male female female male male
# Levels: female malex2 <- factor(c("male","female","female","male","male"), levels = c("male","female"))console :
# > x2
# [1] male female female male male
# Levels: male female注意: 以上 x 和 x2 的levels 先后顺序是不一样的
查看当前因子
table(x)console :
# > table(x)
# x
# female male
# 2 3 去掉因子属性
unclass(x)console :
# > unclass(x)
# [1] 2 1 1 2 2
# attr(,"levels")
# [1] "female" "male" class(unclass(x))console :
# > class(unclass(x))
# [1] "integer"缺失值 (missing value)
# --- NA/NaN:NaN 属于NA, NA 不属于 NaN (NaN表示数字的缺失值,NA范围更广)
# --- NA 是有类型属性的: integer NA, character NA
# --- is.na() is.nan() 判断是否有缺失值 x <- c(1,NA,2,NA,3)
is.na(x)
is.nan(x)console :
# > is.na(x)
# [1] FALSE TRUE FALSE TRUE FALSE
# > is.nan(x)
# [1] FALSE FALSE FALSE FALSE FALSE数据框 (data frame)
# --- 存储表格数据 (tabular data)
# --- 视为各元素长度相同的列表
# --- 1. 每个元素代表一列数据
# --- 2. 每个元素的长度代表行数
# --- 3. 元素类型可以不同# data.frame(..., row.names = NULL, check.rows = FALSE, check.names = TRUE, stringsAsFactors = default.stringsAsFactors()) df <- data.frame(id = c(1,2,3,4), name = c("a","b","c","d"), gender = c(TRUE,TRUE,FALSE,TRUE))console:
# > df
# id name gender
# 1 1 a TRUE
# 2 2 b TRUE
# 3 3 c FALSE
# 4 4 d TRUE nrow(df)
ncol(df)把数据框转换成矩阵
df1 <- data.frame(id = c(1,2,3,4), score = c(5,6,7,8))
data.matrix(df1)console:
# id score
# [1,] 1 5
# [2,] 2 6
# [3,] 3 7
# [4,] 4 8注意: 数据框和矩阵第一列标记是不一样的
日期和时间 (date, time)
# --- Date: 距离1970-01-01的天数 / date() /Sys.Date() / weekdays() / months() / quarters() x <- date()console:
# [1] "Thu Jul 13 14:09:07 2017" class(x) # [1] "character"
x1 <- Sys.Date() # [1] "2017-07-13"
class(x1) # [1] "Date"
# 存储为date
x2 <- as.Date("2017-07-13")
class(x2) # [1] "Date"
weekdays(x2) # [1] "星期四"
months(x2) # [1] "七月"
quarters(x2) # [1] "Q3" 季度
julian(x2) # 距离1970-01-01 过去了多少天
# [1] 17360
# attr(,"origin")
# [1] "1970-01-01"
x3 <- as.Date("2016-11-11")
x2 -x3
# Time difference of 244 days
as.numeric(x2-x3) # [1] 244
# 时间: POSIXct / POSIXlt
# --- 距离1970-01-01的秒数 / Sys.time()
# POSIXct: 整数,常用于存入数据库
# POSIXlt: 列表,还包含星期,年,月,日等信息
x <- Sys.time()
# [1] "2017-07-13 14:22:14 CST"
class(x) # [1] "POSIXct" "POSIXt"
# ct 和 lt 类型相互转换
p <- as.POSIXlt(x)
# [1] "2017-07-13 14:22:14 CST"
class(p) # [1] "POSIXlt" "POSIXt"
# 查看变量名称
names(unclass(p))
# [1] "sec" "min" "hour" "mday" "mon" "year" "wday" "yday" "isdst"
# [10] "zone" "gmtoff"
p$sec # [1] 14.00388
x1 <- "1991-05-15 03:45"
strptime(x1, "%Y-%m-%d %H:%M")
# [1] "1991-05-15 03:45:00 CDT"RStudio 运行
# 运行代码
# 选中一段代码,点 Run
以上是关于R 语言基础知识的主要内容,如果未能解决你的问题,请参考以下文章