单链表及单链表的三个初级算法思想
Posted Aline2021-yxz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了单链表及单链表的三个初级算法思想相关的知识,希望对你有一定的参考价值。
单链表的基础知识及三个初级算法思想
单链表介绍
链表就是将一组数据存放在一块连续或者不连续的堆空间上的数据结构,空间既然可以是不连续的,那么在一个堆空间内不止要存储数据本身,还需要存储指向下一个堆空间的指针,这样就可以将所有数据连接起来,像这样即存储数据又存储指针的存储结构称之为结点(Node)。
比较理想的物理存储:
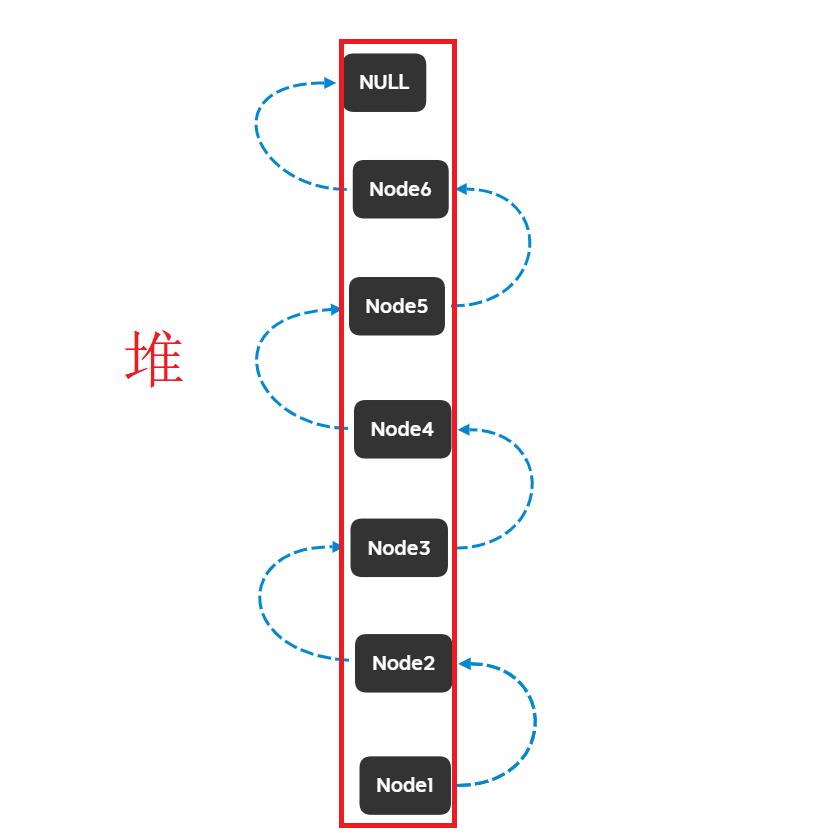
实际的物理存储:
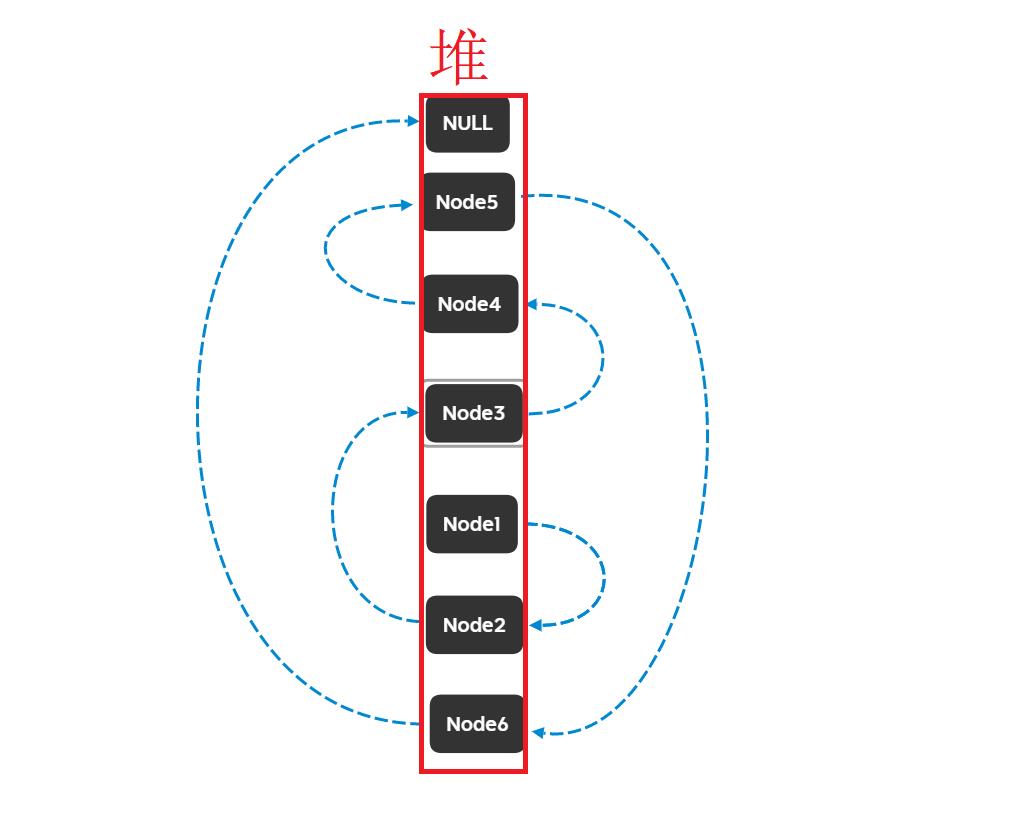
🎇注意🎇:因为每个结点的指针都是指向下一个结点的,那么对于第一个结点,它的前面是没有结点的,所以需要定义一个head指针指向第一个结点,对于最后一个结点,它的后面没有结点了,那么就让它的指针指向NULL;
看了那么多,还不知道结点到底是是什么样的的呢!废话不多说,上代码🤣
#define TYPE int//使用宏定义存储的数据类型,方便修改存储的数据类型
typedef struct Node
TYPE data;
struct Node* next;//指向下一个结点的指针
Node;
好了,知道结点是什么样了吧!什么?你问我怎么创建一个链表?💢
#define TYPE int
typedef struct Node
TYPE data;
struct Node* next;
Node;
int main()
Node* head = NULL;//创建head指针,指向第一个结点
head = (Node*)malloc(sizeof(Node));//在堆上创建第一个结点
head->next = (Node*)malloc(sizeof(Node));//创建第二个结点
head->next->next = NULL;//让最后一个结点指向NULL
//堆上的内存不要忘了释放哦
free(head);
head = NULL;
free(head->next);
head->next = NULL;
return 0;
上面的代码就创建了一个只含有两个结点的链表,data里面放的都是随机值,我们在想像的时候可以直接这样思考,不用堆上那么复杂。
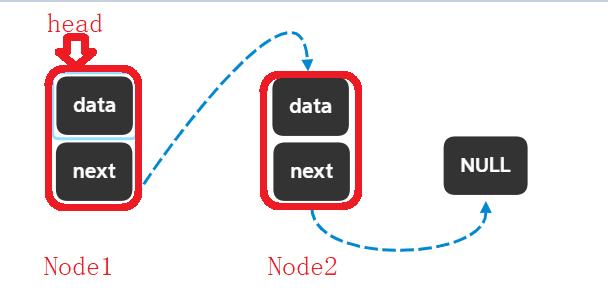
单链表的增删查改
单链表在实际中的应用并不像我上面创建时候一样简单。
初始化链表
void SLNodeInit(Node** pphead)//初始化链表
assert(pphead);//检查参数是否正确
*pphead = (Node*)malloc(sizeof(Node));//创建第一个结点
(*pphead)->data = 0;
(*pphead)->next = NULL;
🎇注意🎇:在初始化传参的时候一定注意要传入head指针的地址,不然形参无法改变实参。
销毁链表
void DesSLNode(Node** pphead)//销毁链表
while (*pphead != NULL)//遍历所有节点释放空间
Node* tmp = (*pphead)->next;//保存下一个结点,防止free当前结点
//后找不到
free(*pphead);
*pphead = NULL;
*pphead = tmp;
很多初学链表的同学在销毁链表的时候可能会这样写:
void DesSLNode(Node** pphead)//销毁链表
while (*pphead != NULL)//遍历所有节点释放空间
free(*pphead);
*pphead = NULL;
*pphead=(*pphead)->next;
在free一个结点的时候没有保存下一个结点,这样会怎样?
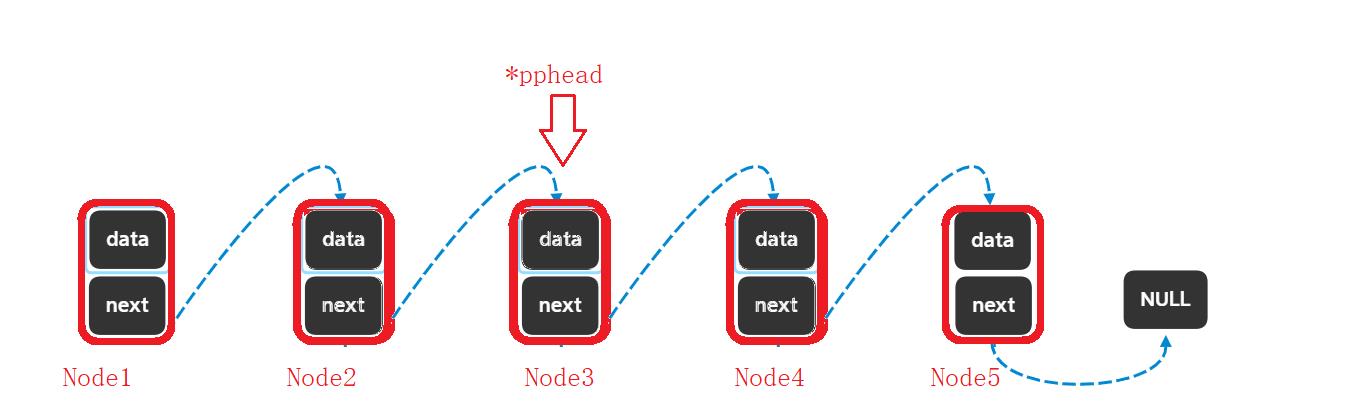
*pphead现在指向Node3,不保存Node4,删除Node3将变成这样:
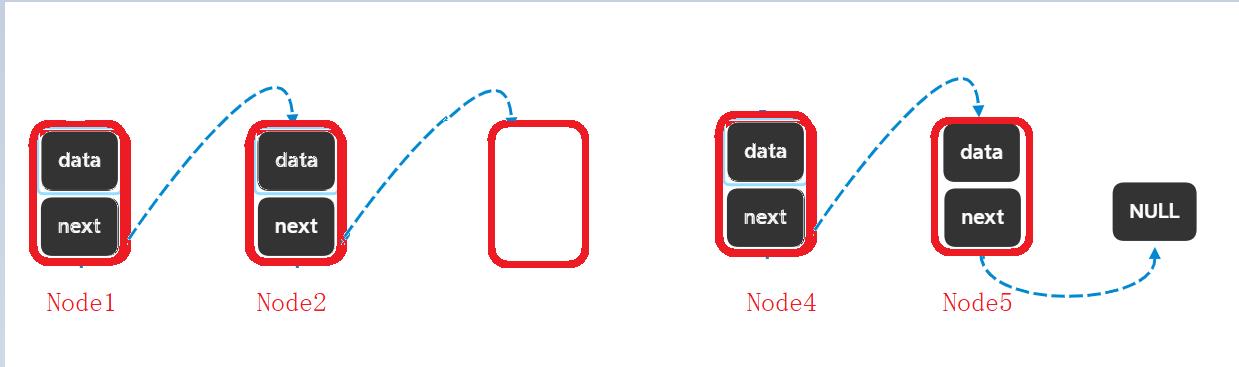
pphead指向NULL,那么pphead=pphead->next就不能让pphead指向下一个结点,链表就在这个地方断了,后面的空间再也找不到了,造成内存泄漏
查找指定结点
SLNode* SlNodeFind(Node*phead, TYPE x)//查找
assert(phead);
while (phead != NULL)//遍历链表
if (phead->data == x)
return phead;
phead = phead->next;
return NULL;//找不到,返回NULL
因为查找不会改变head指针,所以传head指针即可。
在链表头部增加新结点
SLNode* BuyNewNode(TYPE x)//创建新结点并将数据插入新结点
Node* newnode=(Node*)malloc(sizeof(Node));
if (newnode == NULL)//判断malloc是否成功
perror("BuyNewNode:malloc:");
newnode->data = x;//将新结点的data改为x
return newnode;
void SLNodePushFront(Node** pphead, TYPE x)//头插
assert(pphead);
Node* newnode = BuyNewNode(x);
newnode->next = *pphead;
*pphead = newnode;
在链表尾部增加新结点
SLNode* BuyNewNode(TYPE x)//创建新结点并将数据插入新结点
Node* newnode=(Node*)malloc(sizeof(Node));
if (newnode == NULL)//判断malloc是否成功
perror("BuyNewNode:malloc:");
newnode->data = x;//将新结点的data改为x
return newnode;
void SLNodePushBack(Node** pphead, TYPE x)//尾插
assert(pphead);//判断传参是否有误
if (*pphead == NULL)//空链表特殊情况,相当于头插
SLNodePushFront(*pphead, x);
else
Node* cur = *pphead;//创建指针遍历链表
while (cur->next != NULL)//寻找最后一个结点
cur = cur->next;
cur->next = BuyNewNode(x);//添加新结点
cur->next->next = NULL;
🎇注意🎇:在遍历链表的时候一定要创建新指针,因为单链表只能往一边走,回不去,如果遍历的时候使用head指针,那么等你遍历完后就再也无法对这片空间进行操作,造成内存泄漏
在链表中间某节点的后面增加结点
//SLNode* SLNodeInsert(Node*phead, Node* pos, TYPE x)//在指定位置后面插入节点
//
// assert(SlNodeFind(phead, pos->data));//使用查找函数判断所给节点是否存在
//
// Node* insertnode = BuyNewNode(x);//创建新结点
// insertnode->next = pos->next;//让新结点指向指定结点的下一个
// pos->next = insertnode;//让指定结点指向新结点
//
删除链表的最后一个结点
void SLNodePopback(Node** pphead)//尾删
assert(pphead);
assert(*pphead);//没有节点不能删除直接报错
Node* cur = *pphead;//创建新指针遍历链表
if (cur->next == NULL)//只有一个结点的特殊处理
free(cur);
cur = NULL;
*pphead = NULL;
else//多个结点
while (cur->next->next != NULL)//找到尾结点的前一个结点
cur = cur->next;
free(cur->next);
cur->next = NULL;//让新的尾结点(原尾结点的前一个结点)指向NULL
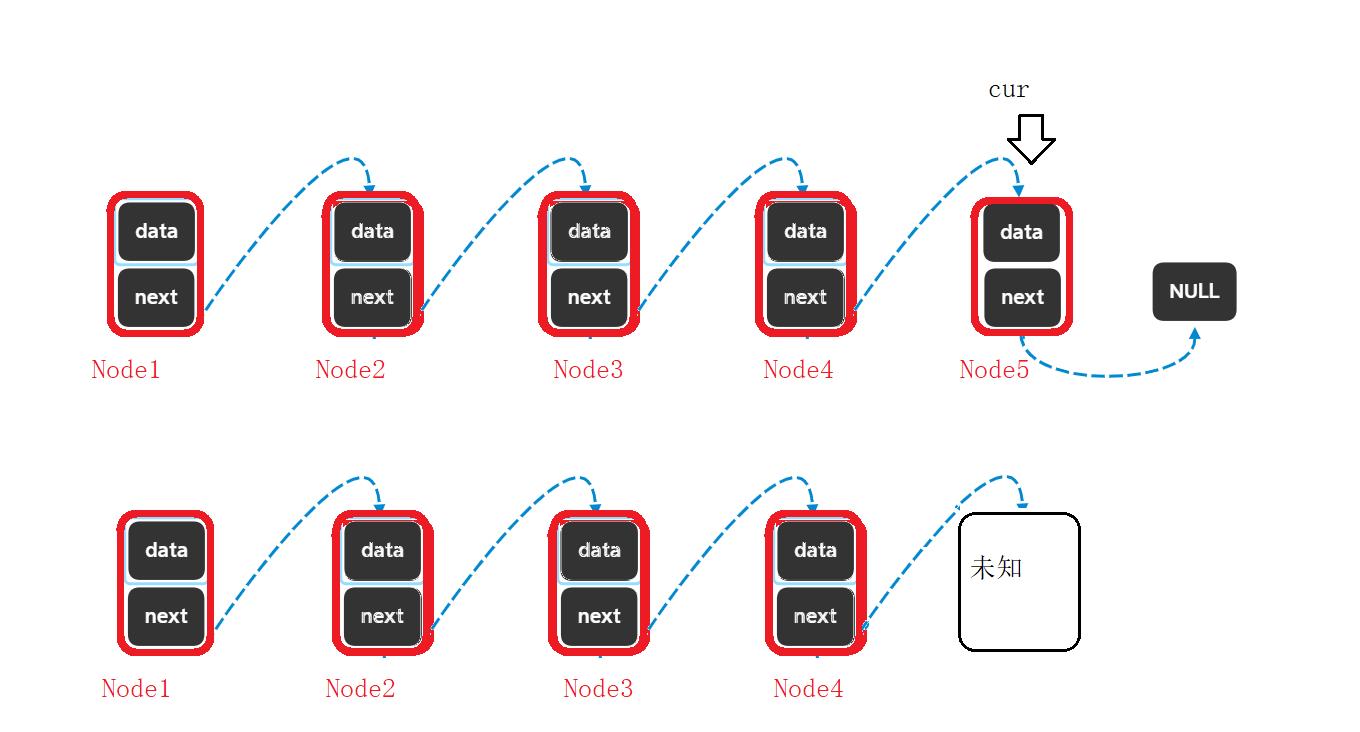
🎇注意🎇:在删除尾结点的时候我们应该找到尾结点的前一个结点,它将成为新的尾结点,这样才能让尾结点指向空,如果找的不是它而是尾结点,那么删除原尾结点后无法让新尾结点指向NULL;
错误:
正确:
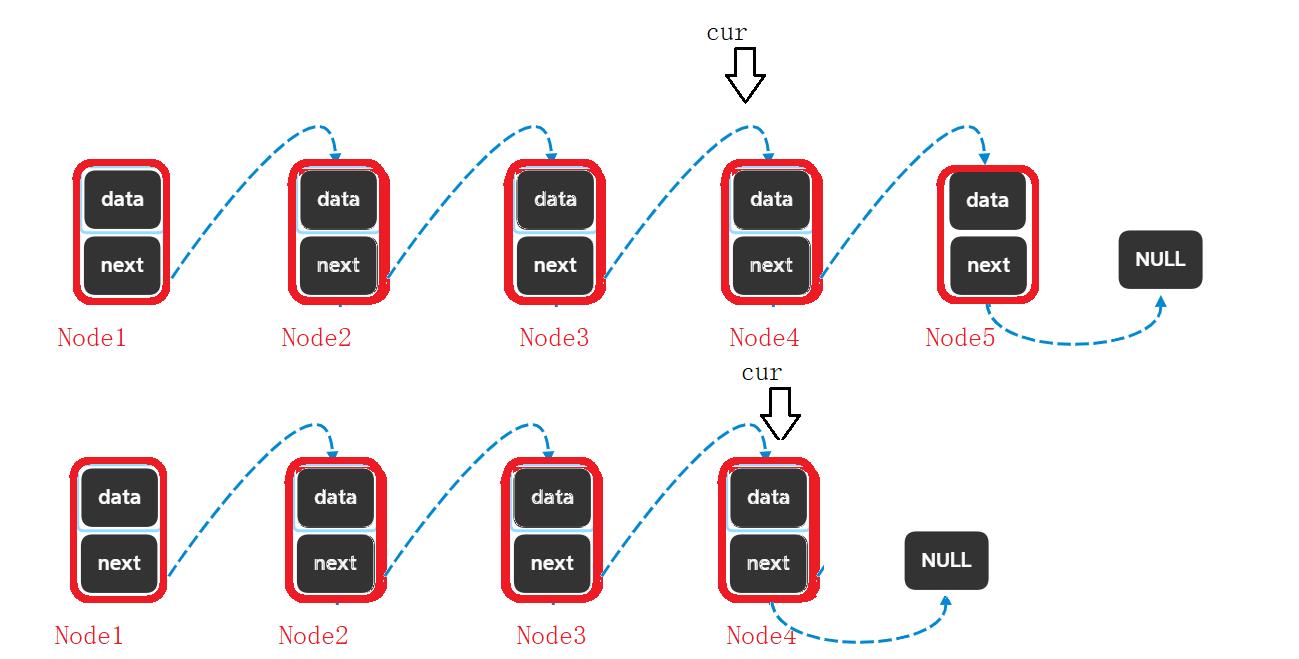
删除头结点
void SLNodePopFront(Node** pphead)//头删
assert(pphead);
assert(*pphead);
Node* newhead = (*pphead)->next;
free(*pphead);
*pphead = newhead;
OJ题算法思想
1:删除数据等于val的结点 leetcode链接
算法思想1:遍历链表,将数值等于val的结点删除,就是前面所写的删除操作
算法思想2:创建新链表,遍历链表将数值不等于val的结点放入,等于的结点删除。
两种算法的思想其实差不多,但是第二种算法考虑的情况比较少(比如第一个结点时val、多个结点都是val),所以实现第二种算法。
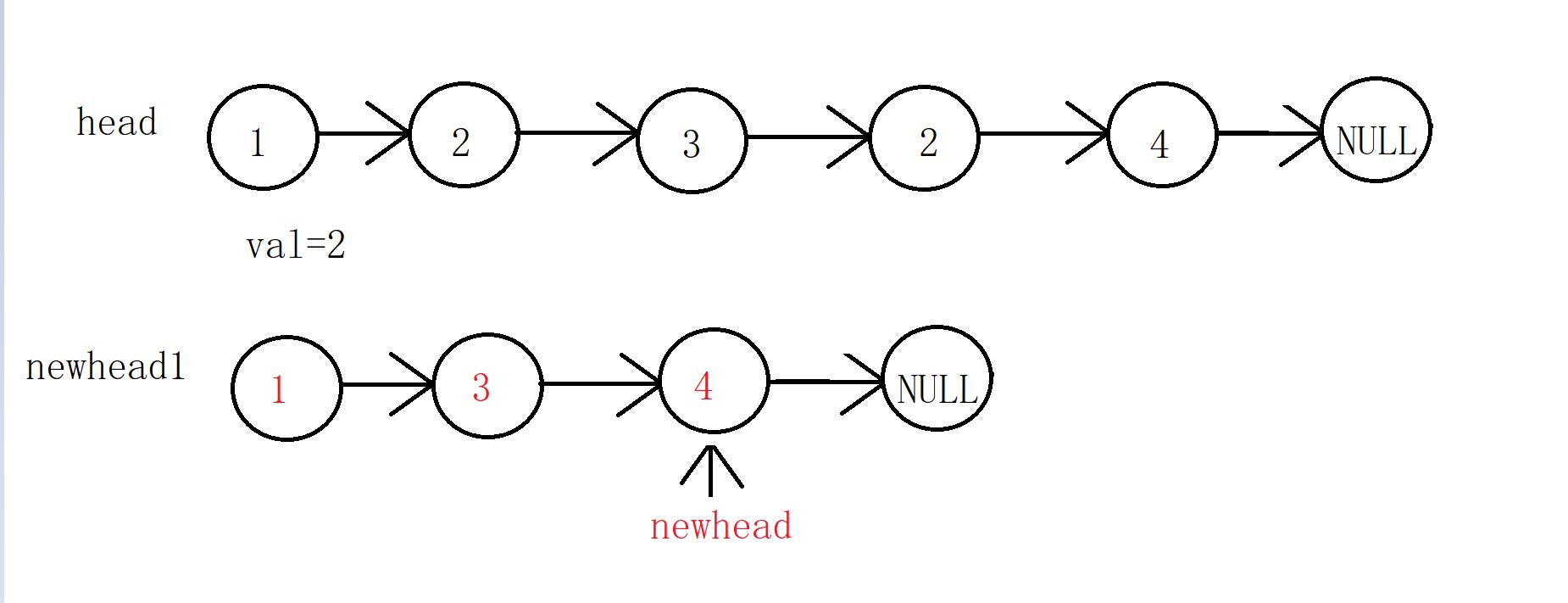
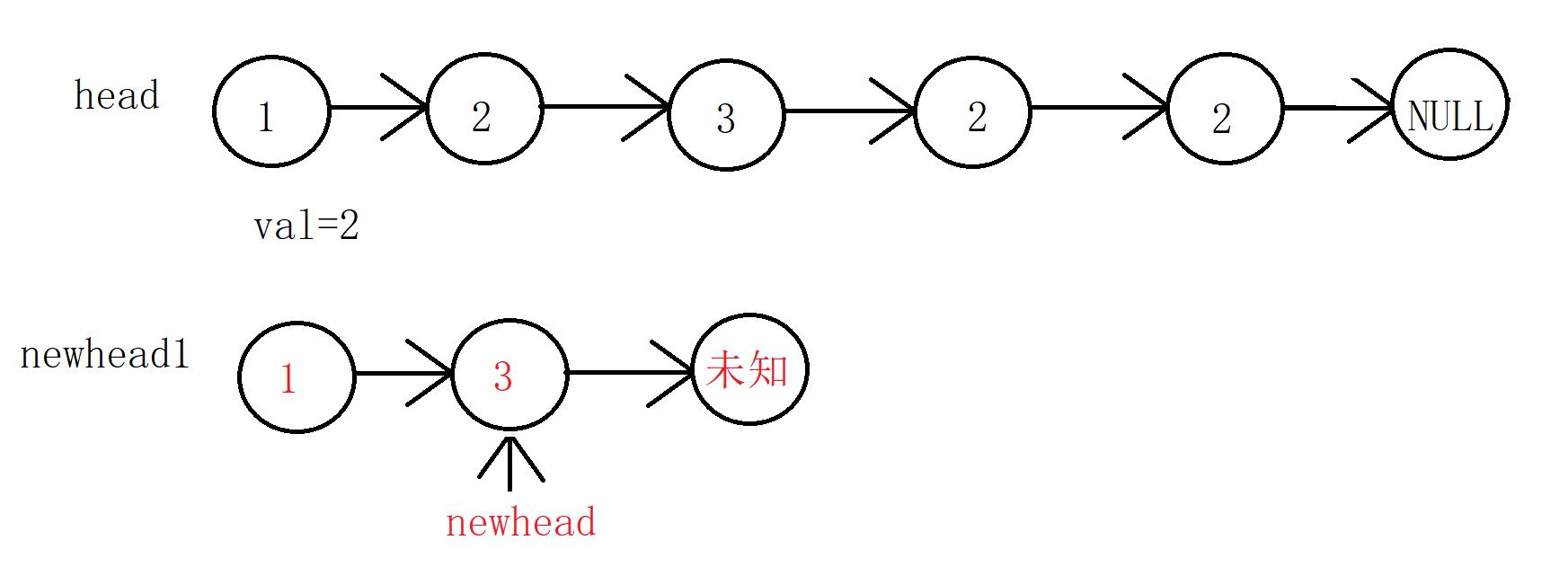
对比上面的两组数据,你发现上面有什么不同?
如果我们新链表的最后一个结点是原链表的最后一个结点,那么我们不需要设置新链表最后一个结点的指向,但是如果不是,我们需要让最后一个结点指向NULL,那么干脆就将最后一个结点指向NULL,这个细节可能很多人第一时间思考不到。
struct ListNode* removeElements(struct ListNode* head, int val)
struct ListNode* cur=head;
struct ListNode*newhead=NULL;
struct ListNode*newhead1=NULL;
if(head==NULL)//空链表不用删,直接返回NULL
return NULL;
while(cur!=NULL)
struct ListNode* tmp2=cur->next;
if(cur->val!=val)
if(newhead==NULL)//插入第一个数据的时候不同于其他数据插入,
需要将新链表的头指向第一个数据
newhead=cur;
newhead1=cur;
else
newhead->next=cur;
newhead=cur;
else
free(cur);
cur=tmp2;//迭代
if(newhead)//考虑最后一个结点是否指向NULL
newhead->next=NULL;
return newhead1;
2:反转链表 leetcode链接
算法思想1:将两个结点之间的指向反转。
算法思想2:头插法。
算法1是比较好想到的,实现起来只要注意保存下一个结点就行了。
算法2是不容易想到的,将原结点头插为一个新链表,这样就反转过来了✔
算法1实现:
struct ListNode* reverseList(struct ListNode* head)
struct ListNode* n1=NULL;//指向前一个结点的指针
struct ListNode* n2=head;//指向后一个结点的指针
struct ListNode*n3=NULL;//用来保存结点的指针
while(n2!=NULL)
n3=n2->next;//先保存
n2->next=n1;//改变指向
n1=n2;
n2=n3;//迭代
return n1;
算法2实现:
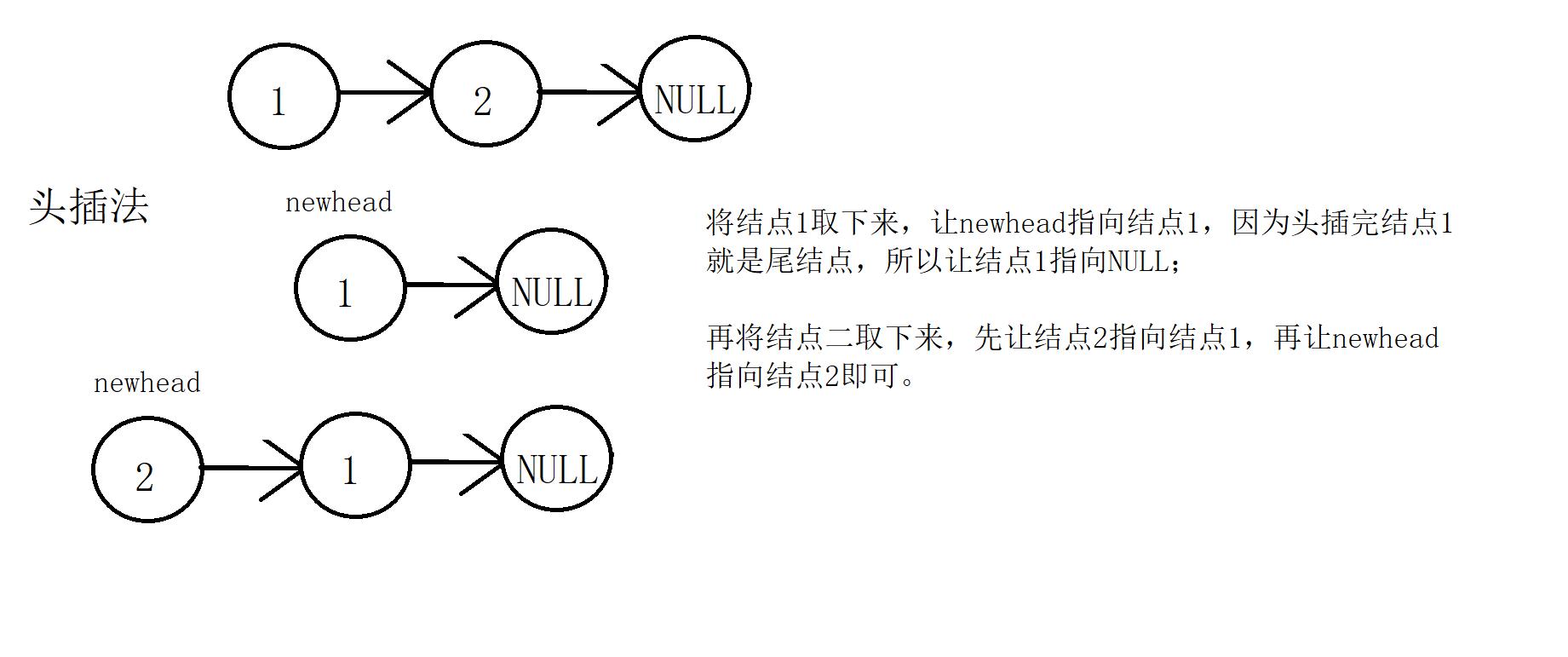
struct ListNode* reverseList(struct ListNode* head)
struct ListNode* newhead=NULL;
struct ListNode* tail=NULL;
struct ListNode* cur=head;
while(cur!=NULL)
struct ListNode*tmp=cur->next;//保存被插结点的下一个结点
if(tail==NULL)//新链表为空特殊情况
newhead=tail=cur;
tail->next=NULL;
else
newhead=cur;
cur->next=tail;
tail=cur;
cur=tmp;
return newhead;
3:寻找中间结点 leetcode链接
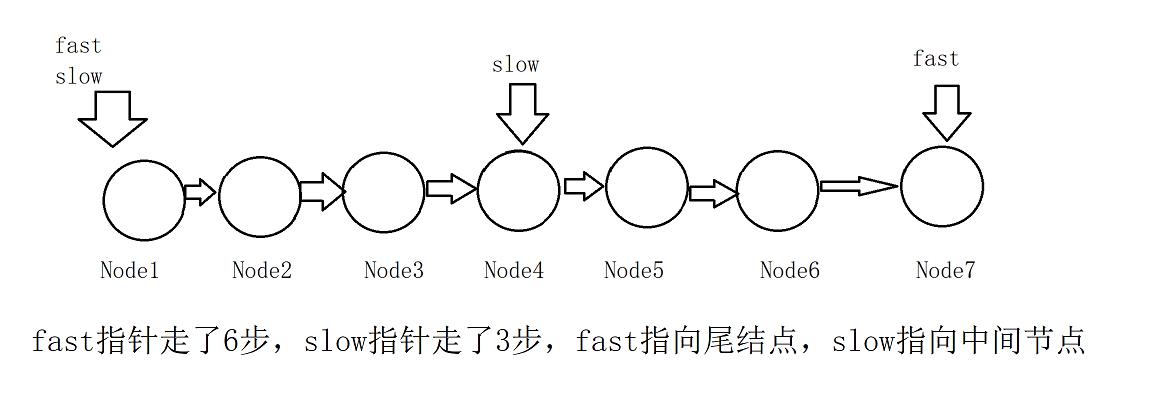
算法思想:快慢指针,快指针一次走两步,慢指针一次走一步,当快指针结束时慢指针走了它的一半。
结点个数为奇数时:
结点个数为偶数时:
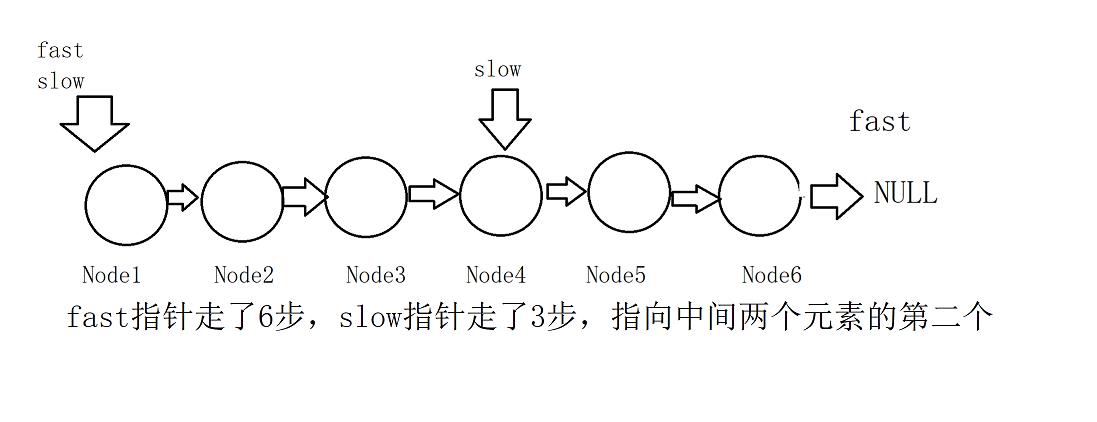
可以看到fast指针结束的标志时指向最后一个结点或者NULL。
struct ListNode* middleNode(struct ListNode* head)
//快慢指针
struct ListNode*fast=head;
struct ListNode*slow=head;
while(fast!=NULL&&fast->next!=NULL)//结束标志
fast=fast->next->next;
slow=slow->next;
return slow;
创作不易,如果您觉得这篇文章对您有用的话就不要吝啬手中的三连😊,如果您有任何的问题可以在评论区留言讨论哦🔰
以上是关于单链表及单链表的三个初级算法思想的主要内容,如果未能解决你的问题,请参考以下文章