HIVE3 深度剖析 (下篇)
Posted 明哥的IT随笔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HIVE3 深度剖析 (下篇)相关的知识,希望对你有一定的参考价值。
HIVE3 深度剖析 (下篇)
大家好,我是明哥!
HIVE3.x 系列相对于HIVE2.x系列,差异还是很大的。为方便大家了解这些差异点以更有效地使用HIVE,接下来我会通过几篇文章,重点剖析下这些差异点。
整个系列分为上下两篇文章,涵盖以下章节:
- 从 HIVE 架构的演进看 HIVE 的发展趋势
- 盘点下 HIVE3.X 和 HIVE2.X 的那些重大差异点
- HIVE3.X 的 ORC 事务表详解
- HIVE3.X 的 LEGACY 传统模式详解
- 周边生态如 SPARK/DATAX 如何对接HIVE 3x
- 大数据应用对接 HIVE3.x 的几点建议
本片文章是下篇,包含上述后三个章节,希望大家喜欢。
1. HIVE3.X 的 LEGACY 传统模式详解
-
如上篇所述,Hive 的 ORC 事务内表,通过 ACID 事务特性,提供诸多优势,包括对多个作业并发读写同一个表或同一个分区的支持,包括记录级别的增删改和数据修复功能,包括更好的批量性能、安全保障和用户体验等等;
-
但是直接切换使用 HIVE ORC 事务表,涉及到用户的学习成本,也涉及到遗留系统代码的迁移改造,所以可能在一段时间内,用户仍期望 HIVE3.X 能尽量保留原有 Hive2.X 的使用模式 (即默认方式创建的表仍然是非事务表);
-
Cloudera 推出 了 Hive 的 LEGACY 传统 模式,并回馈给了 APACHE HIVE 开源社区,以缓解 HIVE/CDP 在升级/迁移期间的脚本兼容性问题,并给用户更多的适应时间( 从 CDP7.1.4 开始支持传统模式);
-
HIVE3.X 的 legacy 传统模式,可以通过参数 hive.create.as.external.legacy 来开启,需要说明的是,该参数在推出之初,社区就明确指出,“This config is temporary and will be deprecated later”,所以长远来看,还是推荐大家学习 HIVE3.X 的这些新特性,并逐渐摒弃对传统模式的以来;
-
需要注意,并不是所有版本的 HIVE 3.X 都支持 LEGACY 模式,大家可以通过 BEELINE 登陆 HS2 后执行命令 SET hive.create.as.external.legacy 查看是否支持该参数,如果显示 xx is undefined ,则表示不支持 LEGACY 模
式;

-
大家知道,HIVE2.X中 DROP table 时,对于内表,会删除 HMS 中的元数据和底层存储系统 HDFS 中的数据,而对于外表,则只会删除 HMS 中的元数据不会删除底层存储系统 HDFS 中的数据;
-
在 HIVE3.X 中,根据 DROP TABLE 时是否删除底层存储系统 HDFS 中的数据,external 外表又被分为两种类型:external non purgeable table 和 external purge table,前者在DROP TABLE 时跟 HIVE2.X 的外表行为一致,不会删除底层HDFS中的数据;而后者 DROP TABLE 时跟 HIVE2.X 的内表行为一致,也会删除底层 HDFS 中的数据;
-
HIVE3.X 中创建外表时外表的具体类型,可以通过 session 级别参数 hive.external.table.purge.default 控制,也可以在建表时在 table 级别进行覆盖:TBLPROPERTIES (‘EXTERNAL’=‘TRUE’,‘external.table.purge’=’TRUE’/‘FALSE’);
-
Hive3.x 的 ORC 事务内表,也分为两种类型,即 full acid 事务内表,和 Insert only 事务内表,可以通过 session 级别参数 hive.create.as.acid hive.create.as.insert.only 控制,也可以在创建表时在 table 级别覆盖:TBLPROPERTIES (‘transactional’=‘true’,'transactional_properties=‘insert_only ’/‘default’);
-
Hive3.x 中,内表和外表都有默认的存储路,分别由参数 hive.metastore.warehouse.dir 和 hive.metastore.warehouse.external.dir 控制,在 cdp 中其默认值分别为 /tablespace/managed/hive 和 /tablespace/external/hive;每个具体的内表和外表的存储路径,分别可以在 DATABASE 级别和 TABLE 级别通过 location 参数来指定;
-
Hive3.x CREATE TABLE 默认创建的是 Managed ORC ACID table, 而 Hive1 和 hive2 默认创建的是 Managed (Non ACID ) txtfile table;
-
HIVE3.X CREATE TABLE 的实际效果,取决于以下参数:hive.create.as.external.legacy/hive.create.as.acid/hive.create.as.insert.only/hive.txn.manager hive.ctas.external.tables/hive.external.table.purge.default/hive.default.fileformat.managed/hive.metastore.warehouse.external.dir;
-
经验证,参数hive.create.as.external.legacy/hive.create.as.acid hive.create.as.insert.only/hive.txn.manager hive.ctas.external.tables/hive.external.table.purge.default/hive.default.fileformat.managed hive.metastore.warehouse.external.dir 都可以在客户端动态修改,但参数 hive.metastore.warehouse.external.dir 在客户端的动态修改并不生效,只能在服务端进行修改;
-
LEGACY 传统模式下,Create table 建表语句,不指定存储格式和 TBLPROPERTIES 时,默认创建的是 ORC 格式的 Non ACID 外表,且是可 purge 的,即TBLPROPERTIES(‘EXTERNAL’=‘TRUE’,‘external.table.purge’=’TRUE’);
-
LEGACY 传统模式下,创建 ORC 事务表,可以使用 HIVE3.X 新增的语法 CREATE MANAGED TABLE xyz(col1 type,…) type,…),来显示创建 managed table;
-
启用 Hive3 LEGACY 传统模式的方法有以下三种:
- 系统级别静态设置: 配置 hive-site.xml中参数 hive.create.as.external.legacy =true;
- 会话级别静态设置: beeline -u jdbc:hive2://hostname:10000/default;hiveCreateAsExternalLegacy=true -n username -p password (即 url 中指定参数hiveCreateAsExternalLegacy=true)
- 会话级别动态设置: 在 beeline/hue 登录 hs2 并成功获取 session 后,执行以下命令: set hive.create.as.external.legacy=true;
-
可以通过以下命令,对已经创建完毕的表更改其 TBLPROPERTIES 属性:
- ALTER TABLE my_table UNSET TBLPROPERTIES (‘transactional’);
- ALTER TABLE … SET TBLPROPERTIES(‘EXTERNAL’=’TRUE’);
- ALTER TABLE … SET TBLPROPERTIES(‘transactional’=‘true’,‘transactional_properties‘=‘insert_only’);
- ALTER TABLE … SET TBLPROPERTIES(‘transactional’=‘true’,transactional_properties =‘default’);

2. 周边生态如 SPARK/DATAX 如何对接HIVE 3.x
- 不同计算引擎如 HIVE-LLAP,Impala, hive-on-tez,Spark 对不同格式HIVE表的支持如下图:

- HIVE,SAPRK-SQL,SPARK-DATAFRAME 对 HMS 的支持特性如下图:



- SPARK SQL 和 datax 都不能直接读取 HIVE ACID 事务表(所谓直接读取,其底层是通过 HMS 获取到表底层的元数据后,绕过 HS2 直接读取HDFS上的数据文件),会报错:


- Spark 和 datax 也都不能直接简单粗暴地将 orc 数据文件写到 orc 事务表对应的 hdfs 目录下 (此时底层绕过了 HS2 直接写文件到 HDFS上),后续 HIVE SQL 查询时会报错:“bucketId out of range: 1”;
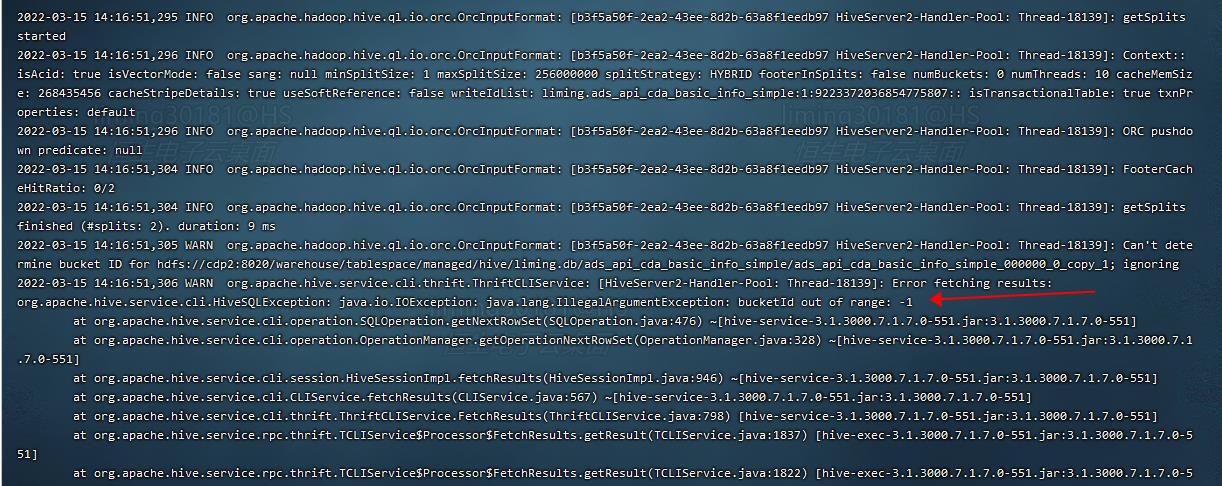
- SPARK SQL 和 DATAX 直接读写 HIVE ACID事务表时会报错,底层原因是,HIVE 对 orc 事务表底层文件的目录结构和文件命名,有一套自己的规范(正如 mysql/ORACLE 对表底层文件的目录结构和文件命名有自己的一套规范,你不能绕过 MYSQL/ORACLE服务,直接读写 NYSQL/ORACLE表在本地文件系统中的文件一样);
- HIVE 对 orc 事务表底层文件的目录结构和文件命名的规范是:
- 文件都是 orc 格式;
- 表目录下包括一个 base 子目录和一个或多个 delta子目录;
- 表底层文件名类似 base0000001_v0000001/bucket_00000, delta_0000001_0000001_0000/bucket_0000 和 delete_delta_0000001_0000001_0000/bucket_00000;
- Spark 读写 HIVE ACID 事务表,推荐通过原 HortonWorks 开发并回馈给开源社区的插件 HWD: Hive WarehOUSE Connector;
- 虽然 spark 通过 hwc 可以读写 Hive acid 事务表,但使用 spark hwd 基于 hive acid 事务表进行常规 etl/elt 操作,并不是最佳实践;
- 如果仍需要使用 spark 进行 etl/elt操作的话,建议使用 hive 外表,外表都是不 acid事务表),此时 spark 不需要 hwc 可以直接对外表进行读写操作;

3. 大数据应用对接 HIVE3.x 的几点建议
Hive 已经从早期一个简单的存储引擎之上的 SQL 解析层(单纯的 JAR 而没有服务),逐渐迭代优化,越来越像传统的关系型数据库了,对底层文件的目录结构文件名称存储格式等都由自己来管理,所以外部引擎的对接,尤其是对接ACID内部表,要尤其注意:
- spark 读写 hive 的 orc 事务表,只能通过 hwc 的方式来;
- 通过 spark 使用 hwc 读写 hive orc 事务表做各种 ETL/ELT 处理, 是错误的实践! Performing etl/elt in spark using hwc to extract large datasets from hive and then writing those back to hive via hwc is an ANTI-PATTEN!
- 如果使用 spark 做 etl/elt 引擎构建数仓,应该基于 external 外部表来构建各层,建议在 hive 中通过 hive ddl 建外表,根据情况指定参数 hive.external.table.purge.default 和 hive.metastore.warehouse.external.dir ,或在表级别覆盖参数 TBLPROPERTIES(‘external.table.purge’=’TRUE‘):if spark is being used for etl/elt, consider staying with the external tables;
- 如果使用 hive on tez 做 etl/elt 引擎构建数仓,建议使用 HIVE ACID 内部事务表,当然 ods/ads 层因为需要对接导入导出工具比如 spark/datax,仍只能使用 orc 非事务表(因为这些生态工具都不能直接访问 hive acid 事务内表);
- spark 和 hive 互相访问对方的数据,推荐走 external 外部表的路线: the interaction between hive and spark,should be via external table;
- 如果需要构建复杂的数据链路,使用的引擎包括 spark 和 hive 的话,建议 Integration layer 用 spark, serving layer 用 hive: use spark to ingest and curates the data, and implement a sweep location to build managed tables in hive for upstream analytics/reporting (present them using hive)
- 内部表与外部表或外部文件进行交互,可以使用命令: Insert into/overwrite … select * from xxx; Load data inpath xxx into table xxx partition xxx;
在数仓分层建模上,需要注意以下几点:
- 数据落地层 ODS 和数据导出层 ADS 可以使用 ORC 非事务表,以当前熟悉的方式使用 SPARK/DATAX 等生态工具进行数据的导入和导出处理:
- 数据落地层 ODS 如需要使用 ORC 事务表,需要使用 SPARK/DATAX 等生态工具导入数据到 staging area, 然后使用 hive 的 load data inpath xxx into table xxx partition xxx 或 Insert into/overwrite … select * from xxx,略显繁琐;
- 数据导出层 ADS 如需要使用 ORC 事务表,需要 SPARK/DATAX 等生态工具的适配改造,比如 spark 可以使用 hwc,而 datax 目前还不支持 hive acid事务表;
- 数仓 dwd/dws 层的表,可以使用 orc 事务表:
- 此时 orc 事务表提供了对多个作业并发读写的支持,不需要像原来一样通过调度工具规避掉对同一张表或表分区的并发写,也不会在数据写入期间起 dirty read 脏读,同时基于底层 acid事务表的 compact 合并机制也可以避免/减轻 HDFS 小文件问题;
- 此时 orc 事务表提供了记录级别的增删改功能,所以可以合理使用语句 INSERT…VALUES, UPDATE, DELETE, merge into,对某个表或表分区的满足条件的部分记录进行更新,而不是像原来,只能对整个表或整个表分区进行全量覆盖写,那样太笨重读写和计算的开销也太大(具体的语句如:delete from tableA where xxx, update tableA set columnA=valueA where xxx, 或 Merge into xx using xx on xx when matched xx when not matched xx)
- 此时 orc 事务表提供了记录级别的增删改功能,所以可以合理使用 INSERT…VALUES, UPDATE, DELETE, merge into 等来更新维表,支持数仓的 SCD;
- 此时 orc 事务表提供了记录级别的增删改功能,所以可以合理使用 INSERT…VALUES, UPDATE, DELETE, merge into 等进行记录级别的按照条件的数据修复/删除;(这类需求一般是 add hoc 的);
- 由于ORC事务表提供了记录级别的增删改功能,所以数仓模型设计也需要再思考,尤其是分区表的分区方式,在有些情况下,可能不用再简单粗暴地按天分区并保存每个日分区的全量数据了;
最后,在工程代码实践上:
- 建议工程代码中将 DDL 与 DML 模块化分离开来,便于安装部署和后续升级调整!(类似微服务中使用 RDBMS 时DDL 与 DML 是分开放发的,DDL 用于一次性的安装部署,也用于日常运维过程中调整索引和分区,而 DML 是融合在业务代码如JAVA中的)
- 对于乙方产品化发包的情况,由于目前 CDP 环境较少,而相关 HIVE 参数众多, 可能 DDL 做不到充分的兼容性测试,期望的产品化发包同一套代码应对各平台各版本的目的,可能不太容易达到,所以仍是建议分离 ddl 与 dml ,对接客户现场版本时根据需要调整ddl ,同时积累下相关经验,看后续能否做到一套 ddl 代码对接不同平台不同版本。
!关注不迷路~ 各种福利、资源定期分享!欢迎小伙伴们扫码添加明哥微信,后台加群交流学习。

以上是关于HIVE3 深度剖析 (下篇)的主要内容,如果未能解决你的问题,请参考以下文章