Keras深度学习实战(35)——构建机器翻译模型
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras深度学习实战(35)——构建机器翻译模型相关的知识,希望对你有一定的参考价值。
Keras深度学习实战(35)——构建机器翻译模型
0. 前言
我们已经学习了多种将输入和输出进行一对一映射的模型架构,在本节中,我们将研究构建多对多模型体系结构,这种模型架构可以将所有输入数据映射到编码向量中,然后将其解码为输出向量。本节中,我们将构建神经网络模型用于将英语输入文本翻译成法语文本输出。
1. 模型与数据集分析
1.1 模型分析
在实现机器翻译模型前,我们首先定义用于执行机器翻译的体系结构:
- 获取数据集,其中包括输入的英语句子和相应的法语翻译
- 标记并提取英语和法语文本中常见的单词:
- 为了识别频繁出现的单词,计算每个单词的出现频率
- 占所有词总累计频率前80%的词被认为是常用词
- 对于不属于常用词的单词,使用符号 (
unk) 替换它们
- 为每个单词分配一个
ID - 构建一个基于长短时记忆网络 (
Long Short Term Memory,LSTM) 的编码器LSTM获取输入文本的向量 - 编码向量通过全连接层,以便在每个时间戳提取解码文本的概率
- 拟合模型以最小化输出损失
1.2 数据集分析
为了构建机器翻译模型,我们所使用的数据集中包含英语及其对应的法语数据,相关数据集可以在 gitcode 链接中下载,其中包含了大约 140000 个英语与法语互译的句子。
2. 实现机器翻译模型
接下来,我们将实现上一小节中所定义的策略以翻译输入文本。
2.1 预处理数据
要将输入和输出数据传递到所构建模型,我们首先对数据集进行预处理。
(1) 导入相关的库,并加载数据集:
import pandas as pd
import numpy as np
import string
import matplotlib.pyplot as plt
lines= pd.read_table('english to french.txt', names=['eng', 'fr'])
# 数据集中约有 140000 个句子,为了简单起见,在本模型中仅考虑前 100000 个句子:
lines = lines[0:100000]
(2) 将输入和输出文本转换为小写并删除标点符号:
lines.eng=lines.eng.apply(lambda x: x.lower())
lines.fr=lines.fr.apply(lambda x: x.lower())
exclude = set(string.punctuation)
lines.eng=lines.eng.apply(lambda x: ''.join(ch for ch in x if ch not in exclude))
lines.fr=lines.fr.apply(lambda x: ''.join(ch for ch in x if ch not in exclude))
# 查看数据样本示例
print(lines.head())
打印出的数据样本如下所示:
eng fr
0 go va
1 run cours
2 run courez
3 wow ça alors
4 fire au feu
(3) 将开始和结束标记添加到输出语句,即法语语句。开始标记和结束标记在编码器-解码器体系结构中非常有用,具体原因将在后续模型构建时详细讲解:
lines.fr = lines.fr.apply(lambda x : 'start '+ x + ' end')
print(lines.head())
数据样本如下所示:
eng fr
0 go start va end
1 run start cours end
2 run start courez end
3 wow start ça alors end
4 fire start au feu end
(4) 接下来,确定常用词。如果单词属于累计构成英语单词总数的 80%,则我们将其定义为常用词:
from keras.preprocessing.text import Tokenizer
import json
def create_tokenizer(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
eng_tokenizer = create_tokenizer(lines.eng)
output_dict = json.loads(json.dumps(eng_tokenizer.word_counts))
df =pd.DataFrame([output_dict.keys(), output_dict.values()]).T
df.columns = ['word','count']
df = df.sort_values(by='count',ascending = False)
df['cum_count']=df['count'].cumsum()
df['cum_perc'] = df['cum_count']/df['cum_count'].max()
final_eng_words = df[df['cum_perc']<0.8]['word'].values
在以上代码中,我们提取输入中累计构成英语单词总数的 80% 的英语单词。接下来,我们使用同样的方法提取法语单词,这些单词总数累计占输出法语单词总数的 80%:
fr_tokenizer = create_tokenizer(lines.fr)
output_dict = json.loads(json.dumps(fr_tokenizer.word_counts))
df =pd.DataFrame([output_dict.keys(), output_dict.values()]).T
df.columns = ['word','count']
df = df.sort_values(by='count',ascending = False)
df['cum_count']=df['count'].cumsum()
df['cum_perc'] = df['cum_count']/df['cum_count'].max()
final_fr_words = df[df['cum_perc']<0.8]['word'].values
# 打印出不同常用词的数量
print(len(final_eng_words),len(final_fr_words))
# 398 415
(5) 过滤掉不常用的单词。如果单词不在常用词中,我们使用标记 unk 代替:
def filter_eng_words(x):
t = []
x = x.split()
for i in range(len(x)):
if x[i] in final_eng_words:
t.append(x[i])
else:
t.append('unk')
x3 = ''
for i in range(len(t)):
x3 = x3+t[i]+' '
return x3
filter_eng_words 函数以一个句子为输入,提取其中不同的单词,如果其不属于常用英语单词 final_eng_words,则将其替换为 unk。接下来,我们以类似的方式定义函数 filter_fr_words,其将法语句子作为输入,提取其中不同的单词,如果其不属于常用法语单词 final_fr_words,则将其替换为 unk:
def filter_fr_words(x):
t = []
x = x.split()
for i in range(len(x)):
if x[i] in final_fr_words:
t.append(x[i])
else:
t.append('unk')
x3 = ''
for i in range(len(t)):
x3 = x3+t[i]+' '
return x3
使用以上定义的函数,在一个包含常用单词和不常用单词的句子中,替换后的输出如下:
print(filter_eng_words('he is extremely good'))
# he is unk good
(6) 在了解了 filter_en_words 和 filter_fr_words 函数的用法后,我们将根据定义的函数处理所有英语和法语句子:
lines['fr']=lines['fr'].apply(filter_fr_words)
lines['eng']=lines['eng'].apply(filter_eng_words)
(7) 为英语(输入)和法语(输出)句子中的每个单词分配不同 ID。分别存储英语和法语句子数据中所有不重复单词的集合,并将它们转换为列表:
all_eng_words=set()
for eng in lines.eng:
for word in eng.split():
if word not in all_eng_words:
all_eng_words.add(word)
all_french_words=set()
for fr in lines.fr:
for word in fr.split():
if word not in all_french_words:
all_french_words.add(word)
input_words = sorted(list(all_eng_words))
target_words = sorted(list(all_french_words))
num_encoder_tokens = len(all_eng_words)
num_decoder_tokens = len(all_french_words)
创建输入词及其对应索引的字典:
input_token_index = dict([(word, i+1) for i, word in enumerate(input_words)])
target_token_index = dict([(word, i+1) for i, word in enumerate(target_words)])
计算输入和目标句子的最大长度,以便所有句子都可以填充为相同长度:
lenght_list=[]
for l in lines.fr:
lenght_list.append(len(l.split(' ')))
fr_max_length = np.max(lenght_list)
lenght_list=[]
for l in lines.eng:
lenght_list.append(len(l.split(' ')))
eng_max_length = np.max(lenght_list)
至此,我们已经完成了对数据集的预处理,接下来,我们使用多种模型架构处理数据集以比较不同模型性能。
2.2 传统多对多架构
在传统体系结构中,我们将每个输入单词编码为 128 维嵌入向量,从而得到形状为 (batch_size, 128, 18) 的输出向量,最后一个维度 18 是由于输入数据具有 18 个时间戳而输出数据集也具有 18 个时间戳。然后通过 LSTM 将每个输入时间戳连接到输出时间戳,最后使用 softmax 函数得到输出结果。
(1) 根据预处理得到的 decoder_input_data 和 decoder_target_data 创建输入和输出数据集,创建 decoder_input_data 存储目标句子单词相对应的单词 ID。decoder_target_data 是目标句子中起始标记单词后所有单词的独热编码:
encoder_input_data = np.zeros(
(len(lines.eng), fr_max_length),
dtype='float32')
decoder_input_data = np.zeros(
(len(lines.fr), fr_max_length),
dtype='float32')
decoder_target_data = np.zeros(
(len(lines.fr), fr_max_length, num_decoder_tokens+1),
dtype='float32')
在以上代码中,我们为 num_decodder_tokens 加 1,其中加 1 用于对应索引为 0 的单词,用于填充句子:
for i, (input_text, target_text) in enumerate(zip(lines.eng, lines.fr)):
for t, word in enumerate(input_text.split()):
encoder_input_data[i, t] = input_token_index[word]
for t, word in enumerate(target_text.split()):
# decoder_target_data 领先于decoder_input_data 一个时间戳
decoder_input_data[i, t] = target_token_index[word]
if t>0:
# decoder_target_data 将提前一个时间戳,且不包括起始字符
decoder_target_data[i, t - 1, target_token_index[word]] = 1.
if t== len(target_text.split())-1:
decoder_target_data[i, t:, target_token_index['end']] = 1
在以上代码中,我们遍历输入文本和目标文本,以将英语或法语中的句子替换为其对应的英语和法语中的单词 ID。
此外,我们对目标数据进行独热编码,以便将其传递给模型。此外,由于我们已经将所有句子填充为相同长度,在 for 循环中超过句子长度之后,我们将目标数据的值替换为结束标注单词 end:
for i in range(decoder_input_data.shape[0]):
for j in range(decoder_input_data.shape[1]):
if(decoder_input_data[i][j]==0):
decoder_input_data[i][j] = target_token_index['end']
在以上代码中,我们将解码器输入数据中的 0 值替换为结束标记,0 在我们创建的单词索引中没有任何与之关联的单词,我们创建的三个数据集的形状如下:
print(decoder_input_data.shape,encoder_input_data.shape,decoder_target_data.shape)
数据集形状的输出如下:
(100000, 18) (100000, 18) (100000, 18, 417)
(2) 构建模型,编译并拟合模型:
model = Sequential()
model.add(Embedding(len(input_words)+1, 128, input_length=fr_max_length, mask_zero=True))
model.add((Bidirectional(LSTM(256, return_sequences = True))))
#model.add(RepeatVector(fr_max_length))
model.add((LSTM(256, return_sequences=True)))
model.add((Dense(len(target_token_index)+1, activation='softmax')))
model.summary()
model.compile(optimizer='adam', loss='categorical_crossentropy',metrics=['acc'])
history = model.fit(encoder_input_data, decoder_target_data,
batch_size=64,
epochs=10,
validation_split=0.1,
verbose=1)
构建的模型简要信息如下所示:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 18, 128) 51200
_________________________________________________________________
bidirectional (Bidirectional (None, 18, 512) 788480
_________________________________________________________________
lstm_1 (LSTM) (None, 18, 256) 787456
_________________________________________________________________
dense (Dense) (None, 18, 417) 107169
=================================================================
Total params: 1,734,305
Trainable params: 1,734,305
Non-trainable params: 0
_________________________________________________________________
在模型训练过程中,模型的损失和准确率变化如下:
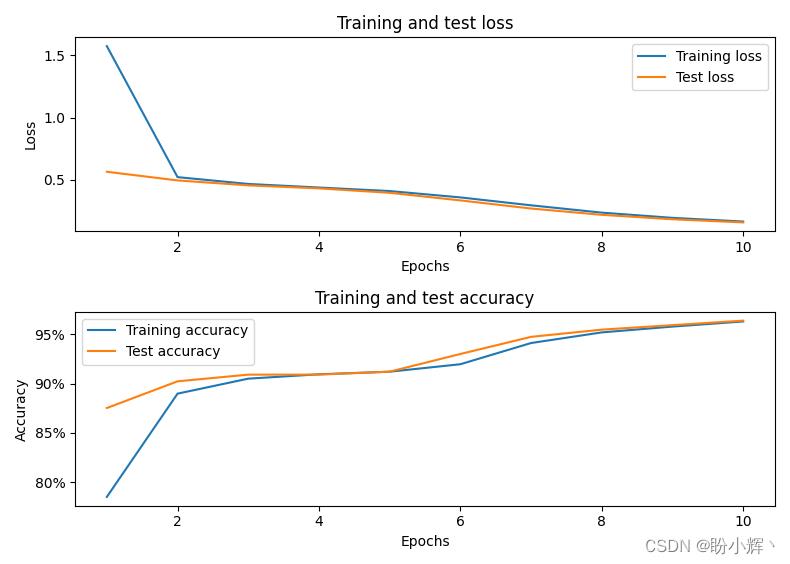
(3) 计算正确翻译的单词数,由于我们使用 90% 的数据进行训练,因此接下来,我们使用最后的 10% 的数据作为验证集进行计算:
count = 0
correct_count = 0
pred = model.predict(encoder_input_data[90000:])
for i in range(10000):
t = np.argmax(pred[i], axis=1)
act = np.argmax(decoder_target_data[90000],axis=1)
correct_count += np.sum((act==t) & (act!=target_token_index['end']))
count += np.sum(act!=target_token_index['end'])
print(correct_count/count)
计算完成后,我们可以看到大约有 14.02% 的单词可以被正确翻译。
2.3 使用具有多个隐藏层的模型架构
传统体系结构的缺点之一是,我们必须人为地将输入中的时间戳增加到指定数量,即使我们知道在某些输入中最多有 10 个时间戳。接下来,我们构建具有多个隐藏层的模型在输入的最后一个时间戳提取网络中间状态值;此外,它会将网络中间状态值复制 18 次,因为输出中有 18 个时间戳。然后,通过 Dense 层传递复制的状态值,并最终提取输出中可能的类别。
(1) 重新创建输入和输出数据集,这样我们在输入中有 8 个时间戳(而在上一小节介绍的传统网络架构中,输入中有 18 个时间戳),在输出中有 18 个时间戳:
encoder_input_data = np.zeros(
(len(lines.eng), eng_max_length),
dtype='float32')
decoder_input_data = np.zeros(
(len(lines.fr), fr_max_length),
dtype='float32')
decoder_target_data = np.zeros(
(len(lines.fr), fr_max_length, num_decoder_tokens+1),
dtype='float32')
for i, (input_text, target_text) in enumerate(zip(lines.eng, lines.fr)):
for t, word in enumerate(input_text.split()):
encoder_input_data[i, t] = input_token_index[word]
for t, word in enumerate(target_text.split()):
# decoder_target_data is ahead of decoder_input_data by one timestep
decoder_input_data[i, t] = target_token_index[word]
if t>0:
# decoder_target_data will be ahead by one timestep
# and will not include the start character.
decoder_target_data[i, t - 1, target_token_index[word]] = 1.
if t== len(target_text.split())-1:
decoder_target_data[i, t:, target_token_index['end']] = 1
for i in range(decoder_input_data.shape[0]):
for j in range(decoder_input_data.shape[1]):
if(decoder_input_data[i][j]==0):
decoder_input_data[i][j] = target_token_index['end']
(2) 建立模型,使用 RepeatVector 层将 双向 LSTM 层的输出复制 18 次:
from keras.models import Sequential, Model
from keras<以上是关于Keras深度学习实战(35)——构建机器翻译模型的主要内容,如果未能解决你的问题,请参考以下文章