Keras学习及运行官方实例(2022.2.24)
Posted jing_zhong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras学习及运行官方实例(2022.2.24)相关的知识,希望对你有一定的参考价值。
Keras学习及官方实例运行 2022.2.24
- 1、Keras简介
- 2、Keras官方示例测试运行
- 2.1 所用软硬件环境
- 2.2 六个实例运行
- 2.2.1 Simple MNIST convnet(MNIST数字分类)
- 2.2.2 Timeseries forecasting for weather prediction(基于时间序列预报数据进行天气预测)
- 2.2.3 Neural style transfer(使用梯度下降将参考图像的风格转移到目标图像 )
- 2.2.4 OCR model for reading Captchas(光学字符识别模型用于读取图片验证码)
- 2.2.5 Graph attention network (GAT) for node classification(图注意力网络用于节点分类)
- 2.2.6 Collaborative Filtering for Movie Recommendations(基于协同过滤的电影推荐)
- 3、总结
1、Keras简介
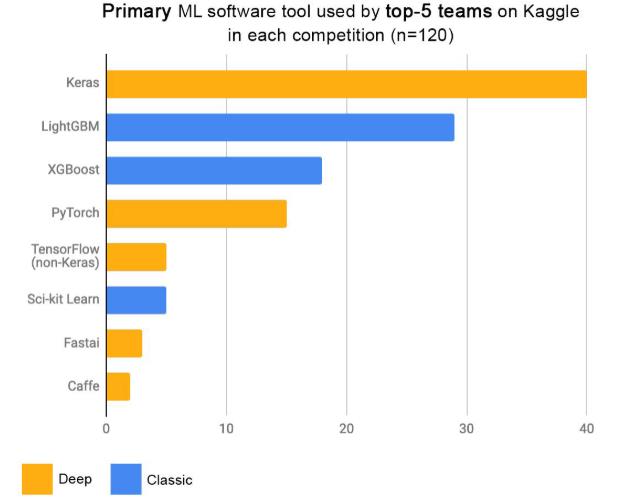
Keras是一个用Python编写的深度学习API,运行在机器学习平台TensorFlow 之上。 它的开发重点是实现快速实验,能够尽快将想法转化为结果是做好研究的关键。
1.1 Keras的特点
Keras具有以下三个特点:
- 简单——但不简单。
Keras减少了开发人员的认知负担,让用户可以专注于真正重要的问题部分。 - 灵活——
Keras采用逐步披露复杂性的原则:简单的工作流应该快速简单,而任意高级的工作流应该通过建立在已经学过的基础上的清晰路径成为可能。 - 功能强大——
Keras提供行业实力的性能和可扩展性:它被包括NASA、YouTube或Waymo在内的组织和公司使用。
1.2 Keras与Tensorflow的关系
TensorFlow 2 是一个端到端的开源机器学习平台,可以将其视为可微分编程的基础设施层。它结合了四种关键能力:
- 在
CPU、GPU或TPU上高效执行低级张量操作; - 计算任意可微表达式的梯度;
- 将计算扩展到许多设备,例如数百个 GPU 的集群;
- 将程序(图表)导出到外部运行时,例如服务器、浏览器、移动和嵌入式设备.
Keras 是 TensorFlow 2 的高级 API:一个用于解决机器学习问题的实用、高效的接口,专注于现代深度学习。它为开发和交付具有高迭代速度的机器学习解决方案提供了必要的抽象和构建块。
Keras 使工程师和研究人员能够充分利用 TensorFlow 2 的可扩展性和跨平台功能:用户可以在 TPU 或大型 GPU 集群上运行 Keras,并且可以导出 Keras 模型以在浏览器或移动设备上运行设备。 然而,Keras 也是一个高度灵活的框架,适合迭代最先进的研究理念。 Keras 遵循逐步披露复杂性的原则:它使入门变得容易,但它可以处理任意高级用例,只需要在每个步骤中进行增量学习。
1.3 Keras安装
Keras 与 TensorFlow 2 一起打包为 tensorflow.keras。Keras/TensorFlow兼容的计算机操作系统有Ubuntu 16.04 or later、Windows 7 or later和macOS 10.12.6 (Sierra) or later,支持的Python版本有Python 3.6–3.9。 如果要开始使用 Keras,只需安装 TensorFlow 2,可根据自己电脑硬件配置适当选择并参考Windows 7搭建TensorFlow深度学习框架实战。

1.4 Keras帮助
如果开发人员想进一步学习或者研究Keras的API函数,可以利用Keras官网自带示例进行实战,搭建环境运行代码,进行相关开发或者研究。
2、Keras官方示例测试运行
2.1 所用软硬件环境
软件:Win11 64位+Python 3.6+tensorflow-gpu 2.3.1
硬件:NVIDIA GTX1050TI显卡、运行内存8GB
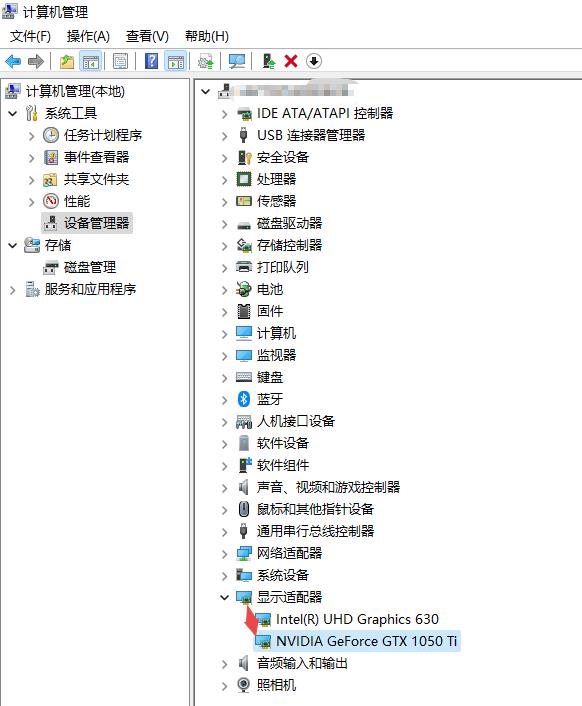

电脑配置了GTX 1050Ti显卡,在安装Microsoft Visual C++ Redistributable 2015-2019后又安装了CUDA 10.1的驱动程序和Cudnn 7.6.5,建议使用Anaconda创建Python虚拟环境,在虚拟环境中利用pip安装依赖包。

Python3.6环境(tensorflowgpu)中通过pip安装的依赖包如下:
absl-py==1.0.0
astunparse==1.6.3
cachetools==4.2.4
certifi==2021.10.8
charset-normalizer==2.0.12
cycler==0.11.0
dataclasses==0.8
gast==0.3.3
google-auth==2.6.0
google-auth-oauthlib==0.4.6
google-pasta==0.2.0
grpcio==1.43.0
h5py==2.10.0
idna==3.3
importlib-metadata==4.8.3
Keras-Preprocessing==1.1.2
kiwisolver==1.3.1
Markdown==3.3.6
matplotlib==3.3.4
numpy==1.18.5
oauthlib==3.2.0
opt-einsum==3.3.0
pandas==1.1.5
Pillow==8.4.0
protobuf==3.19.4
pyasn1==0.4.8
pyasn1-modules==0.2.8
pyparsing==3.0.7
python-dateutil==2.8.2
pytz==2021.3
requests==2.27.1
requests-oauthlib==1.3.1
rsa==4.8
scipy==1.2.1
six==1.16.0
tensorboard==2.8.0
tensorboard-data-server==0.6.1
tensorboard-plugin-wit==1.8.1
tensorflow-addons==0.14.0
tensorflow-gpu==2.3.1
tensorflow-gpu-estimator==2.3.0
termcolor==1.1.0
typeguard==2.13.3
typing_extensions==4.1.1
urllib3==1.26.8
Werkzeug==2.0.3
wincertstore==0.2
wordcloud==1.8.1
wrapt==1.12.1
zipp==3.4.0
2.2 六个实例运行
本文基于官网介绍的Keras示例,从中挑选了以下六个实例并运行了对应的Python代码,基于tensorflow-gpu 2.3.1版本来使用keras:from tensorflow import keras
2.2.1 Simple MNIST convnet(MNIST数字分类)
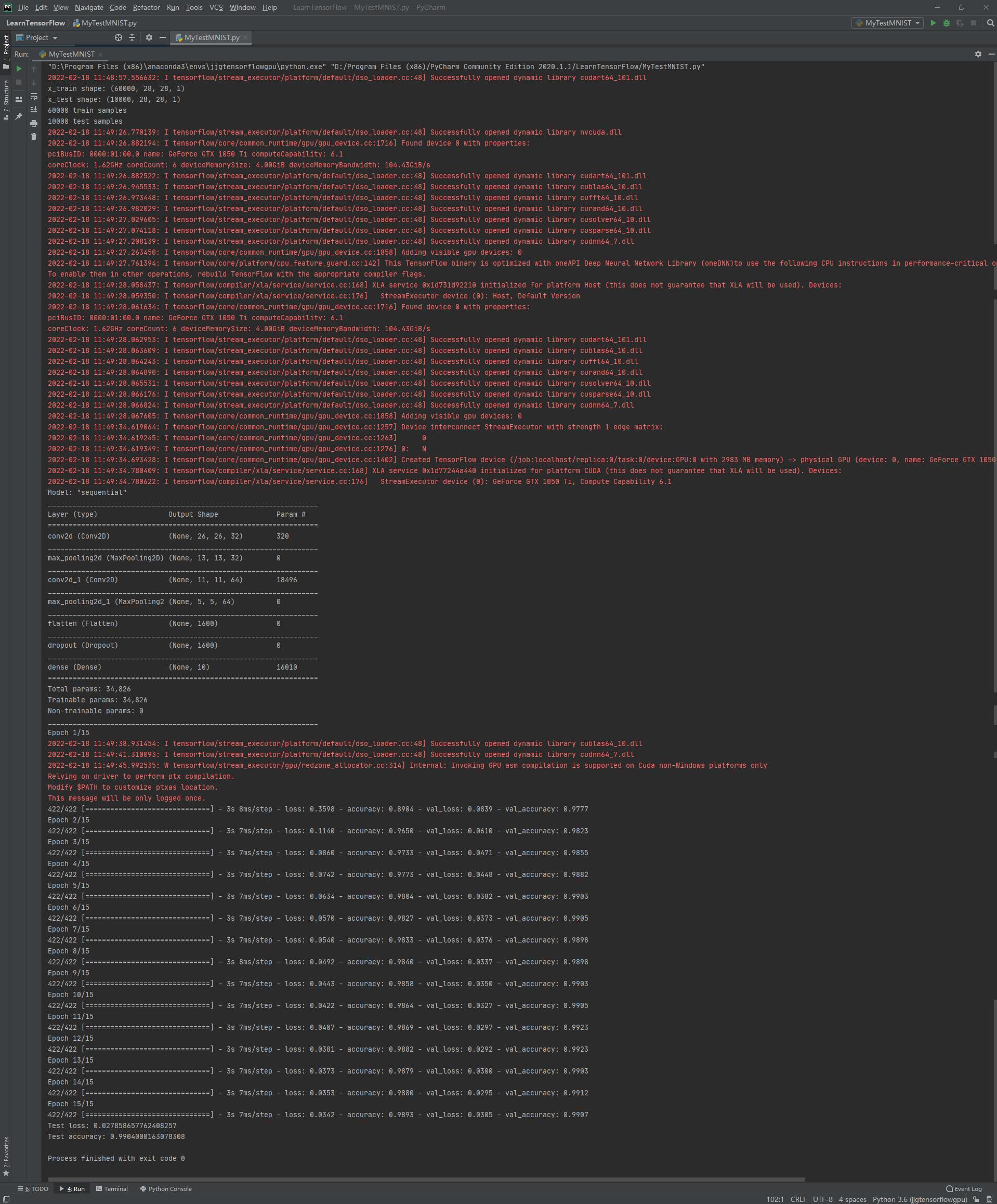
在MNIST网站可以看到MNIST数据集的简介,此实例实现了一个简单的卷积网络模型,在 MNIST 上达到了约 99% 的测试准确度,下载的数据mnist.npz如下图所示。

训练代码及运行结果(MyTestMNIST.py)
import numpy as np
import matplotlib.pyplot as plt
from tensorflow import keras
from tensorflow.keras import layers
num_classes = 10 # All digits are 10 classes.
input_shape = (28, 28, 1)
path = 'mnist.npz'# https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
f = np.load(path, allow_pickle=True)
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test'] # the data, split between train and test sets
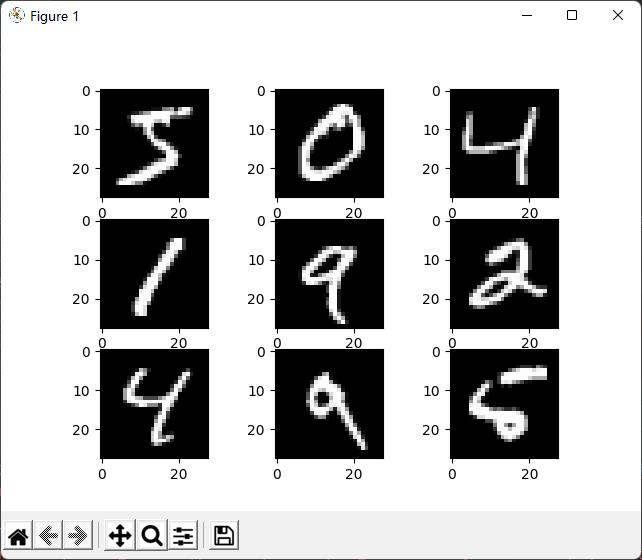
# plot 4 images as gray scale
plt.subplot(331)
plt.imshow(x_train[0], cmap=plt.get_cmap('gray'))
plt.subplot(332)
plt.imshow(x_train[1], cmap=plt.get_cmap('gray'))
plt.subplot(333)
plt.imshow(x_train[2], cmap=plt.get_cmap('gray'))
plt.subplot(334)
plt.imshow(x_train[3], cmap=plt.get_cmap('gray'))
plt.subplot(335)
plt.imshow(x_train[4], cmap=plt.get_cmap('gray'))
plt.subplot(336)
plt.imshow(x_train[5], cmap=plt.get_cmap('gray'))
plt.subplot(337)
plt.imshow(x_test[6], cmap=plt.get_cmap('gray'))
plt.subplot(338)
plt.imshow(x_test[7], cmap=plt.get_cmap('gray'))
plt.subplot(339)
plt.imshow(x_test[8], cmap=plt.get_cmap('gray'))#imshow函数的官方文档:https://matplotlib.org/api/_as_gen/matplotlib.pyplot.imshow.html#matplotlib.pyplot.imshow
# show the plot
plt.show()
# Scale images to the [0, 1] range
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
# Make sure images have shape (28, 28, 1)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
print("x_train shape:", x_train.shape)
print("x_test shape:", x_test.shape)
print(x_train.shape[0], "train samples")
print(x_test.shape[0], "test samples")
y_train = keras.utils.to_categorical(y_train, num_classes)# convert class vectors to binary class matrices
y_test = keras.utils.to_categorical(y_test, num_classes)#将类别标签转换为onehot编码,onehot编码是一种方便计算机处理的二元编码
model = keras.Sequential(
[
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.summary()
batch_size = 128
epochs = 15
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) #binary_crossentropy 二进制交叉熵用于二分类问题中,categorical_crossentropy分类交叉熵适用于多分类问题
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
score = model.evaluate(x_test, y_test, verbose=0)
print("Test loss:", score[0])
print("Test accuracy:", score[1])
model.save('mnist_Model.h5')

预测代码及运行结果 (PredictMNIST.py)
from tensorflow.keras.models import load_model
import numpy as np
import matplotlib.pyplot as plt
mnist_model = load_model('mnist_Model.h5')# load the trained mnist_model
path = 'mnist.npz'# http://yann.lecun.com/exdb/mnist/mnist.npz
f = np.load(path, allow_pickle=True)
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test'] # Get the train and test sets data
X_Train99,Y_Train99 = x_train[99],y_train[99]# Select one from train data sets
X_Test999,Y_Test999 = x_test[999],y_test[999]# Select one from test data sets
print(X_Train99.shape)
X_Train99.shape=(1,28,28,1)
predict_Y_Train99 = mnist_model.predict(X_Train99)
print(predict_Y_Train99)
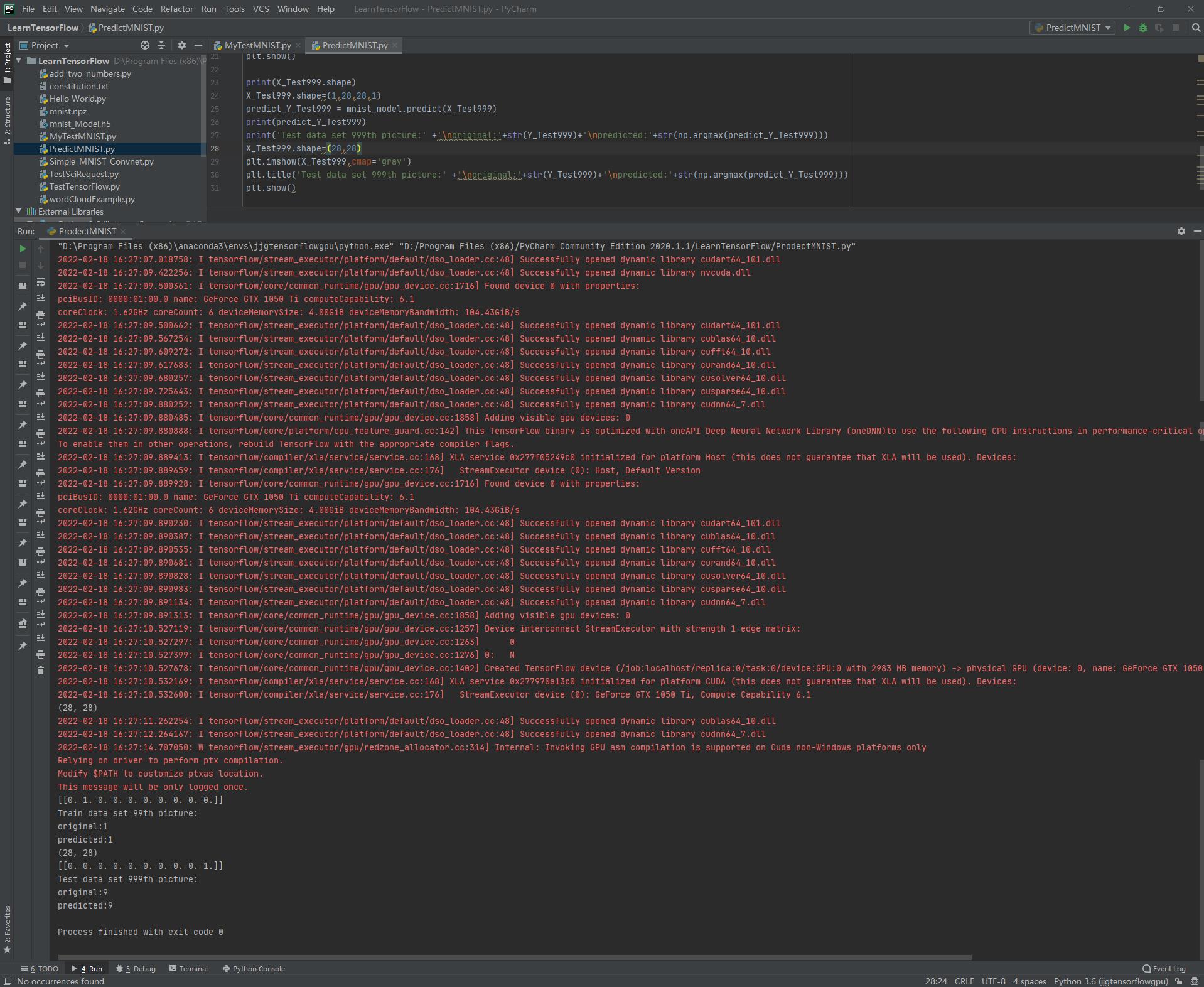
print('Train data set 99th picture:' + '\\noriginal:'+str(Y_Train99) + '\\npredicted:'+str(np.argmax(predict_Y_Train99)))
X_Train99.shape=(28,28)
plt.imshow(X_Train99,cmap='gray')
plt.title('Train data set 99th picture:' + '\\noriginal:'+str(Y_Train99) + '\\npredicted:'+str(np.argmax(predict_Y_Train99)))
plt.show()
print(X_Test999.shape)
X_Test999.shape=(1,28,28,1)
predict_Y_Test999 = mnist_model.predict(X_Test999)
print(predict_Y_Test999)
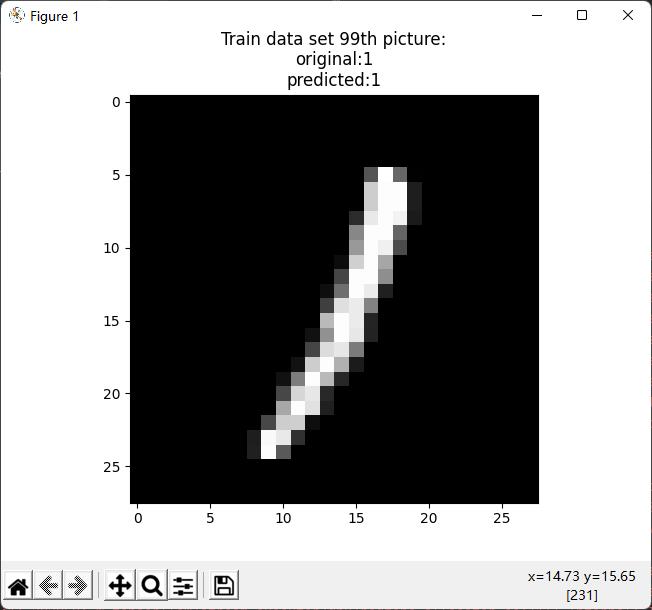
print('Test data set 999th picture:' +'\\noriginal:'+str(Y_Test999)+'\\npredicted:'+str(np.argmax(predict_Y_Test999)))
X_Test999.shape=(28,28)
plt.imshow(X_Test999,cmap='gray')
plt.title('Test data set 999th picture:' +'\\noriginal:'+str(Y_Test999)+'\\npredicted:'+str(np.argmax(predict_Y_Test999)))
plt.show()
2.2.2 Timeseries forecasting for weather prediction(基于时间序列预报数据进行天气预测)
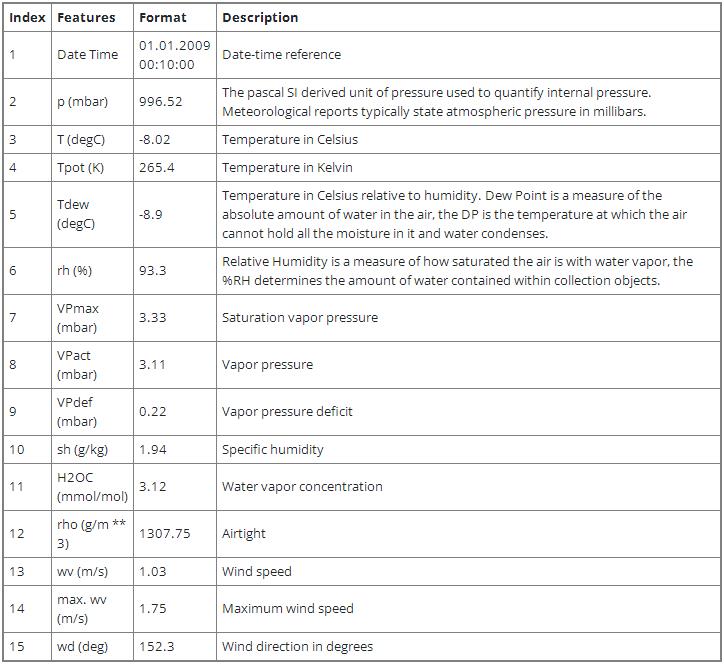
此实例使用马克斯普朗克生物地球化学研究所记录的耶拿气候数据集。 该数据集由 14 个特征组成,例如温度、压力、湿度等,每 10 分钟记录一次。
- 地点:德国耶拿马克斯普朗克生物地球化学研究所气象站
- 考虑的时间范围:
2009 年 1 月 10 日 - 2016 年 12 月 31 日
下表显示了列名、它们的值格式以及描述:
代码及运行结果(timeseries_weather_forecasting.py)
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
csv_path = "jena_climate_2009_2016.csv"
df = pd.read_csv(csv_path)
titles = [
"Pressure",
"Temperature",
"Temperature in Kelvin",
"Temperature (dew point)",
"Relative Humidity",
"Saturation vapor pressure",
"Vapor pressure",
"Vapor pressure deficit",
"Specific humidity",
"Water vapor concentration",
"Airtight",
"Wind speed",
"Maximum wind speed",
"Wind direction in degrees",
]
feature_keys = [
"p (mbar)",
"T (degC)",
"Tpot (K)",
"Tdew (degC)",
"rh (%)",
"VPmax (mbar)",
"VPact (mbar)",
"VPdef (mbar)",
"sh (g/kg)",
"H2OC (mmol/mol)",
"rho (g/m**3)",
"wv (m/s)",
"max. wv (m/s)",
"wd (deg)",
]
colors = [
"blue",
"orange",
"green",
"red",
"purple",
"brown",
"pink",
"gray",
"olive",
"cyan",
]
date_time_key = "Date Time"
def show_raw_visualization(data):
time_data = data[date_time_key]
fig, axes = plt.subplots(
nrows=7, ncols=2, figsize=(15, 20), dpi=80, facecolor="w", edgecolor="k"
)
for i in range(len(feature_keys)):
key = feature_keys[i]
c = colors[i % (len(colors))]
t_data = data[key]
t_data.index = time_data
t_data.head()
ax = t_data.plot(
ax=axes[i // 2, i % 2],
color=c,
title=" - ".format(titles[i], key),
rot=25,
)
ax.legend([titles[i]])
plt.tight_layout()
# show_raw_visualization(df)
def show_heatmap(data):
plt.matshow(data.corr())
plt.xticks(range(data.shape[1]), data.columns, fontsize=14, rotation=90)
plt.gca().xaxis.tick_bottom()
plt.yticks(range(data.shape[1]), data.columns, fontsize=14)
cb = plt.colorbar()
cb.ax.tick_params(labelsize=14)
plt.title("Feature Correlation Heatmap", fontsize=14)
plt.show()
# show_heatmap(df)
split_fraction = 0.715
train_split = int(split_fraction * int(df.shape[0]))
step = 6
past = 720
future = 72
learning_rate = 0.001
batch_size = 256
epochs = 10
def normalize(data, train_split):
data_mean = data[:train_split].mean(axis=0)
data_std = data[:train_split].std(axis=0)
return (data - data_mean) / data_std
print(
"The selected parameters are:",
", ".join([titles[i] fo以上是关于Keras学习及运行官方实例(2022.2.24)的主要内容,如果未能解决你的问题,请参考以下文章
Tensorflow+Keras学习率指数分段逆时间多项式衰减及自定义学习率衰减的完整实例