声网首席科学家钟声:感知实时互联网
Posted 声网
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了声网首席科学家钟声:感知实时互联网相关的知识,希望对你有一定的参考价值。

在「RTE2022 实时互联网大会」中,声网 CTO & 首席科学家 @钟声以《感知实时互联网》为题进行了主题演讲,分享了目前“感知技术”在实时互联网中的研究现状,以及应用前景。
本文内容基于演讲内容进行整理,为方便阅读略有删改。
以下正文:
大家好,很高兴能在 RTE2022 跟很多新老朋友就实时互动技术做一些分享。今天我会围绕计算、通信和智能的一体化,聊聊今年业界更多新研究进展。
去年我们分享过一个案例:AT & T将自己的核心网、网络云,以及云技术团队出售给了微软,自己则专注于接入网络和用户的运营。背后的主要的因在于,传统的架构已无法支持现在的网络运维以及业务支撑系统提出的的计算、智能以及存储需求。所以他们转而寻求与微软合作,由微软来满足计算、智能以及存储方面的需求。
简单地说,仅作为一个信息传输的管道,也叫 Dumb Pipe,已承载不了现在通讯的需求,因为光是传递信息还不够,还要整个链路具有提取知识、识别情感、做出决策的能力,这些也是支持实时互动不可少的要素。具有良好体验的实时互动,实际上是离不开实时感知、实时理解的能力。我们今天就以实时互动的整个链路的角度来展开本次的分享。
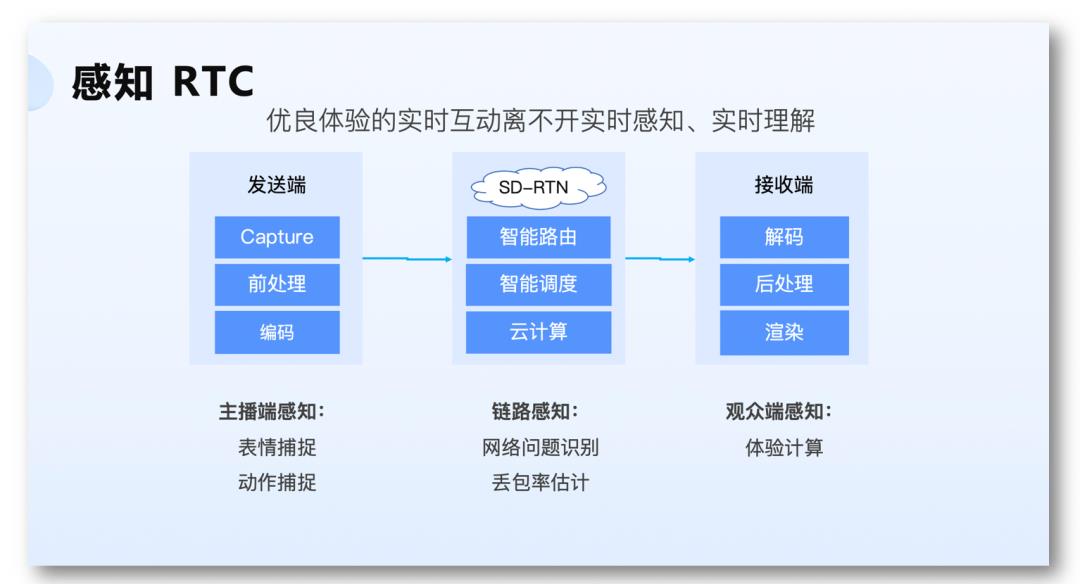
实时互动的链路就是:信号从发送端被采集,经过前处理后进行编码,然后这些数据会被传输到互联网,网络将会基于智能调度调度,找到一条合适的通路,把数据顺利地传达到接收端。这中间可能还会有一些计算的需求,比如内容的转录、识别等。在接收端数据会被解码,然后进行后处理,最终渲染、显示。
我们从这三个层次来跟大家做一些实时感知计算的案例分享。
接收端我们会从体验的估计,链路上会从传输网络的问题识别、丢包估计,主播端我们会从表情动作捕捉这方面来分享。
01 观众端的体验感知
根据近期的客户数据表明,在声网当前实时互动质量水平下,每当卡顿率下降 0.1%,用户在频道里停留的观看平均时长就会增加 0.56%,即当体验有所提升的时候,用户停留的时长就会增加,这对很多业务是至关重要的。
还有一组数据,当我们把视频从一个“高卡顿率、低清”,逐渐的提升到“低卡顿率比较流畅且高清”时,观众的观看总时长成倍增长。

从以上两组数据可以看出,提升用户体验是实时互动最根本的追求。
不过,感知体验存在不少难题需要解决。首先就是如何测量/估计用户的体验。我们从技术的角度,总是希望通过一些新工具、新算法来提升用户的体验,但是怎么衡量这些新算法、新工具的有效性呢?
实际上这是比较难的事情,往往 to C 的公司,会在线上通过 A/B 测试,来判断新工具和新算法的有效性,或是在线下通过大量用户参与,来做主观分评价,这实际上是一件耗时费力的方法,而且线下打分是无法 100% 提现用户在线上实时的质量体验。所以缺少线上的实时质量普查,任何团队都很难从运维的角度刻画全网的实时通讯服务的质量。实时质量洞察其实是一种很重要的能力。
由于网络条件是随时变化的,当网络出现拥堵或丢包的时候,质量通常会下降。如果我们能及时洞察到的话,就可以通过一系列的策略调整,弥补变差的网络状况带来的质量影响。比如,我们可以调整传输的线路,也可以调整传输的视频分辨率、帧率,以避免出现卡顿。所以具备对用户体验的感知能力,至关重要。
用户体验是一个具有主观性的感知,怎样估计主观性,还需要比较深入的研究。首先,用户打分具有“不确定性”。如果你找一组用户来对一些视频打分,分数往往分布在一个范围之内,我们从中取平均值,得到的就是 MoS 分,即主观分。不同用户打分会有差别,他们在不同的场景下可能也会打出不同的体验分。有的场景下,用户看重音视频的流畅度,有的场景则更看重是否够清晰。打分不仅与用户、场景相关,还与很多因素相关,包括时空、时域、设备、显示尺寸等。
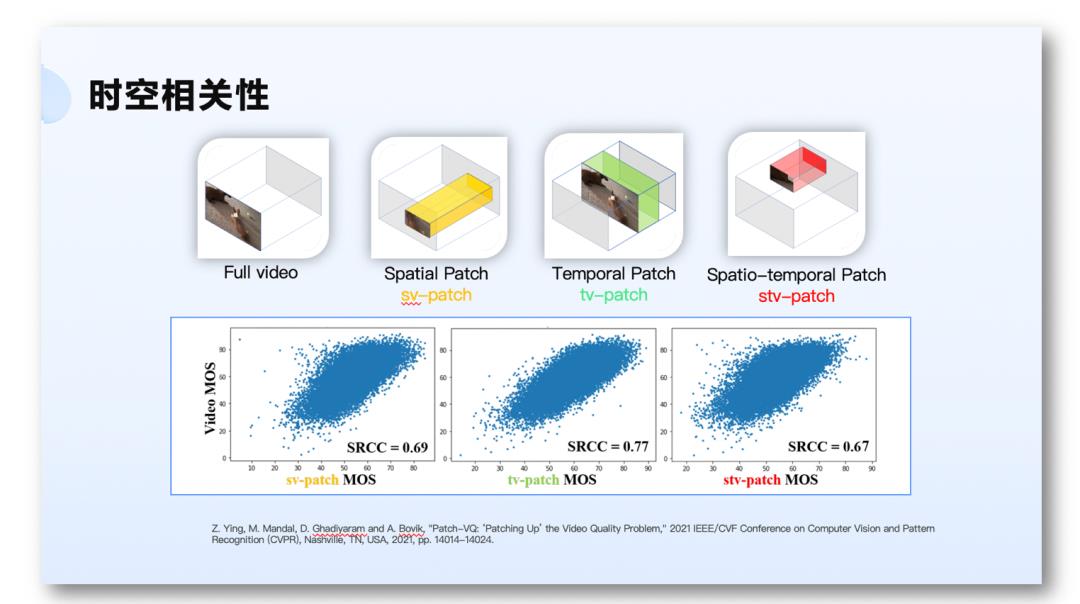
怎么理解时空相关性呢?我们举个例子,我们提供一段完整的视频,请人为它打主观分之后,我们如果在空间上截取一段视频,只有局部的视频参与评价的话,它与整段视频的 MoS 分的相关性为 69%。反过来,如果我们保持空间上的内容,仅取一段时间的完整画面的视频,它与原视频的 MoS 分的相关性为 77%。如果我们在空间和时间上都做一些截取,再做一次打分,它与整段视频的 MoS 分的相关性为 67%。这个实验说明了体验随视频数据时空变化而变化。
还有一个特点,体验是具有滞后效应的,并且较差的质量带来的体验具有延续性,哪怕在用户发现体验变差后质量提升了,这个较差的体验还会影响用户一段时间。有研究就用公式把这一特性表征出来了,如下图公式所示。

比如用户是在  这个时刻进行主观打分,其实评价的是
这个时刻进行主观打分,其实评价的是  时刻的体验。在
时刻的体验。在  时刻之前发生的最差的体验,可以用
时刻之前发生的最差的体验,可以用  个公式,它表达了之前视频质量的最小值。
个公式,它表达了之前视频质量的最小值。 时刻之后的质量,我们从高到低进行排序,并赋予相应的权重,通常会给质量最差的时刻赋予的最大权重。我们通过这样一系列计算来刻画体验及其滞后性。最后这两部分再加权起来,并且在时间上做一个平滑,来表征真正的体验。
时刻之后的质量,我们从高到低进行排序,并赋予相应的权重,通常会给质量最差的时刻赋予的最大权重。我们通过这样一系列计算来刻画体验及其滞后性。最后这两部分再加权起来,并且在时间上做一个平滑,来表征真正的体验。
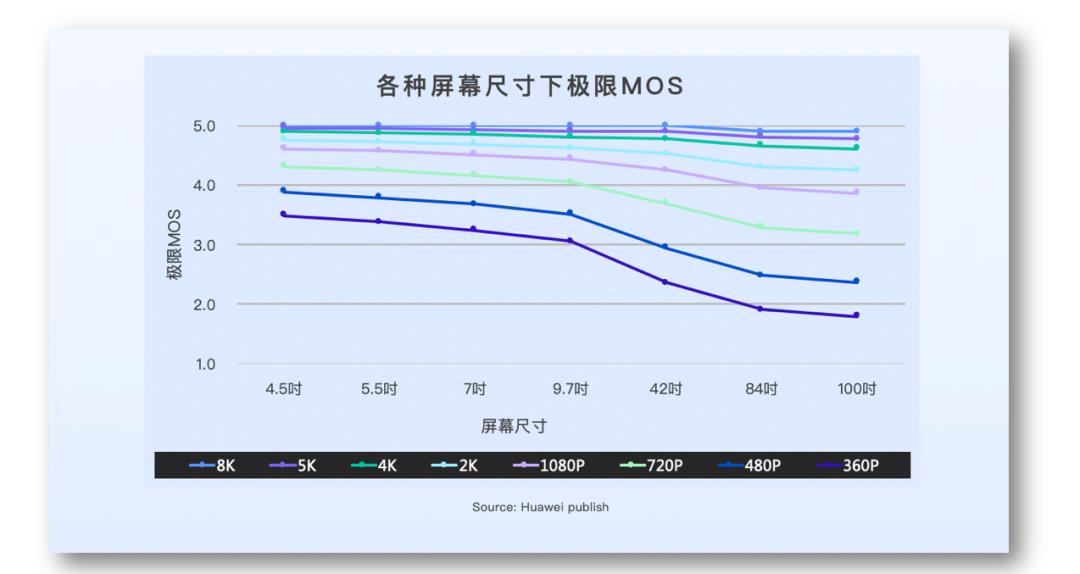
另外,如上图所示,它与设备也是相关的。在不同设备上,同一个人去观看同一个视频,所得到的主观体验分是不一样的。你在小尺寸设备上获得完美体验的一个视频,再放到更大的设备上显示的时候,获得的体验反而会下降。只有当分辨率足够大的时候,如 4K、8K 的视频,才不容易出现这种问题。
基于就是上述这些观察以及研究,我们试图把这些性质和特点,用算法的方式把它体现出来。例如,我们试图利用深度神经网络,做主观分的估计。这里通常有两种方法,一种就是下图左上方这条路径描绘的,做一个端到端的神经网络模型,把事先标注好的视频和带有 MoS 分的标签,作为训练数据灌入到端到端模型里进行训练,最后训练好的模型来做推理,打主观分。
另外一种是分阶段的,下图左下方可以看到两个阶段。首先是有一个特征提取的网络(Feature Extractor),把一些跟体验相关的特征提取出来,再把它们送入到一个回归网络中(Regression),最后得到 MoS 分。

我们声网在这方面做了大量研究,包括从数据的采集、标注,场景的多样性,最后把神经网络做到极致小,参数量和计算量都非常小,可以适用于移动端的运行环境。
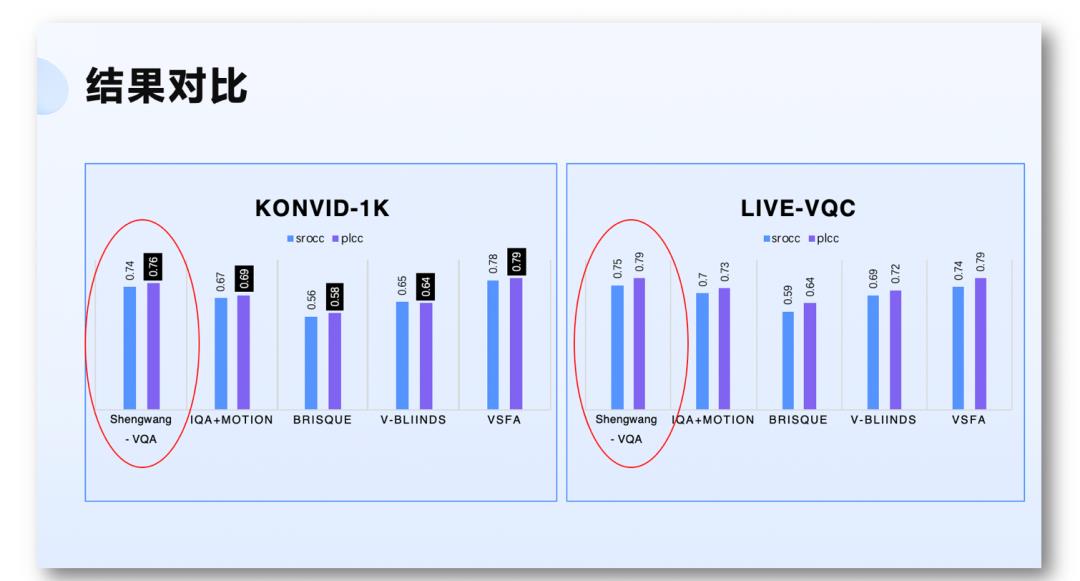
如上图右侧展示的,跟业界的另外一个标杆叫 MobileNet version 2 相比,声网模型的参数量和计算量明显更低。这保证了该模型能低功耗、顺畅地在移动端运行。那么实际运行的效果、精度如何呢?经过我们的迭代,如下图所示,声网 VQA 模型的主观分评价,已经明显好于一些业界的模型。
02 链路感知:网络问题识别、丢包率估计
接下来,我们来看看在传播链路上的感知能力。
数据在链路上传播时,由于网络条件的变化、网络拥塞或信号干扰,会出现丢包的情况。如果在网络底层出现问题时,我们能识别、计算丢包率,那么我们就能调整策略,寻找更优传输路径,或调整视频分辨率、帧率、码率。那么我们如何才能做到呢?
丢包的原因多种多样,比如:
- 无线连接信号受干扰,不论是 WIFI,还是 4G/5G,都会收到干扰,尤其是在机场、地铁、火车站这种人多、信号复杂的环境。
- 传输网络链路上出现拥堵(接入,SFU,…)
- 运营商在不同时段采取策略性地限流,如policing 或 Traffic shaping等。
这些问题都不是可以观测到的,所以想实时识别丢包的原因是什么,比较困难。而且,大部分丢包都是在 burst 的情况下,一组组地丢包,更难进行识别和估计。
于是,为了解决这个问题,我们进行了一些分析和建模。

如上图所示,假设我们有 K 种网络条件,任何一个网络条件都有一定发生概率。进入一种网络条件的时,它引起丢包的概率是  ,丢包率是
,丢包率是  。我们通常会在实际的实践中,进行丢包重传,并且第二次传或第三次重传的时候,数据有可能会被收到。重传它当然就是说也带来一些副作用,比如说延时会变得更高等等。所以就是用上面的图来表达一个包要被传输的时候,有可能进入其中的一种网络状态。而真正在能观测到的,是接收端是否收到了这个包。Y=1 就是被收到了,Y=0 就是丢包了,当等于 0 的时候,我们还要进行重传,等于 1 的时候,对包的观测就结束了。
。我们通常会在实际的实践中,进行丢包重传,并且第二次传或第三次重传的时候,数据有可能会被收到。重传它当然就是说也带来一些副作用,比如说延时会变得更高等等。所以就是用上面的图来表达一个包要被传输的时候,有可能进入其中的一种网络状态。而真正在能观测到的,是接收端是否收到了这个包。Y=1 就是被收到了,Y=0 就是丢包了,当等于 0 的时候,我们还要进行重传,等于 1 的时候,对包的观测就结束了。

另外,我们还能观测到一些它的性质。假设当前是 T 时刻,就是说这个包能不能收到仅仅依赖于这个包,本身是进入了哪个网络状态,或者是它的根因。另外就是下一时刻,这个包要进入到什么状态,也仅依赖于上一时刻它是在什么状态,在哪个网络条件,这就是一个典型的隐马尔可夫模型了。于是我们就建立了一个基于隐马尔可夫模型的估计方法,如下图所示。

首先,第一组参数是状态转移矩阵,意味着某个网络状态在下一时刻会转移到另一个网络状态的概率。这个概率就用 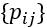 来表达。
来表达。
另外,一旦进入某个网络状态之后,我们就开始在接收端观察,这个矩阵就叫做发射矩阵,Emission Matrix。它也是需要有一组参数要来估计,包括它的丢包率。这些参数其实不是那么容易估计的,要靠很多的数据。实际原理是利用最大自然估计。还有一个还比较实用的方法,就是 Baum-Welch 算法。它是期望最大化算法的一个特殊算法。它相对来说计算量是比较可控一些。

有了参数估计之后,我们就可以开始计算丢包率,或者说接收率。如上图公式所示,假设传输的是视频帧,包括 N 个包,允许 T 次重传,首次重传之后还允许它 T 次重传。如果没有收到的话,整个视频帧完整的被收到的概率是可以计算的,即  ,它最终是
,它最终是  。
。 就是上图右侧公式来表达。
就是上图右侧公式来表达。
某一个包被收到的概率等于,第一次发送就收到的概率,加上第一次发送没收到,然后重传一次后被收到的概率,一直再加上到 T-1 次重传都没有收到,最后 T 次重传的时候被收到的概率。我们可以发现,利用隐马尔可夫的性质以及贝叶斯估计,能够迭代式地算出来,从  一直到
一直到 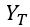 的概率最后变成计算 到
的概率最后变成计算 到  的概率这么一个表达式。我们可以用动态规划的方式,迭代式的就计算出来了。这中间用到了隐马尔可夫模型的一些性质。
的概率这么一个表达式。我们可以用动态规划的方式,迭代式的就计算出来了。这中间用到了隐马尔可夫模型的一些性质。

关于根因推断,我们希望在观测到  到
到  这个序列的时候,能计算出某时刻究竟是进入了哪个网络状态,或者哪个根因。计算的公式
这个序列的时候,能计算出某时刻究竟是进入了哪个网络状态,或者哪个根因。计算的公式  ,实际上是计算最大后验概率,也可以迭代式地计算出来。
,实际上是计算最大后验概率,也可以迭代式地计算出来。
03 发送端:人脸与人体的感知
发送端的视频信号被采集之后,我们可以做一系列的前处理。现在有一个方向引起了很多人的研究兴趣,那就是表情捕捉、动作捕捉的。面部捕捉和动作捕捉带来的数据,可以用来进行人脸、人体的三维重建,可以帮助进行人机交互。同时,在很多场景下,如果能清晰地看到表情、动作等细微东湖啊,可以增强互动体验的沉浸感。现在比较热门的元宇宙、数字孪生等场景,都离不开人脸、人体的感知。

人脸动作和表情的感知,其中一个比较行之有效的研究方向,就是利用三维的可形变的人脸模型来建模。这个思路大致是把人脸分解成有许多个与人脸属性相关的正交基,然后进行线性组合,再进行加权。通常是从一个标准的人脸模型出发,再根据个性化人脸提取出来的一些特定的形状或者纹理的参数,与相应的正交基组合起来,达到个性化的效果。
通常这些形状和表情的正交基,实际上是用语义解释来表征的,比如说性别偏男性还是偏女性,是胖还是瘦,还有是什么表情。每一个正交基可以有一定的语义特征。在纹理上也是如此,在面部的这种细节的一些地方,包括他的肤色,五官的一些变化,也由这些正交基来表征。所以,如果部捕捉做到特别高的精度、准确性和个性化,通常需要的正交基个数比较多,这也意味着比较大的计算量。
沿着这样的思路,当一个个性化的人脸进来的时候,我们所要做的其实就是通过人脸的分析,去找到跟人脸最贴近的那些正交基相关的系数,再把这些系数跟正交基线性组合起来,在标准脸上做相应的形变,最后就得到了一个三维的重建。

基于此,我们做了一个可以在移动端运行的人脸模型。它的顶点数有 1220 个,表情的基向量有 52 个,兼容苹果的 AR Kit。有了这个模型,我们就可以在移动端来识别、重建个性化的人脸。

我们利用神经网络,来提取这些表情参数和形状参数。因为想在移动端实现,所以要追求极小的神经网络模型。这个网络模型有一个 backbone,就是主干网络,以及两个分支的回归网络共同组成。这两个分支网络,一个是直接回归三维的表情和形状参数,另外一个是两维关键点的回归,来辅助提升三维参数的提取的精度和效果。训练好以后,实际上二维关键点的网络是不需要参与实时推理的,那这样只有三维参数这一支需要计算,这也就减轻了计算量。
其实人体模型也是跟我们的人脸模型有相似之处,仍然是要找到一些的基模板。然后再根据形状找到个性化参数,然后与基模板线性组合,修正标准的人体模型。最后通过蒙皮,把一些细节加上去,恢复最后的三维的形状以及动作。

如上图中第二个人体模型,就是对形状进行了一些修正。基本上就是要提取形状参数,形状那些基,也是由 PC 主成分分析这样得到的。另外,人体姿态也有一些基模板,同样也是通过主成分分析 PC 可以得到,再把它加权起来作为动作前的形态的修正。最后还可以把关节点、骨骼点的一些东西加上去,最后形成了带动作的模型,就是右下图显示的人体模型。

业界有一个经典的人体表示模型,叫 SMPL。这个模型生成大约 6000 多个顶点的 Mesh ,23 个骨骼点,再加上一个基准点。它的整个的人体参数是 72 个。然后再加上 10 个人体形状的参数。由于它还缺少一些细节,所以业界在 SMPL 的基础上又开发了一个扩展模型,叫 SMPL Extension,该模型的 Mesh 的顶点超过了 1 万个。另外,在原有的 23 个骨骼点基础上,SMPL Extension 大致增加了 30 个跟手相关的这些关键点。并且还增加了一些能表征表情的基。所以可以看到这样它就可以表达手指的屈伸,还可以还原较为丰富的表情和纹理。
由此我们可以得出一个结论:模型的基越多,带来的效果就越真实,越能表征出细致的动作和表情,但是这会也带来较大的计算量。

这些方法往往还存在一些问题,比如一些动作不符合物理学原理,无法有效应对遮挡,还有由于保真度不高,可能引发的“恐怖谷效应”等等。
我们举两个例子,第一个,就是我刚才说物理学原理,有研究真的是把物理学的一些约束引入到了整个建模和优化的过程中。物理学的约束,除了最小化三维数据与真实数据之间的误差,还会引入速度上的平滑,加速度的平滑,以及接触点上的一些约束。

第一个公式,就是我刚才说的,最小化恢复出的三维数据的误差,包括了一些速度和加速度的误差在里面。

在高保真方向上,业界也有一些有趣的的研究。比如利用神经网络,对辐射场的一个神经渲染,后来又出现了利用生成对抗网络,同样对辐射场做一些神经渲染,以及最近利用吸收体速的渲染。这些都是 3D 感知的一些方法。
04 总结
实时感知和理解能力,在实时互动多个层面都起到了重要作用,包括体验质量、传输质量、三维重建、人机交互等。
实时感知和互动的能力,实际上在很多业务场景中都有很强的需求,比如做实时的监测、质检,比如在我们金融银行系统里的金融双录,甚至实时判别银行柜台服务人员跟远程用户之间互动,以及是否有一些违规的操作,另外还有实时鉴黄鉴暴,以及实时转录翻译等等。可见实时感知和理解能力,在未来的实时互动场景里会有越来越多的需求,而随着技术的进步,这方面给用户带来的体验和价值会越来越高。
以上是关于声网首席科学家钟声:感知实时互联网的主要内容,如果未能解决你的问题,请参考以下文章