绪论
Posted BkbK-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了绪论相关的知识,希望对你有一定的参考价值。
【神经网络与深度学习摘要】第1章 绪论
文章目录
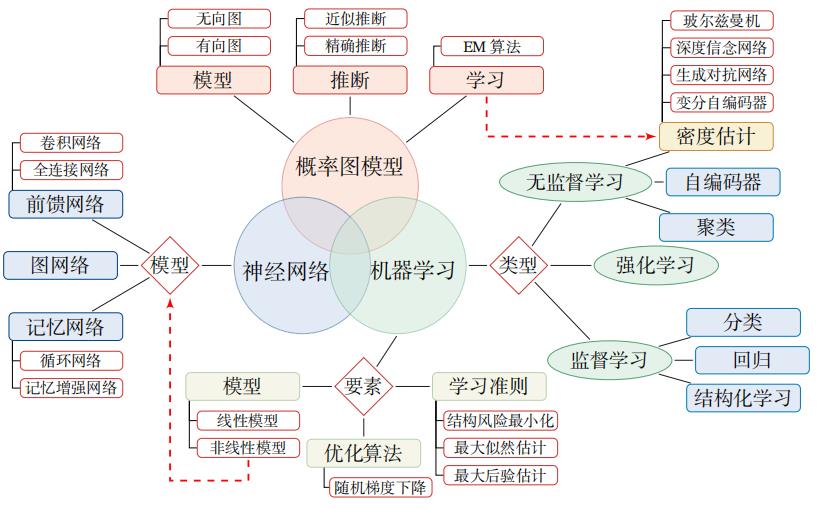
1.人工智能
1.1 图灵测试
一个人在不接触对方的情况下,通过一种特殊的方式和对方进行一系列的问答.如果在相当长时间内,他无法根据这些问题判断对方是人还是计算机,那么就可以认为这个计算机是智能的.
1.2 人工智能的主要领域
- (1) 感知:模拟人的感知能力,对外部刺激信息(视觉和语音等)进行感知和加工.主要研究领域包括语音信息处理和计算机视觉等.
- (2) 学习:模拟人的学习能力,主要研究如何从样例或从与环境的交互中进行学习.主要研究领域包括监督学习、无监督学习和强化学习等.
- (3) 认知:模拟人的认知能力,主要研究领域包括知识表示、自然语言理解、推理、规划、决策等
1.3人工智能的发展历史
人工智能从诞生至今,经历了一次又一次的繁荣与低谷,其发展历程大体上可以分为“推理期”“知识期”和“学习期”

1.4 人工智能的流派
主流的方法大体上可以归结为以下两种:
-
符号主义(Symbolism),又称逻辑主义、心理学派或计算机学派,是指通过分析人类智能的功能,然后用计算机来实现这些功能的一类方法.符号主义有两个基本假设:a)信息可以用符号来表示;b)符号可以通过显式的规则(比如逻辑运算)来操作.人类的认知过程可以看作符号操作过程.在人工智能的推理期和知识期,符号主义的方法比较盛行,并取得了大量的成果.
-
连接主义(Connectionism),又称仿生学派或生理学派,是认知科学领域中的一类信息处理的方法和理论.在认知科学领域,人类的认知过程可以看作一种信息处理过程.连接主义认为人类的认知过程是由大量简单神经元构成的神经网络中的信息处理过程,而不是符号运算.因此,连接主义模型的主要结构是由大量简单的信息处理单元组成的互联网络,具有非线性、分布式、并行化、局部性计算以及自适应性等特性.
2.机器学习
2.1 机器学习定义
机器学习(Machine Learning,ML)是指从有限的观测数据中学习(或“猜测”)出具有一般性的规律,并利用这些规律对未知数据进行预测的方法.
2.2 使用机器学习模型步骤

- (1) 数据预处理:经过数据的预处理,如去除噪声等.比如在文本分类中,去除停用词等.
- (2) 特征提取:从原始数据中提取一些有效的特征.比如在图像分类中,提取边缘、尺度不变特征变换(Scale Invariant Feature Transform,SIFT)特征等.
- (3)特征转换:对特征进行一定的加工,比如降维和升维.降维包括特征抽取(Feature Extraction)和特征选择(Feature Selection)两种途径.常用的特征转换方法有主成分分析(Principal Components Analysis,PCA)、线性判别分析(Linear Discriminant Analysis,LDA)等.
3.表示学习
3.1 表示学习定义
为了提高机器学习系统的准确率,我们就需要将输入信息转换为有效的特征,或者更一般性地称为表示(Representation).如果有一种算法可以自动地学习出有效的特征,并提高最终机器学习模型的性能,那么这种学习就可以叫作表示学习(Representation Learning).
3.2 语义鸿沟
表示学习的关键是解决**语义鸿沟(Semantic Gap)**问题.语义鸿沟问题是指输入数据的底层特征和高层语义信息之间的不一致性和差异性.
3.3 局部表示和分布式表示
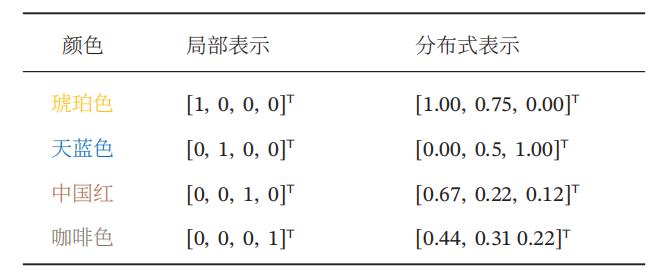
3.3.1 局部表示
局部表示定义:
一种表示颜色的方法是以不同名字来命名不同的颜色,这种表示方式叫作局部表示,也称为离散表示或符号表示.局部表示通常可以表示为one-hot 向 量的形式.
局部表示优点:
(1)这种离散的表示方式具有很好的解释性,有利于人工归纳和总结特征,并通过特征组合进行高效的特征工程
(2)通过多种特征组合得到的表示向量通常是稀疏的二值向量,当用于线性模型时计算效率非常高.
局部表示不足:
(1)one-hot向量的维数很高,且不能扩展.如果有一种新的颜色,我们就需要增加一维来表示;
(2)不同颜色之间的相似度都为0,即我们无法知道“红色”和“中国红”的相似度要高于“红色”和“黑色”的相似度.
3.3.2 分布式表示
分布式表示通常可以表示为低维的稠密向量.
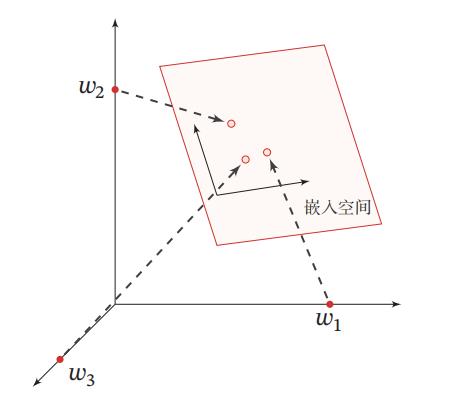
和局部表示相比,分布式表示的表示能力要强很多,分布式表示的向量维度一般都比较低.我们只需要用一个三维的稠密向量就可以表示所有颜色.并且,分布式表示也很容易表示新的颜色名.
嵌入:将高维的局部表示空间ℝ|𝒱| 映射到一个非常低维的分布式表示空间 ℝ𝐷, 𝐷 ≪ |𝒱|.在这个低维空间中,每个特征不再是坐标轴上的点,而是分散在整个低维空间中.
4.深度学习
深度学习是机器学习的一个子问题,其主要目的是从数据中自动学习到有效的特征表示
4.1 深度学习的数据处理流程

4.2 端到端学习
端到端学习(End-to-End Learning),也称端到端训练,是指在学习过程中不进行分模块或分阶段训练,直接优化任务的总体目标.在端到端学习中,一般不需要明确地给出不同模块或阶段的功能,中间过程不需要人为干预.端到端学习的训练数据为“输入-输出”对的形式,无须提供其他额外信息.
5.神经网络
5.1 人工神经网络
人工神经网络与生物神经元类似,由多个节点(人工神经元)互相连接而成,可以用来对数据之间的复杂关系进行建模.不同节点之间的连接被赋予了不同的权重,每个权重代表了一个节点对另一个节点的影响大小.每个节点代表一种特定函数,来自其他节点的信息经过其相应的权重综合计算,输入到一个激活函数中并得到一个新的活性值(兴奋或抑制).
5.2 神经网络的发展历史
第一阶段:模型提出 第一阶段为1943年~1969年,是神经网络发展的第一个高潮期.在此期间,科学家们提出了许多神经元模型和学习规则.
第二阶段:冰河期 第二阶段为1969年~1983年,是神经网络发展的第一个低谷期.在此期间,神经网络的研究处于长年停滞及低潮状态.
第三阶段:反向传播算法引起的复兴 第三阶段为1983年~1995年,是神经网络发展的第二个高潮期.这个时期中,反向传播算法重新激发了人们对神经网络的兴趣.
第四阶段:流行度降低 第四阶段为 1995 年~2006 年,在此期间,支持向量机和其他更简单的方法(例如线性分类器)在机器学习领域的流行度逐渐超过了神经网络
第五阶段:深度学习的崛起 第五阶段为从 2006 年开始至今,在这一时期研究者逐渐掌握了训练深层神经网络的方法,使得神经网络重新崛起.
以上是关于绪论的主要内容,如果未能解决你的问题,请参考以下文章