六GC调优工具
Posted dabokele
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了六GC调优工具相关的知识,希望对你有一定的参考价值。
在进行JVM GC性能调优之前,需要使用某些工具获取到当前应用的状态信息。
可以利用JVM运行时的一些原始数据来观察当时的GC性能。并且基于这些原始数据也衍生出一些经过分析统计后得到的指标。在原始数据中包含以下内容:
- 当前内存池的使用情况
- 当前内存池的容量
- 每次GC暂停的耗时
GC暂停的各阶段的耗时
基于这些内容分析统计得到的一些指标包括应用内存分配率,提升率等等。本章中主要讨论GC的原始数据,有关对原始数据的分析统计指标,将在下一章节讨论GC相关的性能问题时再作分析。
一、JMX API
从运行的JVM中获取GC相关信息的最基本的方法是使用标准JMX API。这是JVM向外提供的一个暴露出内部信息的接口。可以通过应用程序来访问这些API获取相关信息,也可使用JXM客户端。
目前最流行的两个JMX客户端是JConsole和JvisualVM。这两个工具都在标准JDK版本都有提供,可以在jdk的bin目录下找到。如果使用的是JDK-7u40及之后版本,还可以使用一个第三方工具Java Mission Control。
所有的JMX客户端都是单独运行一个应用,然后连接到目标JVM。目标JVM可以运行在本地,也可以运行在远程服务器上。如果客户端需要访问远程的JVM,则目标JVM需要设置允许远程JMX连接。可以通过以下参数来设置
java -Dcom.sun.management.jmxremote.port=5432 com.yourcompanyYourApp在上面这个示例中,JVM提供了一个5432端口供JMX连接。
下面两图中展示了使用JVisualVM和Java Mission Control通过JMX获取GC信息的示例。当JMX客户端连接到目标JVM后,选择MBeans标签,展开java.lang/GarbageCollector选项。

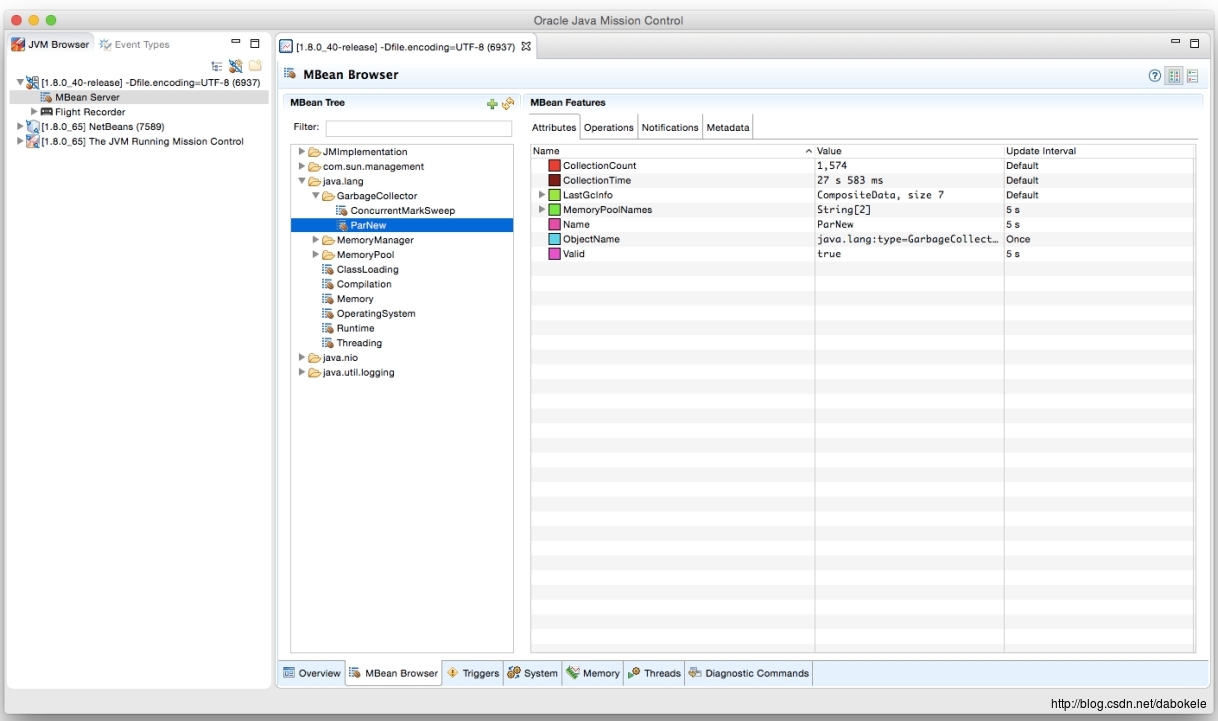
从上图中可以看到两个垃圾收集器,其中ParNew用于回收新生代空间,ConcurrentMarkSweep用于回收老年代空间。
JMX API中暴露出的每一个垃圾收集器都提供了以下信息:
- CollectionCount - 当前JVM运行起来后这个垃圾收集器工作的总次数
- CollectionTime - 这个垃圾收集器运行的总耗时。总耗时为所有GC事件所使用的实际时间(wall-clock time)
- LastGcInfo - 最近一次垃圾收集行为的详细信息。这个信息中包含了这次垃圾收集的耗时,开始时间和结束时间,以及各内存区域在GC前后的内存使用变化情况
- MemoryPoolNames - 当前垃圾收集器管理的内存池的名称
- Name - 当前垃圾收集器的名称
- ObjectName - 当前MBean的名称,由JMX规范定义
- Valid - 标识当前垃圾收集器在JVM中是否有效。在这里只显示了一个”true”
二、JVisualVM
JVisualVM通过一个VixualGC的插件在基本JMX客户端能提供的基础信息之外,还提供了一些额外的信息。通过它可以实时查看GC事件过程和不同JVM中不同内存区域的使用情况。
Visual GC插件常用的一个场景是,当需要对某个应用的性能进行监控和调优时,可以先在本地试运行该应用,然后监控运行中的这个应用。

在上图的左侧可以看到当前应用不同内存区域的实时使用情况,包括元数据区(Metaspace)或永久代(Permanent Generation),老年代(Old Generation),新生区(Eden Generation)和两个存活区(Survivor Spaces)。
在图片的右侧,最上面的两个部分与GC事件无关,展示的是JIT编译时间和类加载时间。接下来的六个部分展示了内存区域的历史使用情况,每个内存区域的GC次数,以及每个区域累积的GC耗时。还包括每个内存区域的当前大小,峰值使用情况以及最大容量等。
接下来展示的是新生代中对象的年龄。有关对象年龄的进一步监控,不在本章的讨论范围中。
与其他JMX工具相比,使用了VisualGC插件的JVisualVM客户端提供了更加丰富的JVM信息。所以,在可能的情况下,应该优先选择这个客户端工具。在接下来的Profilers章节中,也会进一步介绍JVisualVM的适用场景。
三、jstat
jstat也是标准JDK自带的一款工具。这是一款命令行工具,可以通过它获取到正在运行中的JVM的相关信息。通过jstat工具既可以连接本地也可连接远程JVM。通过jstat工具可以提供的常用信息包括以下这些,可以通过jstat -option命令获取
| option | Displays… |
|---|---|
| class | class loader的性能统计信息 |
| compiler | HotSopt Just-In-Time编译器的性能统计信息 |
| gc | heap上的gc统计信息 |
| gccapacity | 不同年代内存区域的使用情况统计信息 |
| gccause | 垃圾回收的汇总信息(这一点和-gcutil)类似,会展示最近一次垃圾回收事件的详细信息 |
| gcnew | 新生代的统计信息 |
| gcnewcapacity | 新生代的空间大小和内存使用情况 |
| gcold | 老年代和持久代的统计信息 |
| gcoldcapacity | 老年代的空间大小和内存使用情况 |
| gcpermcapacity | 持久代的空间大小和内存使用情况 |
| gcutil | 垃圾回收事件汇总 |
| printcompilationl | 垃圾回收事件汇总 |
使用这个工具可以快速的获取JVM当前健康状况,以及当前JVM垃圾回收性能是否符合预期。使用命令jstat -gc -t PID 1s,PID是需要分析的JVM的process ID。可以通过jps命令来获取JVM对应的PID。该命令会每秒返回一次GC的统计信息,内容如下所示
Timestamp S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
200.0 8448.0 8448.0 8448.0 0.0 67712.0 67712.0 169344.0 169344.0 21248.0 20534.3 3072.0 2807.7 34 0.720 658 133.684 134.404
201.0 8448.0 8448.0 8448.0 0.0 67712.0 67712.0 169344.0 169343.2 21248.0 20534.3 3072.0 2807.7 34 0.720 662 134.712 135.432
202.0 8448.0 8448.0 8102.5 0.0 67712.0 67598.5 169344.0 169343.6 21248.0 20534.3 3072.0 2807.7 34 0.720 667 135.840 136.559
203.0 8448.0 8448.0 8126.3 0.0 67712.0 67702.2 169344.0 169343.6 21248.0 20547.2 3072.0 2807.7 34 0.720 669 136.178 136.898
204.0 8448.0 8448.0 8126.3 0.0 67712.0 67702.2 169344.0 169343.6 21248.0 20547.2 3072.0 2807.7 34 0.720 669 136.178 136.898
205.0 8448.0 8448.0 8134.6 0.0 67712.0 67712.0 169344.0 169343.5 21248.0 20547.2 3072.0 2807.7 34 0.720 671 136.234 136.954
206.0 8448.0 8448.0 8134.6 0.0 67712.0 67712.0 169344.0 169343.5 21248.0 20547.2 3072.0 2807.7 34 0.720 671 136.234 136.954
207.0 8448.0 8448.0 8154.8 0.0 67712.0 67712.0 169344.0 169343.5 21248.0 20547.2 3072.0 2807.7 34 0.720 673 136.289 137.009
208.0 8448.0 8448.0 8154.8 0.0 67712.0 67712.0 169344.0 169343.5 21248.0 20547.2 3072.0 2807.7 34 0.720 673 136.289 137.009
上面这段输出内容中体现出的信息有,
- jstat工具是在JVM启动200秒后连接上的。可以从第一列的
Timestamp中看到,根据命令行中的参数,每一秒会打印一条信息 - 可以看到到200秒时,当前JVM发生了34次Young GC,发生了658次Full GC。分别由
YGC和FGC列表示 YGCT列表示Young GC的总耗时为0.720秒FGCT列表示Full GC的总耗时为133.684秒,看到这个数值,应该马上意识到该JVM在启动200秒的时间内,Full GC消耗了133秒,即约66%的时间都在进行Full GC接下来看下一行输出,
观察
FGC列可以看到,在这1秒的时间内,又发生了4次Full GC- 并且这4次Full GC的耗时也几乎为1秒
同时从
OC和OU列可以看到,OC代表的老年代总内存大小169344.0KB的空间,在回收后OU代表的老年代总内存的使用量为169343.2KB。与上一行相比,仅仅回收了800 bytes的内存仅仅从前两行中我们就可以看出该应用处在异常状况中,继续观察后面几行输出信息,可以发现这种异常状况并不是偶然发生的,反而是越来越严重。
当前JVM基本上已经无法正常工作了,因为90%的时间基本上都在进行垃圾回收。并且即使进行了Full GC,也几乎回收不到任何空间。事实上,这个应用在几分钟后抛出
java.lang.OutOfMemoryError: GC overhead limit exceeded错误,并终止了。从上面的示例中可以看出jstat工具的输出可以快速的总整体上来分析当前JVM的状况,通过jstat工具,可以快速的获取到以下重要信息
最后一列
GCT,与第一列Timestamp进行对比,可以看出当前应用GC总耗时占JVM运行时长的比例。如果GCT增长过快,则说明应用GC太频繁,当前应用可能处在异常状态。一般来说,如果GC时间超过总时间的10%,就需要引起注意了。YGC和FGC列的快速增长也同样说明应用异常,频繁的GC暂停会影响应用的吞吐量- 如果当进行Full GC后,
OU列的值几乎与OC列的值一致,说明本次GC并没有回收到多少空间,如果在一段时间内都是这样,也能说明应用异常
四、GC logs
通过GC日志可以获取JVM在GC时的详细信息。GC日志既可以直接在命令行输出,也可生成到指定的日志文件中。关于GC日志,可以由很多JVM参数来控制。例如,-XX:+PrintGCApplicationStoppedTime参数可以记录应用在每次GC事件中的暂停时间,-XX:+PrintReferenceGC参数可以记录回收了多少不同引用类型的引用。
下面还有一些GC日志相关的参数,例如
-XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PringGCDetails -Xloggc:<filename> 这些参数可以让JVM在每次GC时将GC的信息加上timestamp输出到日志文件中。日志文件中的具体内容取决于JVM使用的是哪种GC算法,下面这段日志信息是使用ParallelGC时生成的
199.879: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)],0.1473386 secs] [Times: user=0.43 sys=0.01, real=0.15 secs]
200.027: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)],0.1567794 secs] [Times: user=0.41 sys=0.00, real=0.16 secs]
200.184: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)],0.1621946 secs] [Times: user=0.43 sys=0.00, real=0.16 secs]
200.346: [Full GC (Ergonomics) [PSYoungGen: 64000K->63998K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)],0.1547695 secs] [Times: user=0.41 sys=0.00, real=0.15 secs]
200.502: [Full GC (Ergonomics) [PSYoungGen: 64000K->63999K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)],0.1563071 secs] [Times: user=0.42 sys=0.01, real=0.16 secs]
200.659: [Full GC (Ergonomics) [PSYoungGen: 64000K->63999K(74240K)] [ParOldGen: 169318K->169318K(169472K)] 233318K->233317K(243712K), [Metaspace: 20427K->20427K(1067008K)],0.1538778 secs] [Times: user=0.42 sys=0.00, real=0.16 secs]其他GC算法的输出日志在四、GC算法实现中已经分析过了,如果不了解的话,可以先看一下这篇博客。从上面这段输出日志中可以看到,
- 这段日志输出的是JVM启动后200秒左右的信息
- 在这780毫秒的实际内,JVM由于GC暂停了5次,这5次暂停都是Full GC导致的暂停。
- 暂停的总时间为777毫秒,几乎是应用运行时间的99.6%
同时,可以观察到老年代空间容量和消耗情况,在进行GC后整个老年代共169.472KB的空间被使用了169.318KB
从上面这段输出日志中我们可以知道这个应用运行状况不好,JVM几乎被垃圾回收给停止了,GC消耗了应用运行的99%的时间。并且Full GC也已经无法回收到多少内存空间了。这个应用在运行几分钟后,也抛出
java.lang.OutOfMemoryError: GC overhead limit exceeded的错误并终止了。在本例中,通过分析GC日志可以发现
应用的GC负载过高。GC暂停时间越长,应用的吞吐量越低。一般来说,GC暂停时间超过应用运行时间的10%时,该应用已经处于不正常状况了
- 单次暂停时间过长。单个暂停耗时越长,应用的延迟越显著。当应用的延迟性能要求应用的每次事务处理必须在1000毫秒内完成时,我们就要确保GC暂停时间不能超过1000毫秒
老年代内存使用达到极限。当发生几次Full GC后,老年代空间的内存使用仍然达到其容量极限时,我们可以知道老年代空间已经成为应用的瓶颈了。这可能是由于老年代空间分配不足,或者应用发生了内存泄漏。
GC日志可以提供给我们很多关于JVM的垃圾回收相关的详细信息。但是JVM会输出大量这种日志文件,并且日志文件并不是很直观。
五、GCViewer
面对海量并且不直观的GC日志文件时,可能最好的办法是自己实现一个解析GC日志文件,并且以图形的形式直观的进行展示。但是由于不同GC算法,GC日志文件格式和内容复杂,自己动手实现起来也很困难。GCViewer就是一款已有的解析GC日志文件,并以图形形式进行展示的工具。
GCViewer是一款开源的GC日志文件分析工具。Github上提供了详细描述,并列举了它可以分析的一些指标。接下来我们分析一下这款工具的一些常用方法。
使用GCViewer的第一步就是生成有用的GC日志文件。当有了GC日志文件之后,就可以使用GCViewer进行分析了,如下所示,

上图中展示了每个内存区域的容量以及使用情况,以及GC事件。堆内存的总使用量为图中的蓝色线条所示,每次GC事件的暂停时间由黑色的柱状图所示。
我们可以看到内存使用量快速上升,在1分钟时间内,几乎使用了全部的堆内存空间。由于内存空间不足,所以在接下来JVM频繁进行GC。
接下来我们再看看黑色的柱状图,可以看到GC得越来越频繁,在刚开始一段时间内还比较稀疏,后面已经越来越密集。最长的一次GC暂停时间长达1.4秒。
上图的右边区域有一个包含三个Tab页的显示盘。在Summary页统计的是堆内存的使用量和总量,GC暂停次数,以及吞吐量等信息。吞吐量表示的是应用运行时长占JVM启动总时间的比例。上图中表示实际吞吐量为6.28%,即有93.72%的时间都在进行GC。
Pause页如下所示,
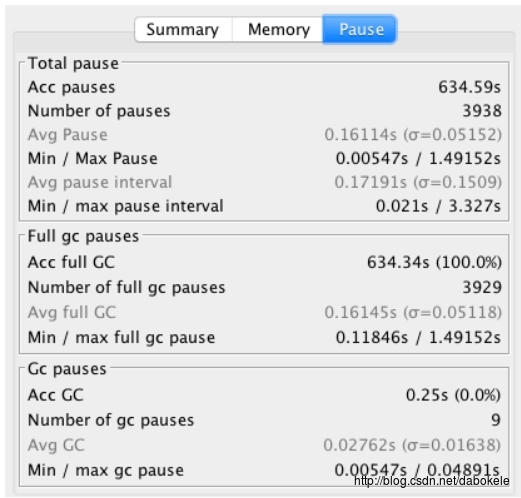
Pause页展示了GC暂停的总耗时,最小最大耗时,以及总耗时。
在主页面的Event details`页,可以看到更加详细的信息。

在这里可以看到日志中的重要GC事件的统计信息,包括minor gc和major gc,以及并发的非stop-the-world阶段。在这里,可以看到Full GC占了整个GC暂停的绝大多数,总共3929次的Full GC导致应用暂停了634秒。
通过使用GCViewer可以快速的从GC日志中分析出JVM是否正常。通过以下指标分析可以快速发现JVM异常:
- 低吞吐量。当应用吞吐量过低时,表示应用花了大部分时间在进行GC操作,一般来说,当吞吐量低于90%时,说明需要进行GC调优了
- 单次暂停时间过长。单个暂停耗时越长,应用的延迟越显著。当应用的延迟性能要求应用的每次事务处理必须在1000毫秒内完成时,我们就要确保GC暂停时间不能超过1000毫秒
老年代内存使用达到极限。当发生几次Full GC后,老年代空间的内存使用仍然达到其容量极限时,我们可以知道老年代空间已经成为应用的瓶颈了。这可能是由于老年代空间分配不足,或者应用发生了内存泄漏。
使用GCViewer可以以图形界面的形式快速分析GC日志文件。
六、Profiers
前面的分析工具提供的信息只是Profiers中的一部分,除此之外Profiers还提供了一些特有的GC相关指标。
需要注意的是,Profiers并不是在任何情况下都好用。在分析应用代码的CPU热点时,Profiers能取得很好的效果。但是在其他某些情况下,Profiers其实并不是很突出。
Profiers的性能开销很大,所以在前面的分析工具能够满足需要的情况下,Profiers并不是最好的选择。尤其是在分析产线应用时,最好不要使用Profiers。
但是当需要深入到应用的GC过程中,找出内存中存活的有哪些对象,哪些对象消耗了过多内存时,使用Profiers就很直观了。通过Profiers可以知道内存中各对象的实际情况。找到内存中消耗内存过多的对象后,就可以有针对性的对应用代码进行调整了。
在接下来的文章中,我们可以看到三种不同的对象分配分析器:hprof,JVisualVM和AProf。除此之外,还有一些商业的或者免费的其他分析器,主要功能基本上都差不多。
1、hprof
在JDK发行版本中提供了hprof工具。如果需要使用这一工具,需要在运行应用时使用如下参数
java -agentlib:hprof=heap=sites com.yourcompany.YourApplication 当应用退出时,会得到一个名为java.hprof.txt文件,打开这个文件,然后找到SITES BEGIN,提供的信息如下所示:
SITES BEGIN (ordered by live bytes) Tue Dec 8 11:16:15 2015
percent live alloc'ed stack class
rank self accum bytes objs bytes objs trace name
1 64.43% 4.43% 8370336 20121 27513408 66138 302116 int[]
2 3.26% 88.49% 482976 20124 1587696 66154 302104 java.util.ArrayList
3 1.76% 88.74% 241704 20121 1587312 66138 302115 eu.plumbr.demo.largeheap.ClonableClass0006
... cut for brevity ...
SITES END 从上面的信息中可以看出,第一行显示64.43%的对象都是Integer类型的数组,用编号302116进行区分。接下来搜索TRACE 302116,可以看到如下信息
TRACE 302116:
eu.plumbr.demo.largeheap.ClonableClass0006.<init>(GeneratorClass.java:11)
sun.reflect.GeneratedConstructorAccessor7.newInstance(<Unknown Source>:Unknown line)
sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
java.lang.reflect.Constructor.newInstance(Constructor.java:422)那么我们可以看到,这64.43%的整型数组对象,在ClonableClass0006类的构造函数中,第11行的位置生成。接下来就可以优惠这里的代码,用来减少GC压力。
2、Java VisualVM
前面已经提到过JVisualVM,在这里主要看一下它用在对象管理分析方面的功能。
当JVisualVM连接上正在运行中的JVM后,按照如下步骤操作:
(1)打开”Profile”->”Settings”,确保”Record allocations stack traces”被勾选
(2)点击”Memory”按钮开始内存分析
(3)让应用运行一段时间用以收集足够多的对象内存分配信息
(4)点击”Snapshot”按钮,会将收集到的对象分配信息以快照的形式进行保存
操作完成后,就可以看到如下的界面
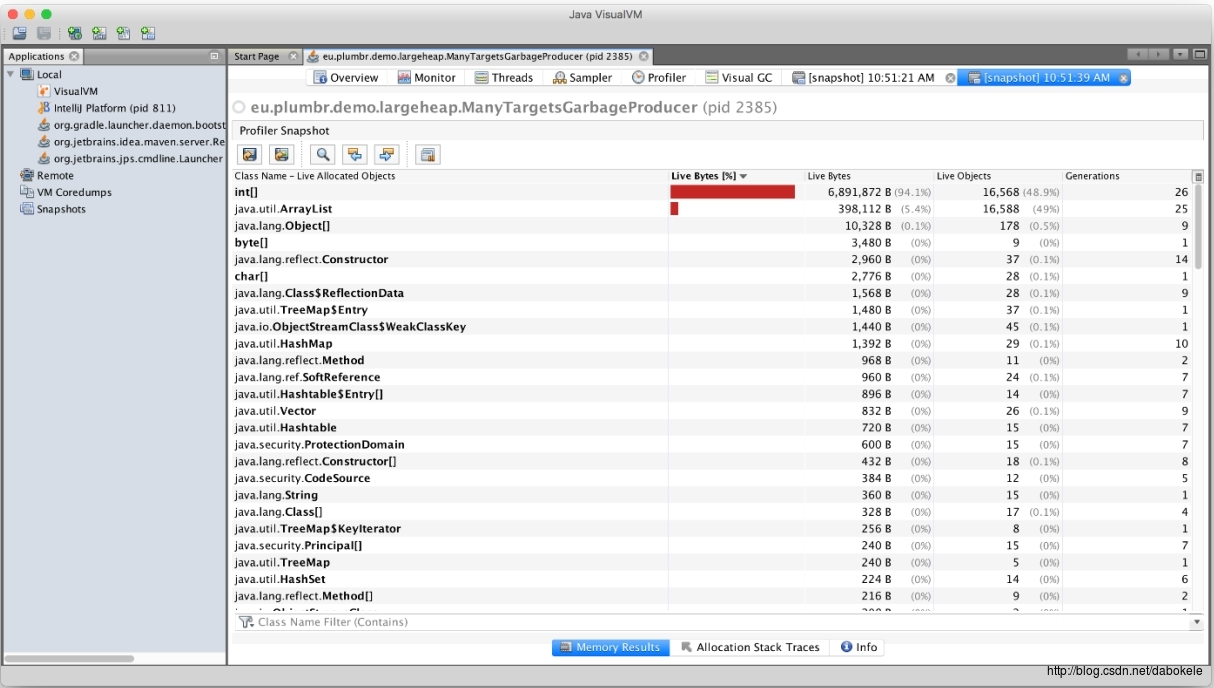
从上图中可以看到每个Class对应的对象个数。从第一行可以看到,内存中大部分空间都被分配给了int[]数组。通过层层展开选中的类,可以看到如下
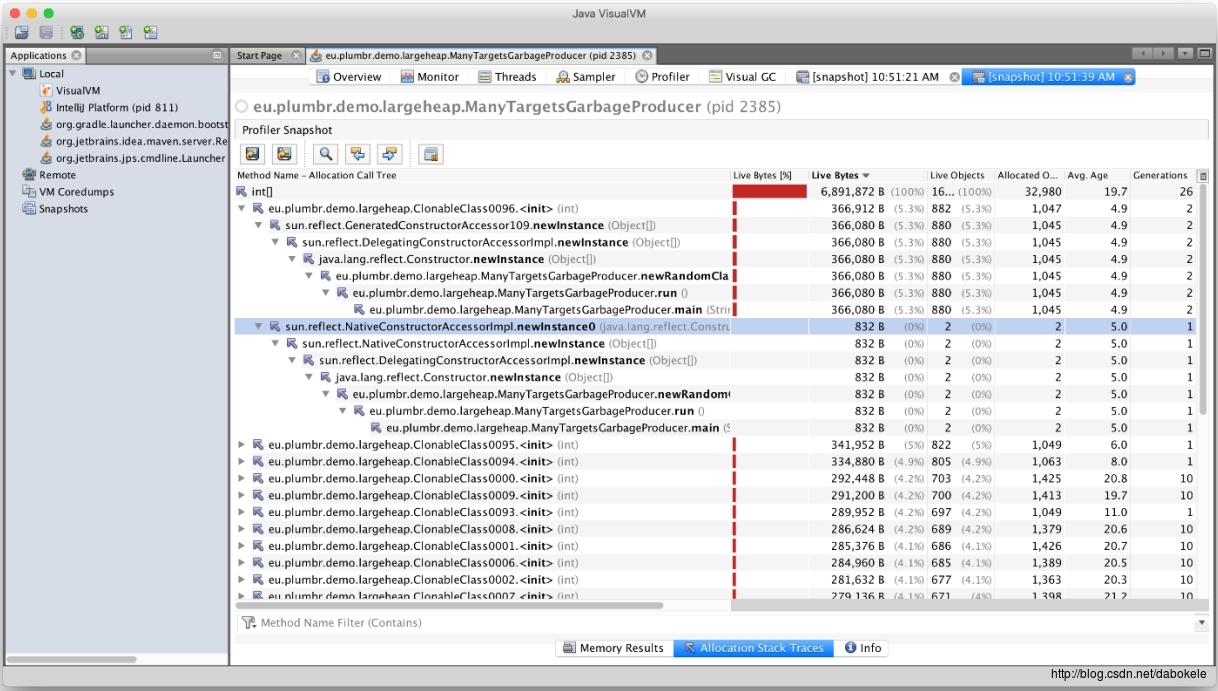
与hprof对比,JVisualVM更加直观。通过观察JVisualVM的结果,可以很快发现int[]数组消耗的内存最多,并且很快能够定位到生成对象的代码。
3、AProf
最后,我们在看一下由Devexperts提供的AProf工具。AProf是一款用于分析内存分配状况的Java工具。
使用AProf工具分析应用,需要使用如下命令运行应用,
java -javaagent:/path-to/aprof.jar com.yourcompany.YourApplication 运行该应用后,可以在指定路径下看到一个aprof.txt文件。这个文件每分钟更新一次,其中内容形式如下所示:
================================================================================================================
TOTAL allocation dump for 91,289 ms (0h01m31s)
Allocated 1,769,670,584 bytes in 24,868,088 objects of 425 classes in 2,127 locations
================================================================================================================
Top allocation-inducing locations with the data types allocated from them
----------------------------------------------------------------------------------------------------------------
eu.plumbr.demo.largeheap.ManyTargetsGarbageProducer.newRandomClassObject: 1,423,675,776 (80.44%) bytes in 17,113,721 (68.81%) objects (avg size 83 bytes)
int[]: 711,322,976 (40.19%) bytes in 1,709,911 (6.87%) objects (avg size 416 bytes)
char[]: 369,550,816 (20.88%) bytes in 5,132,759 (20.63%) objects (avg size 72 bytes)
java.lang.reflect.Constructor: 136,800,000 (7.73%) bytes in 1,710,000 (6.87%) objects (avg size 80 bytes)
java.lang.Object[]: 41,079,872 (2.32%) bytes in 1,710,712 (6.87%) objects (avg size 24 bytes)
java.lang.String: 41,063,496 (2.32%) bytes in 1,710,979 (6.88%) objects (avg size 24 bytes)
java.util.ArrayList: 41,050,680 (2.31%) bytes in 1,710,445 (6.87%) objects (avg size 24 bytes)
... cut for brevity ... 在上面的输出信息中,按照对象的大小依次输出相关信息。第一行可以看到使用内存的80.44%,以及全部对象的68.81%都在ManyTargetsGarbageProducer.newRandomClassObject方法中被分配出去。除此之外,大概有40.19%的内存空间被int[]数组使用。
继续浏览该文件可以看到,如下信息,
Top allocated data types with reverse location traces
--------------------------------------------------------------------------------------------------------
int[]: 725,306,304 (40.98%) bytes in 1,954,234 (7.85%) objects (avg size 371 bytes)
eu.plumbr.demo.largeheap.ClonableClass0006.: 38,357,696 (2.16%) bytes in 92,206 (0.37%) objects (avg size 416 bytes)
java.lang.reflect.Constructor.newInstance: 38,357,696 (2.16%) bytes in 92,206 (0.37%) objects (avg size 416 bytes)
eu.plumbr.demo.largeheap.ManyTargetsGarbageProducer.newRandomClassObject: 38,357,280 (2.16%) bytes in 92,205 (0.37%) objects (avg size 416 bytes)
java.lang.reflect.Constructor.newInstance: 416 (0.00%) bytes in 1 (0.00%) objects (avg size 416 bytes)
... cut for brevity ... 从这里又可以看到,这个消耗内存最多的int[]数组,是在CloableClass0006类的构造函数中被创建的。
所以,和其他工具相类似,AProf分析了对象的分配以及生成位置,可以根据这些信息定位到应用代码中消耗内存最多的地方。AProf是一个比较好用的工具,使用起来很方便,提供的信息也很全面,并且是开源的,相比于其他工具来说,对性能的消耗也最少。
以上是关于六GC调优工具的主要内容,如果未能解决你的问题,请参考以下文章