Zookeeper相关
Posted 买糖买板栗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper相关相关的知识,希望对你有一定的参考价值。
Zookeeper有四种类型的znode:
- PERSISTENT-持久化目录节点 :客户端与zookeeper断开连接后,该节点依旧存在
- PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点 :客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
- EPHEMERAL-临时目录节点 :客户端与zookeeper断开连接后,该节点被删除
- EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点 :客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
Zookeeper 的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和 leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
直接使用Zookeeper原生API的人并不多,因为:
- 1)连接的创建是异步的,需要开发人员自行编码实现等待
- 2)连接没有超时自动的重连机制
- 3)Zookeeper本身没提供序列化机制,需要开发人员自行指定,从而实现数据的序列化和反序列化
- 4)Watcher注册一次只会生效一次,需要不断的重复注册
- 5)Watcher的使用方式不符合java本身的术语,如果采用监听器方式,更容易理解
- 6)不支持递归创建树形节点
消息广播:
在消息广播的过程中,leader服务器会为每一个follower服务器都各自分配一个单独的队列,然后将需要广播的事务proposal依次放入这些队列中去,并且根据FIFO策略进行消息发送。每一个follower服务器在接受到这个事务proposal后,都会首先将其以事务日志的形式写入到本地磁盘中去,并且在成功写入后反馈给leader服务器一个ack响应。当leader服务器收到超过半数follower的ack响应后,就会广播一个commit消息给所有的follower服务器以通知其进行事务提交,同时leader自身也会完成对事务的提交,而每一个follower服务器在收到commit消息后,也会完成对事务的提交
崩溃恢复:
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
- 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
- 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟
zookeeper的替代:etcd
ZAB协议的实现ZooKeeper(paxos算法)
etcd内部采用raft协议作为一致性算法
raft和zk都选择了cp

7 张图讲清楚ZooKeeper分布式锁实现原理



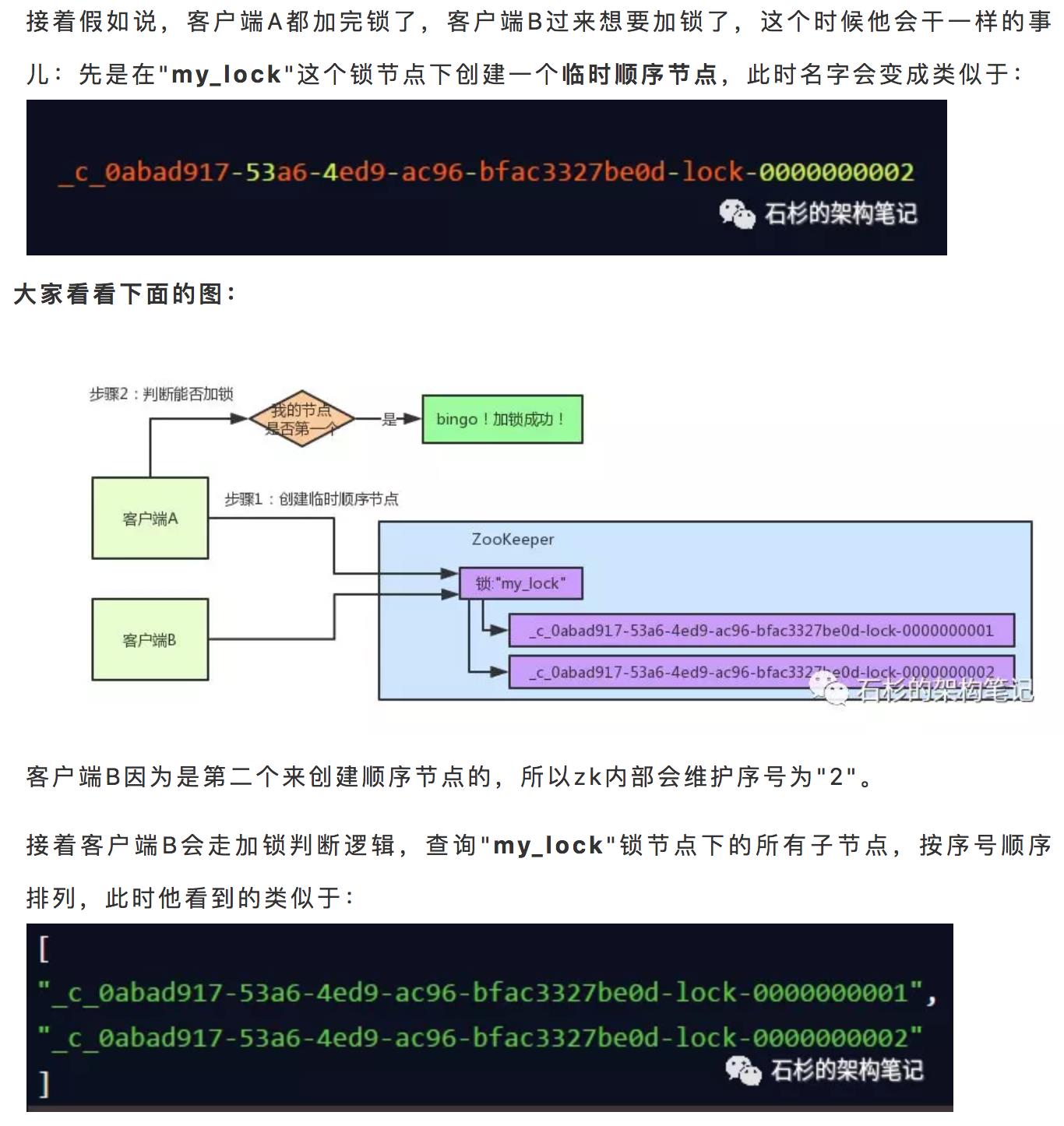


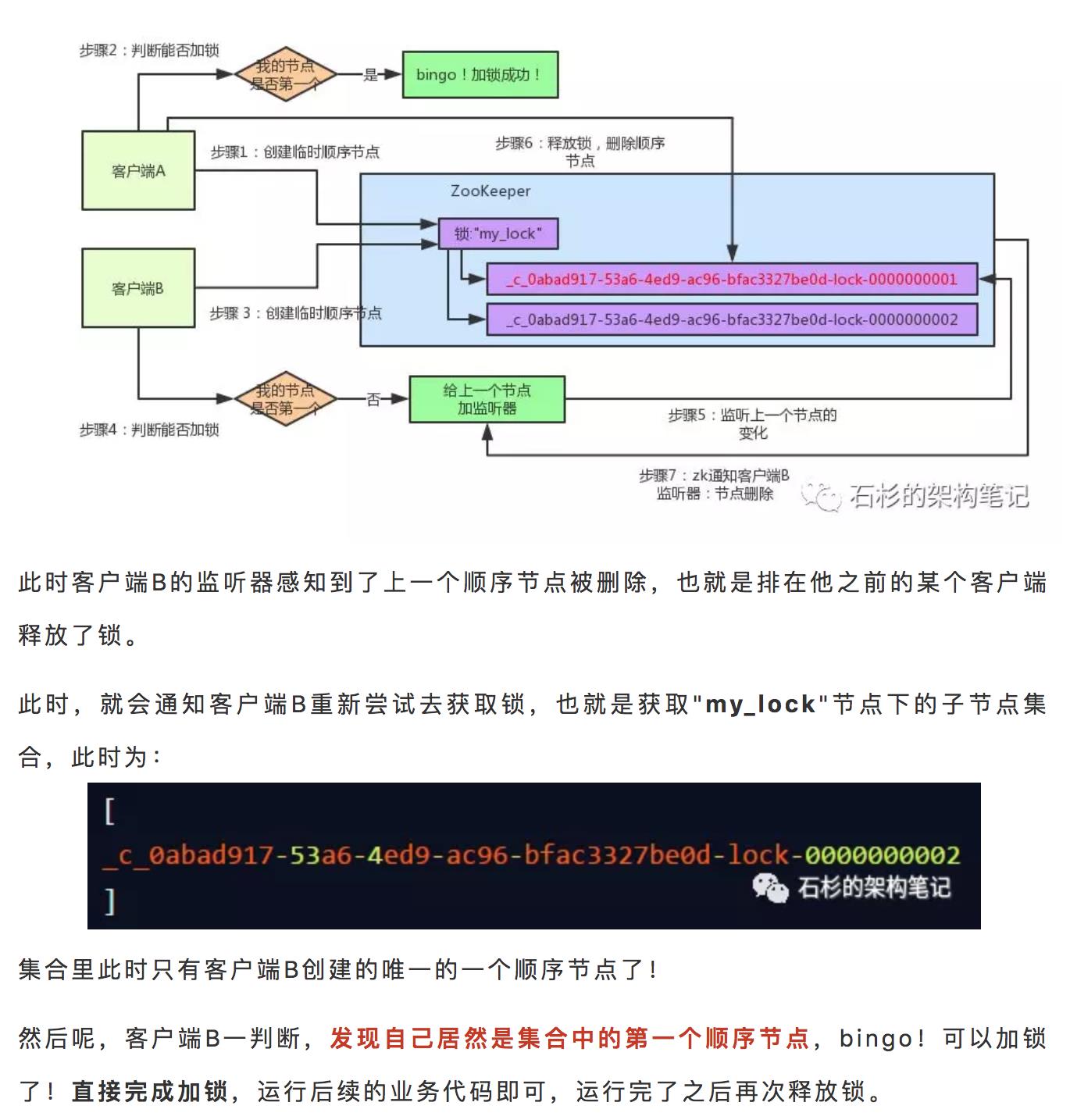

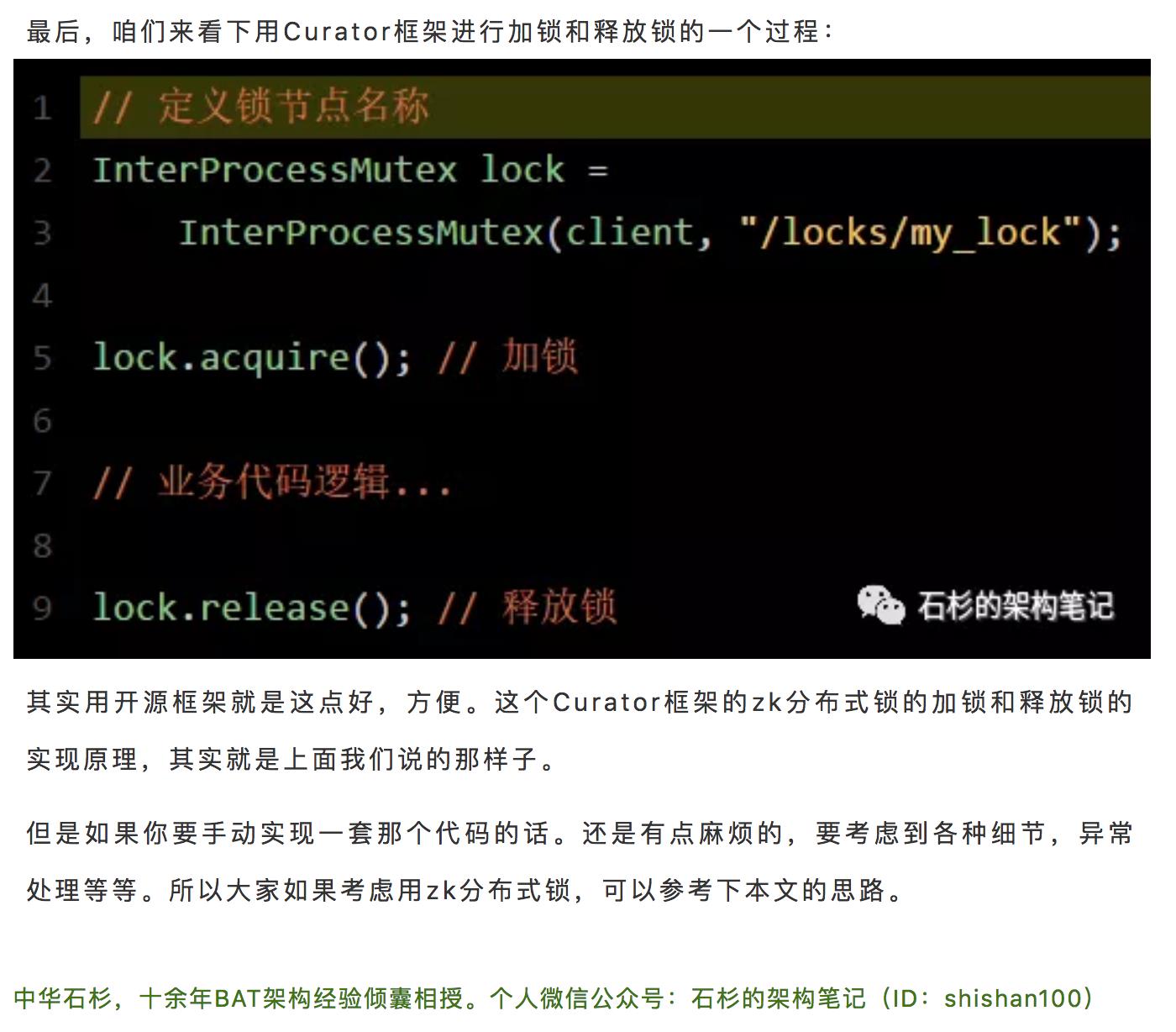
中华石杉,十余年BAT架构经验倾囊相授。个人微信公众号:石杉的架构笔记(ID:shishan100)
以上是关于Zookeeper相关的主要内容,如果未能解决你的问题,请参考以下文章