深度讲解微服务架构中的负载均衡算法
Posted 愉悦滴帮主)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度讲解微服务架构中的负载均衡算法相关的知识,希望对你有一定的参考价值。
负载均衡
前身
面对大量用户访问、高并发请求,海量数据,可以使用高性能的服务器、大型数据库,存储设备,高性能Web服务器,采用高效率的编程语言比如(Go,Scala)等,当单机容量达到极限时,我们需要考虑业务拆分和分布式部署,来解决大型网站访问量大,并发量高,海量数据的问题。
从单机网站到分布式网站,解决访问统一很重要的区别是业务拆分和分布式部署,将应用拆分后,部署到不同的机器上,实现大规模分布式系统。分布式和业务拆分解决了,从集中到分布的问题,但是每个部署的独立业务还存在单点的问题和访问统一入口问题,为解决单点故障,我们可以采取冗余的方式。将相同的应用部署到多台机器上。入口问题,我们可以在集群前面增加负载均衡设备,实现流量分发。
概述
负载均衡(Load Balance),指由多台服务器以对称的方式组成一个服务器集合,每台服务器都具有等级的地位,都可以单独对外提供服务而无须其他服务器的辅助。
通过某种负载分担技术,将外部发送来的请求均匀分配到对称结构中的某一台服务器上,而接受到请求的服务器独立地回应客户的请求。
负载均衡能够平均分配客户请求都服务器阵列,借此提供快速获取重要数据,解决大量并发访问服务问题,这种集群技术可以用最少的投资获得接近于大型主机的性能。
负载均衡方式
软件负载均衡:nginx、LVS、HAProxy
服务器端负载均衡和客户端负载均衡
a、服务器端负载均衡:例如Nginx,通过Nginx进行负载均衡,先发送请求,然后通过负载均衡算法,在多个服务器之间选择一个进行访问;即在服务器端再进行负载均衡算法分配。
b、客户端负载均衡:例如spring cloud中的ribbon,客户端会有一个服务器地址列表,在发送请求前通过负载均衡算法选择一个服务器,然后进行访问,这是客户端负载均衡;即在客户端就进行负载均衡算法分配。
硬件负载均衡: Array、F5
负载均衡算法
1. 加权随机算法
我们首先创建ServerIps这个类,来模拟分布式系统下提供的所有服务。
/**
* 模拟服务器集群
*/
public class ServerIps
//正常服务
public static final List<String> LIST = Arrays.asList(
"192.168.0.1",
"192.168.0.2",
"192.168.0.3",
"192.168.0.4",
"192.168.0.5",
"192.168.0.6",
"192.168.0.7",
"192.168.0.8",
"192.168.0.9",
"192.168.0.10"
);
//权重服务
public static final Map<String, Integer> WEIGHT_MAP = new HashMap<>();
//初始化
static
WEIGHT_MAP.put("192.168.0.1", 2);
WEIGHT_MAP.put("192.168.0.2", 8);
WEIGHT_MAP.put("192.168.0.3", 1);
WEIGHT_MAP.put("192.168.0.4", 9);
WEIGHT_MAP.put("192.168.0.5", 3);
WEIGHT_MAP.put("192.168.0.6", 7);
WEIGHT_MAP.put("192.168.0.7", 4);
WEIGHT_MAP.put("192.168.0.8", 6);
WEIGHT_MAP.put("192.168.0.9", 2);
WEIGHT_MAP.put("192.168.0.10", 8);
1.1 随机算法
通过随机数来随机的访问服务。
/**
* 随机算法
*/
public class Random
/**
* 算法核心逻辑
*
* @return
*/
private static String getServer()
java.util.Random random = new java.util.Random();
int pos = random.nextInt(ServerIps.LIST.size());
return ServerIps.LIST.get(pos);
/**
* 测试方法
*
* @param args
*/
public static void main(String[] args)
for (int i = 0; i < 10; i++)
System.out.println(getServer());
1.2 加权随机算法
我们通过Map数据结构来模拟权重,比如192.168.1.1这个服务的权重就是<192.168.1.1,8>。所以我们可以遍历每个服务的权重,并将其存入数组中,然后去随机访问这个数组的服务。
但是这个算法有缺点:就是当权重配的很大的时候,比如500,甚至五万就会导致这个数组很大。数组非常大,对我们服务器来说会占内存非常大,甚至会内存溢出。
/**
* 权重随机算法
*/
public class RandomWeight
/**
* 算法核心逻辑
*
* @return
*/
private static String getServer()
List<String> ips = new ArrayList<>();
for (String ip : ServerIps.WEIGHT_MAP.keySet())
Integer weight = ServerIps.WEIGHT_MAP.get(ip);
for (int i = 0; i < weight; i++)
ips.add(ip);
java.util.Random random = new java.util.Random();
int pos = random.nextInt(ips.size());
return ips.get(pos);
/**
* 测试方法
*
* @param args
*/
public static void main(String[] args)
for (int i = 0; i < 10; i++)
System.out.println(getServer());
1.3 优化加权随机算法
原理:累加每个元素的权重A(1)-B(3)-C(6)-D(10),则4个元素的的权重管辖区间分别为[0,1)、[1,3)、[3,6)、[6,10)。然后随机出一个[0,10)之间的随机数。落在哪个区间,则该区间之后的元素即为按权重命中的元素。
/**
* 权重升级算法
*/
public class UpRandomWeight
/**
* 算法核心逻辑
*
* @return
*/
private static String getServer()
int totalWeight = 0;
for (Integer weight : ServerIps.WEIGHT_MAP.values())
totalWeight += weight;
int offset = new java.util.Random().nextInt(totalWeight);
for (String ip : ServerIps.WEIGHT_MAP.keySet())
Integer weight = ServerIps.WEIGHT_MAP.get(ip);
if (offset < weight)
return ip;
offset = offset - weight;
return null;
/**
* 测试方法
*
* @param args
*/
public static void main(String[] args)
for (int i = 0; i < 10; i++)
System.out.println(getServer());
2. 加权轮询算法
2.1 轮询算法
轮询(Polling)是一种CPU决策如何提供周边设备服务的方式,又称“程控输入输出”(Programmed I/O)。轮询法的概念是:由CPU定时发出询问,依序询问每一个周边设备是否需要其服务,有即给予服务,服务结束后再问下一个周边,接着不断周而复始。也就是说在我们的场景中就是给定一组服务器列表,依次的将每一个进来的请求轮流的分配给列表中的每一台服务器来实现负载均衡。
- 优点:实现容易,每台服务器请求数相同(好像也就这一个优点了)
- 确定:效率偏低,无法满足服务器配置不同的情况(说好的能者多劳呢)
/**
* 轮询算法
*/
public class Robin
private static Integer pos = 0;
/**
* 算法核心逻辑
*
* @return
*/
private static String getServer()
if (pos > ServerIps.LIST.size())
pos = 0;
String ip = ServerIps.LIST.get(pos);
pos++;
return ip;
/**
* 测试方法
*
* @param args
*/
public static void main(String[] args)
for (int i = 0; i < 10; i++)
System.out.println(getServer());
2.1 加权轮询算法
基于上面简单轮询所带来的问题,就有了轮询的变种加权轮询。
所谓的加权轮询也就是在配置服务器列表时,给每一台服务器配置一个权重值。 举个例子:现在有3台服务器(A:3)(B:2)(C:1),数字分别代表它们的权重值,数字越大表示所能承受的压力越大。将3台服务器的权重值相加3+2+1=6,也就是说现在每6个请求进来其中会有3个分配个A,2个分配个B,剩下的一个分配给C,依次循环A-A-A-B-B-C-A-A-A-B-B-C-A.
- 优点:根据权重,可将性能更优越的服务器分配更多的请求数
- 缺点:因为是按顺序依次轮询将请求分配给服务器,所以权重大的服务器会在单位时间内分配到权重比例的请求数,这并不是一种均匀的分配方法。
原理:假设客户端发送一个请求,requestID可能是一个很大的数或其他十六进制的数字等等,我们对这个请求的requestID进行取余操作保证结果散落在【0,权重总和】之间。我们模拟requestID请求类Sequence ,每次请求num++,来保证轮询。
/**
* 模拟requestID请求类
*/
public class Sequence
public static Integer num = 0;
public static Integer getAndIncrement()
return num++;
public class RobinWeight
/**
* 算法核心逻辑
*
* @return
*/
private static String getServer()
int totalWeight = 0;
for (Integer weight : ServerIps.WEIGHT_MAP.values())
totalWeight += weight;
Integer request = Sequence.getAndIncrement();
int offset = request%totalWeight;
for (String ip : ServerIps.WEIGHT_MAP.keySet())
Integer weight = ServerIps.WEIGHT_MAP.get(ip);
if (offset < weight)
return ip;
offset = offset - weight;
return null;
/**
* 测试方法
*
* @param args
*/
public static void main(String[] args)
for (int i = 0; i < 10; i++)
System.out.println(getServer());
打印结果:AAAAABBBCC
3. 平滑加权轮询算法
从上述打印结果AAAAABBBCC可以分析出不足点,假设A服务的权重是50,那么按照上述加权轮询算法客户端前50次的请求都访问的A服务。这样会造成A服务压力过大的这个问题。我们期望客户端请求的服务更散列一点,例如:AABCAACABBC类似于这样的形式。
算法步骤:
- 首先每个节点分别有CurrentWeight(当前权重值),EffectiveWeight(有效权重值),Weight(配置权重值)三个权重字段, 其中Weight即用户配置的权重值,EffectiveWeight初始为取Weight值,在实际运行中会根据服务器的失败情况所相应的增减,CurrentWeight即当前服务器权重值,初始取EffectiveWeight值
- 在选择服务器节点时,每次取CurrentWeight最大的一项,获取到之后再将该节点的CurrentWeight值改为(CurrentWeight=CurrentWeight-total)即,当前权重等于当前权重减去总权重,而总权重又是所有节点的有效权重值相加。
计算过程如下,示例权重:A(5)-B(1)-C(1)

代码如下:
/**
* 平滑加权算法
*/
public class UpRobinWeight
private static Map<String, Weight> weightMap = new HashMap<>();
/**
* 算法核心逻辑
*
* @return
*/
private static String getServer()
//计算总权重
int totalWeight = 0;
for (Integer weight : ServerIps.WEIGHT_MAP.values())
totalWeight += weight;
//初始化map
if (weightMap.isEmpty())
for (String ip : ServerIps.WEIGHT_MAP.keySet())
Integer w = ServerIps.WEIGHT_MAP.get(ip);
weightMap.put(ip, new Weight(ip, w, w));
//找出最大weight
Weight maxCurrentWeight = null;
for (Weight weight : weightMap.values())
if (maxCurrentWeight == null || maxCurrentWeight.getCurrentWeight() < weight.getCurrentWeight())
maxCurrentWeight = weight;
//(CurrentWeight=CurrentWeight-total)
maxCurrentWeight.setCurrentWeight(maxCurrentWeight.getCurrentWeight() - totalWeight);
//所有节点的有效权重值相加
for (Weight weight : weightMap.values())
weight.setCurrentWeight(weight.getCurrentWeight() + weight.getWeight());
return maxCurrentWeight.getIp();
/**
* 测试方法
*
* @param args
*/
public static void main(String[] args)
for (int i = 0; i < 10; i++)
System.out.println(getServer());
4. 一致性哈希算法
服务器集群接收到一次请求调用时,可以根据请求的信息,比如客户端的ip地址,或请求路径与请求参数等信息进行哈希,可以得出一个哈希值,特点是对于相同的ip地址,或请求路径和请求参数哈希出来的值是一样的,只要能再增加一个算法,能够把这个哈希值映射成一个服务端ip地址,就可以使相同的请求(相同的ip地址,或请求路径和请求参数)落到同一服务器上。
因为客户端发起的请求情况使无穷无尽的(客户端地址不同,请求参数不同等等),所以对应的哈希也是无穷大的,所以我们不可能把所有的哈希值都进行映射到服务端ip上,所以这里就需要用到哈希环。如下图
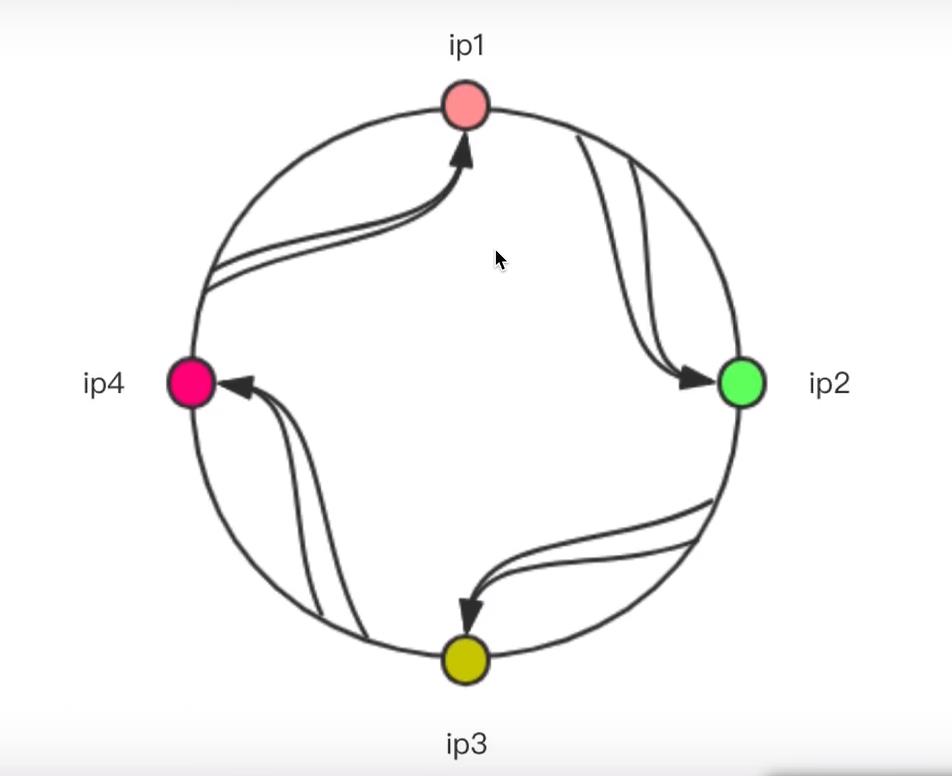
哈希值如果需要(落在)ip1和ip2之间的,则应该选择ip2作为结果
哈希值如果需要(落在)ip2和ip3之间的,则应该选择ip3作为结果
哈希值如果需要(落在)ip3和ip4之间的,则应该选择ip4作为结果
哈希值如果需要(落在)ip4和ip1之间的,则应该选择ip1作为结果
上面的这种情况是比较均匀情况,如果出现ip4服务器宕机,不存在了,那就是这样了,如下图:
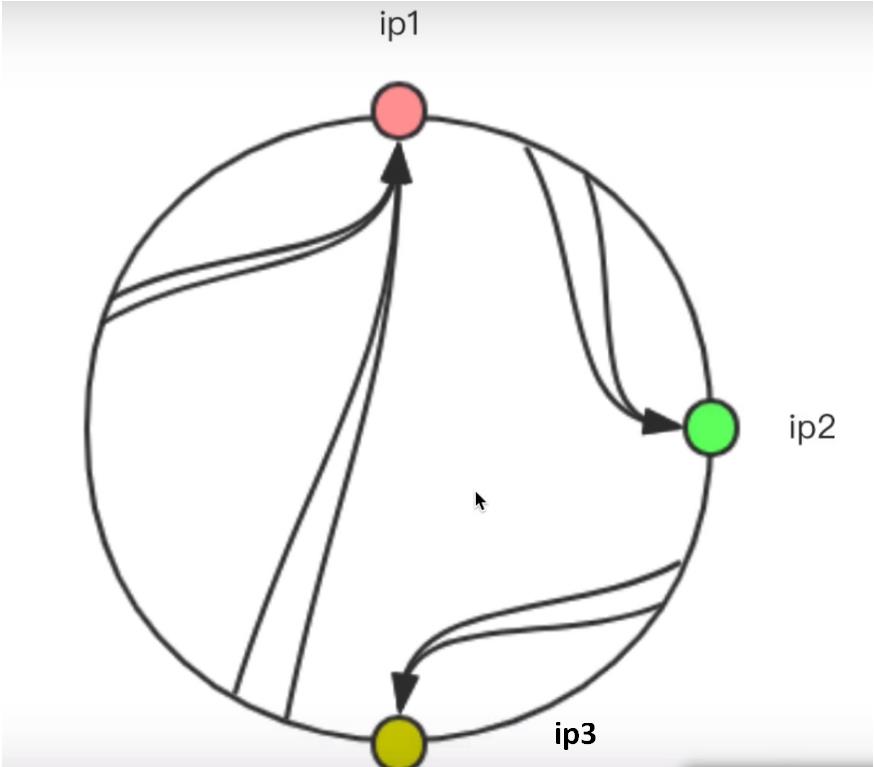
会发现,ip3和ip2直接的范围是比较大的,会有更多的请求落在ip1,这时“不公平”的,解决这个问题需要加入虚拟节点,比如:
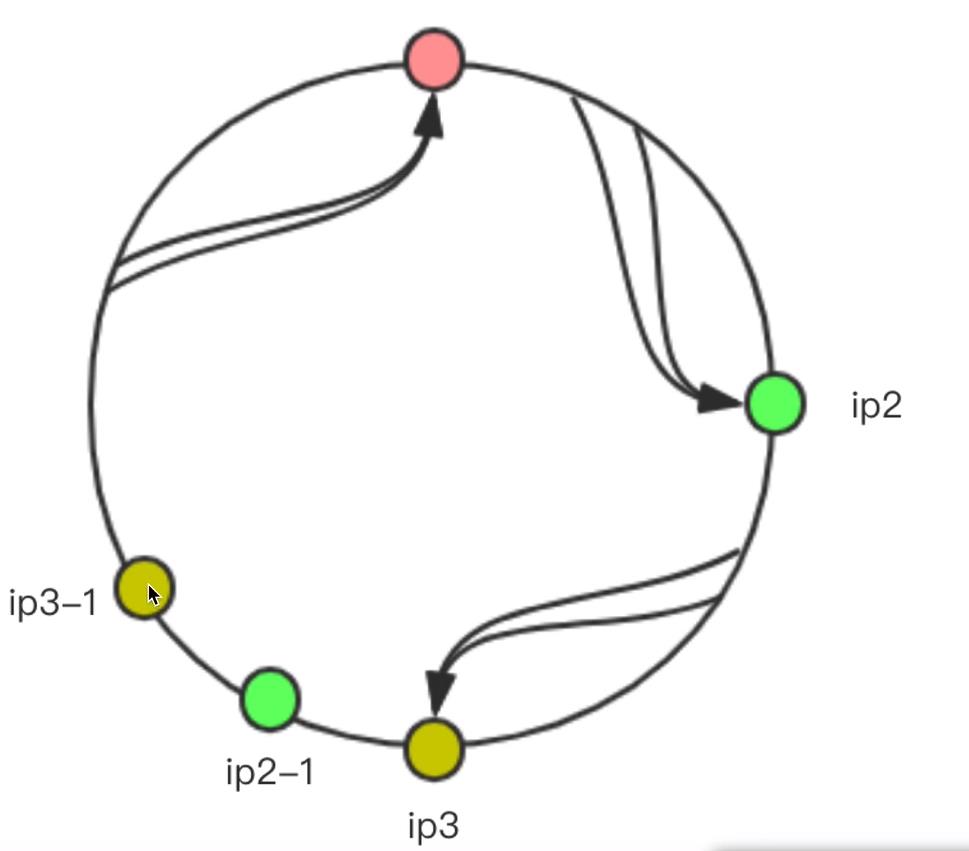
其中ip2-1,ip3-1就是虚拟节点,并不能处理节点,而是等同于对应的ip2和ip3服务器。这样便保证了请求能够公平的落在ip1,ip2,ip3这三个服务端。
实际上,这只是处理这种不均衡性的一种思路,实际上就算哈希环本身不是均衡的,你也可以增加更多的虚拟界定啊来使这个哈希环更加平滑,比如:
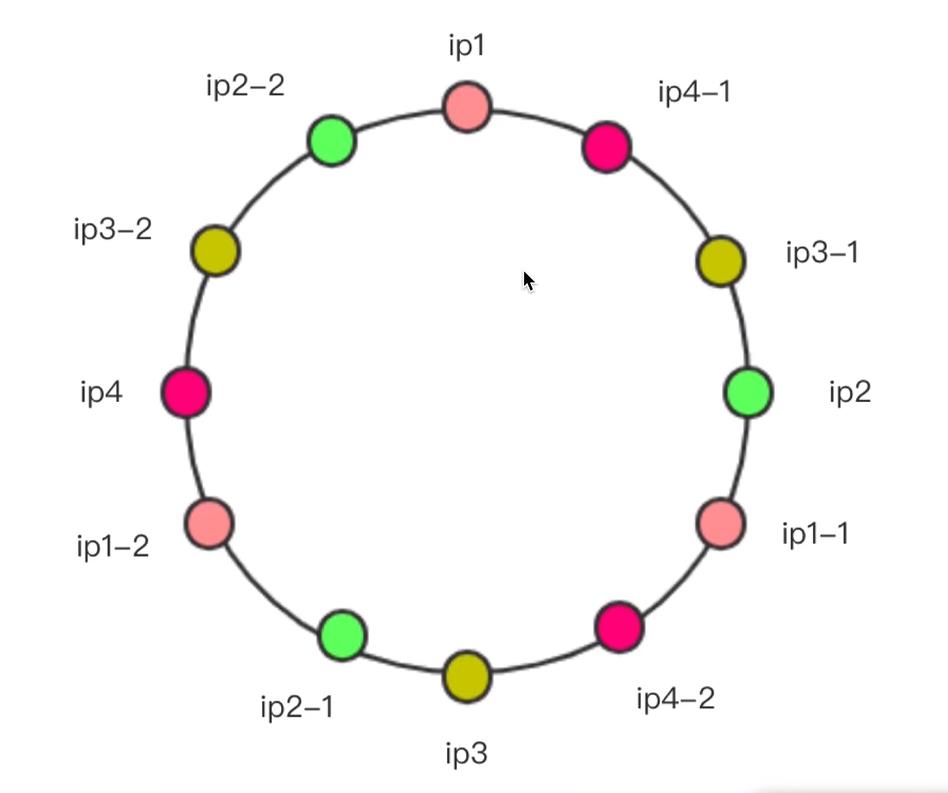
这个哈希环也是公平的,并且只有ip1,2,3,4是实际的服务器ip,其他的都是虚拟ip。
那么我们怎么来实现呢?
对于我们的服务器端ip地址,我们肯定知道总共有多少个,需要多少个虚拟节点也有我们自己空制,虚拟节点越多则流量越均衡,另外哈希算法也是很关键的,哈希算法越散列则表示流量也将越均衡。
实现:
从编程的角度,我们可以将服务器的值(角度或者hash值)保存在一个有序列表中,这里我们用TreeMap来存储,然后去搜索这个列表,找到第一个它的值大于或者等于key值的服务器,如果找不到,就去去列表的第一个服务器。代码如下:
/**
* 一致性哈希算法
*/
public class ConsistentHash
//表示每个真实节点生成多少个虚拟节点
private static final int VIRTUAL_NODES = 160;
//储存所有的节点
private static TreeMap<Integer, String> virtualNodes = new TreeMap<>();
//初始化TreeMap
static
for (String ip : ServerIps.LIST)
for (int i = 0; i < VIRTUAL_NODES; i++)
int hash = getHash(ip + "VN" + i);
virtualNodes.put(hash, ip);
/**
* hash算法
*
* @param str
* @return
*/
private static int getHash(String str)
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
//如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
/**
* 算法核心逻辑
* 找到第一个它的值大于或者等于key值的服务器,如果找不到,就去去列表的第一个服务器。
*
* @return
*/
private static String getServer(String client)
int hash = getHash(client);
SortedMap<Integer, String> sortedMap = virtualNodes.tailMap(hash);
Integer minHash = null;
if (sortedMap == null)
minHash = virtualNodes.firstKey();
else
minHash = sortedMap.firstKey();
return sortedMap.get(minHash);
/**
* 测试方法
*
* @param args
*/
public static void main(String[] args)
for (int i = 0; i < 10; i++)
System.out.println(getServer("client" + i));
5. 最小活跃数算法
最小活跃数负载均衡:每个服务提供者对应一个活跃数 active。初始情况下,所有服务提供者活跃数均为0。每收到一个请求,活跃数加1,完成请求后则将活跃数减1。在服务运行一段时间后,性能好的服务提供者处理请求的速度更快,因此活跃数下降的也越快,此时这样的服务提供者能够优先获取到新的服务请求、这就是最小活跃数负载均衡算法的基本思想。除了最小活跃数,LeastActiveLoadBalance 在实现上还引入了权重值;在一个服务提供者集群中,有两个性能优异的服务提供者。某一时刻它们的活跃数相同,此时 Dubbo 会根据它们的权重去分配请求,权重越大,获取到新请求的概率就越大。如果两个服务提供者权重相同,此时随机选择一个即可;
优点:可以根据provider实时运行情况动态地调节,适合所有provider性能都差不多的情况。
缺点:对于各provider性能差别较大的情况,(如本次比赛,性能1:2:3),性能最差的provider往往活跃数最小,会将较多的请求发送到small服务器上。
/**
* 最小活跃数算法
*/
public class LeastActive
/**
* 算法核心逻辑
*
* @return
*/
private static String getServer()
//1.找活跃数最小的活跃数(有可能有多台)
Map<String, Integer> sortMap = new HashMap<>();
List<Integer> sort = ServerIps.ACTIVITY_LIST.values().stream().sorted().collect(Collectors.toList());
for (String ip : ServerIps.ACTIVITY_LIST.keySet())
Integer active = ServerIps.ACTIVITY_LIST.get(ip);
if (sort.get(0).equals(active))
sortMap.put(ip, active);
//2.如果有多台,可以通过随机或轮询等算法在多台服务找出一台。
//这里用的随机算法
Random random = new Random();
int pos = random.nextInt(sortMap.size());
Map.Entry<String, Integer> entry = sortMap.entrySet().stream().collect(Collectors.toList()).get(pos);
return entry.getKey();
/**
* 测试方法
*
* @param args
*/
public static void main(String[] args)
for (int i = 0; i < 10; i++)
System.out.println(getServer());
以上是关于深度讲解微服务架构中的负载均衡算法的主要内容,如果未能解决你的问题,请参考以下文章