influxDB系列
Posted 牛顿的小脑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了influxDB系列相关的知识,希望对你有一定的参考价值。
这个是github上面一个人总结的influxDB的操作手册,还不错:https://xtutu.gitbooks.io/influxdb-handbook/content/zeng.html
1. influxDB是什么呢?
InfluxDB 是一个开源分布式时序、事件和指标数据库。
使用 Go 语言编写,无需外部依赖。其设计目标是实现分布式和水平伸缩扩展。
2. 怎么使用influxDB呢?
类比的方法学习! ---》 nfluxDB提供类SQL语法, 所以熟悉sql 语法的话,就可以类比学习。
向“表”中插入数据(influx 中不叫做表,叫做 measurement --度量值/测量值)
insert posts,userid=2,cid=3 content="helloworld3",internal="hah",external="zzzzzzhehhe" 1480000000000000000
这条插入数据的语句的意思:语法
insert posts 这里 posts 相当于表名称。
,userid=2,cid=3 这部分相当于 索引 (show tag keys from posts 的时候,可以看到 这个posts 表的索引有两个 cid 和userid)
content="helloworld3",internal="hah",external="zzzzzzzhehe" 1480000000000000000 前面用一个 空格隔开,表示开始向这个表的插入记录了,可以有任意个数的“字段”
像我们这条语句中就是有3个字段, 最后黄色的部分是时间戳(可以不写,会自动插入的, 如果有写的话,就会插入我们自己定义的时间戳)。

下面我演示一下从头开始新建一个数据库,建表和插入数据。
1、创建数据库
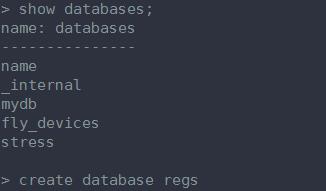
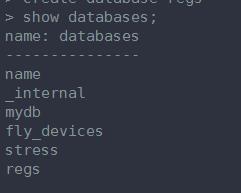
2、建表

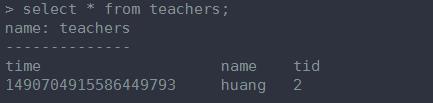

字段数目可以随意
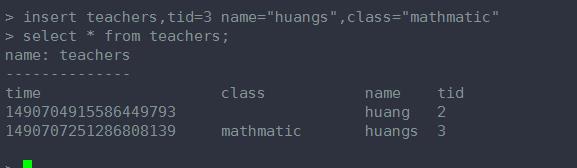
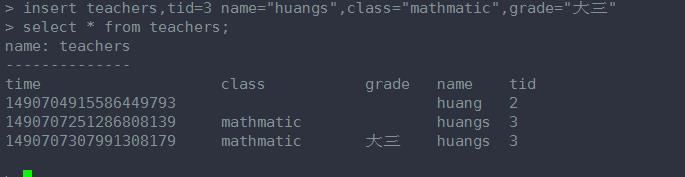
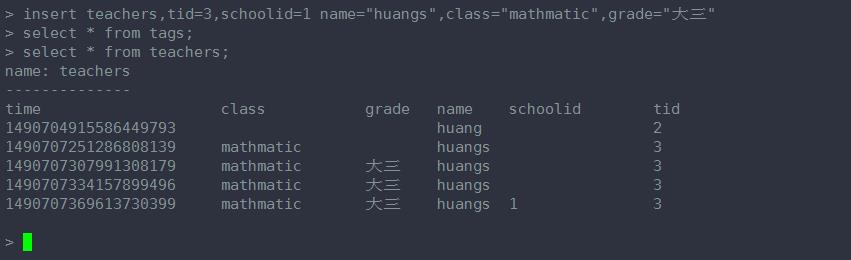
这条语句加了 一个 tag key ------schoolid
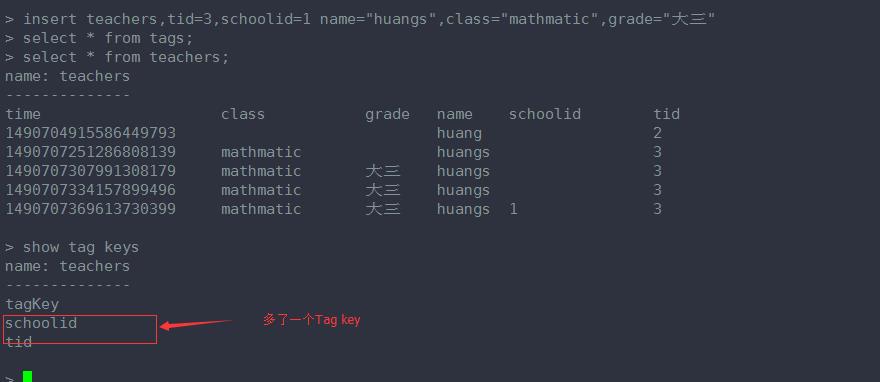
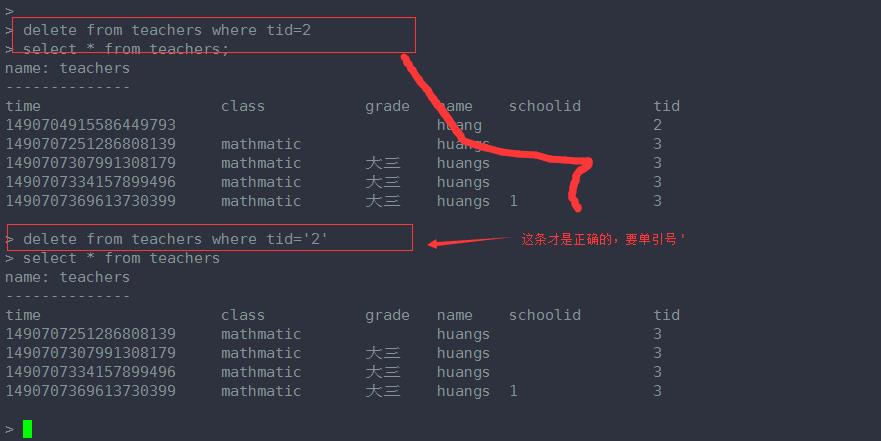
删除
删除整个数据库
以上是关于influxDB系列的主要内容,如果未能解决你的问题,请参考以下文章