华能 + Alluxio | 数字化浪潮下跨地域数据联邦访问与分析
Posted Alluxio
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了华能 + Alluxio | 数字化浪潮下跨地域数据联邦访问与分析相关的知识,希望对你有一定的参考价值。


1. 数字化转型与国产化进程推进
为了响应国家“十四五”数字经济发展规划的号召,中国企业推动创新资源共建共享,促进创新模式开放化演进,在信息化、数字化、智能化的强烈需求下,中国龙头企业统筹全渠道的技术能力,逐渐形成了一套覆盖集团业务发展、经营管理等核心发展战略需要的战略方向。
数字化转型初见成效,数据能力不断挖掘与创新;大数据技术推陈出新,国产化步伐日益加快。无论是互联网企业还是传统行业下的领导企业,有什么数据,如何使用数据,如何更加智能地利用数据这些议题被不断挖掘与迭代。
在东数西算的理念下,数据跨平台、跨机房、跨地域的技术问题与挑战逐渐浮现出来。这篇文章我们主要从技术的角度,对跨地域的数据联邦,或者说总公司和分公司不同数据域的互联互通进行讨论,研究相关技术可行性与分享整个研究过程。为了加快国产化软硬件的推进,本次实践采用国产化硬件ARM服务器(鲲鹏920)以及国产化操作系统统信进行相关的技术验证。
2. 原型目标与设计
通过对跨地域数据联邦的调研,我们发现中国很多企业面临的业务挑战虽然不同,但是技术难点是相似的,主要有:
挑战一:总公司通过传统的ETL作业采集分公司数据(比如通过Informatica、Kettle、DataX等),这些作业往往是按需定制,并且定期执行的;当有新的数据合规要求或者总公司数据分析要求时,都需要进行定制开发、测试、部署,这对数据汇总的时效性带来了很大的负面影响。另外通过ETL作业采集的分公司数据,在遇到分公司数据更新时,非常容易造成总公司与分公司之间的数据不一致,导致分析结果有所纰漏。
挑战二:子公司的自助式查询,一方面是对总公司的数据申请,很多时候整个数据访问链路是断裂的,往往需要通过流程筛查、繁琐的数据同步手段进行(比如通过FTP传输,甚至是物理介质的长途运输)。考虑到数据安全以及国家审计合规的要求,总公司数据是否可以在子公司持久化存储、数据访问脱敏、权限管控等等也都是当前中国企业面临的具体技术挑战。
因此我们本次的研究主要会关注在数据流的双向流动方面。
2.1 研究原型技术选型
当前大数据技术已经成为企业内部典型的数据分析手段,因此在原型实现的过程中,我们主要使用开源的大数据技术,从存储、计算(分析)、编排3个维度进行选型。其中每个维度我们选择时下最主流的组件,以确保该原型的通用性。
数据存储:
√ HDFS:Hadoop分布式文件系统(Distributed File System)
数据分析(以SQL分析为主):
√ Hive:构建于Hadoop之上的数据仓库,通过一种类SQL语言HiveQL为用户提供数据的归纳、查询和分析等功能。
数据编排:
√ lluxio:Alluxio是一个开源的虚拟分布式文件系统( Virtual Distributed File System, VDFS),位于大数据栈中的计算和存储之间。它为计算框架提供了数据抽象层,使得应用能够通过一个共同的接口连接底层不同的存储系统。
环境模拟:总公司/分公司-1/分公司-2
√ 每个公司有自建的HDFS集群;
√ 每个公司有自建的Alluxio集群:用于实现与本公司HDFS集群和其他公司HDFS集群的数据联邦;
√ 每个公司有自建的Hive集群。
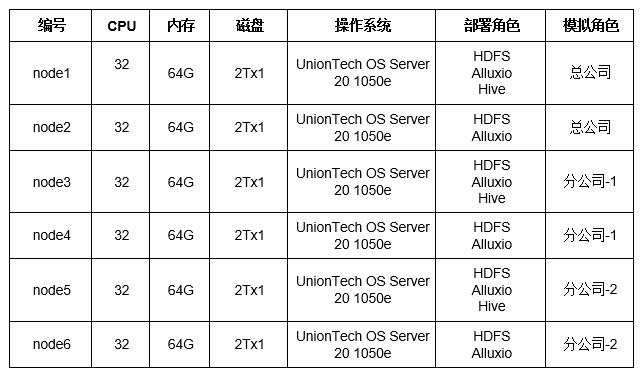
备注: CPU型号: 鲲鹏920 HDFS 3.1.1 Hive 3.1.0 Alluxio 2.8
2.2 数据流定义
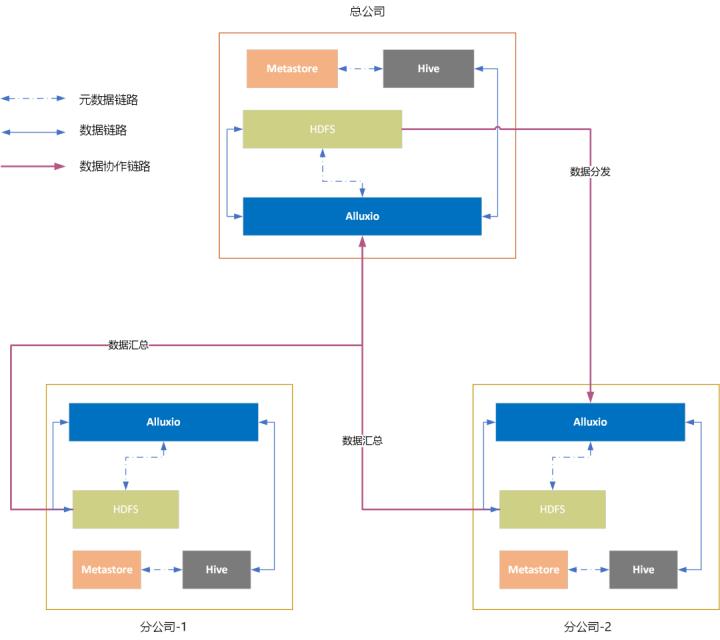
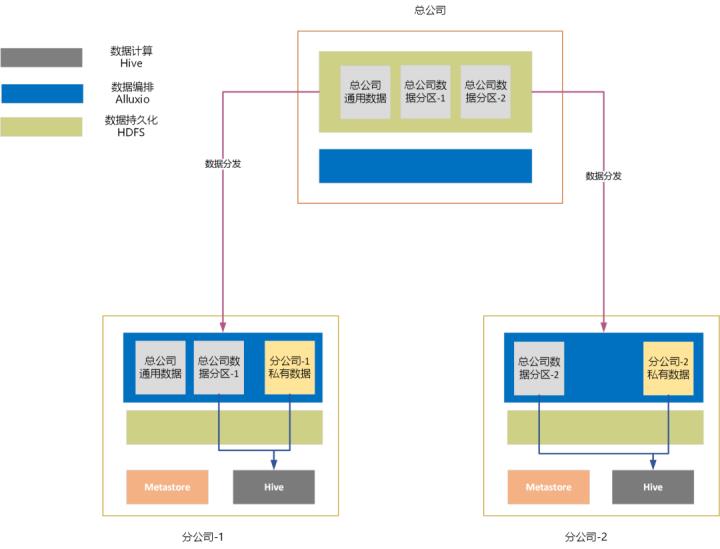
使用HDFS、Hive、Alluxio定义数据持久化与数据访问链路。在总公司和分公司构建统一的技术栈(技术标准),实现数据共享闭环: 1 在总公司数据域,实现分公司数据联邦,允许总公司实现全域数据访问与分析;
2 在分公司数据域,合规访问总公司数据湖,并结合子公司私有数据进行自助化分析;
3. Alluxio在ARM环境下的基本测试
3.1 Alluxio基于ARM编译
## 编译
mvn -T2C -DskipTests -Dmaven.javadoc.skip -Dlicense.skip -
Dcheckstyle.skip -Dfindbugs.skip clean install3.2 Alluxio基于ARM服务器的部署与基本测试
## 基本测试
[root@node1 ~]# alluxio runTests
3.3 Alluxio分布式高可用性验证(自动切换+手动切换)
## 管理命令获取元数据高可用信息
[root@node1 ~]# alluxio fsadmin journal quorum info -domain MASTER
Journal domain : MASTER
Quorum size : 3
Quorum leader : node1:19200
STATE | PRIORITY | SERVER ADDRESS
AVAILABLE | 0 | node1:19200
AVAILABLE | 0 | node2:19200
AVAILABLE | 0 | node3:19200
## 关闭主管理节点
[root@node1 ~]# alluxio-stop.sh master
Successfully Killed 1 process(es) successfully on node1
## 管理命令获取元数据高可用信息,检查管理节点自动切换状态
[root@node1 ~]# alluxio fsadmin journal quorum info -domain MASTER
Journal domain : MASTER
Quorum size : 3
Quorum leader : node2:19200
STATE | PRIORITY | SERVER ADDRESS
UNAVAILABLE | 0 | node1:19200
AVAILABLE | 0 | node2:19200
AVAILABLE | 0 | node3:19200
[root@node1 ~]### 管理命令获取元数据高可用信息
[root@node1 ~]# alluxio fsadmin journal quorum info -domain MASTER
Journal domain : MASTER
Quorum size : 3
Quorum leader : node2:19200
STATE | PRIORITY | SERVER ADDRESS
AVAILABLE | 0 | node1:19200
AVAILABLE | 0 | node2:19200
AVAILABLE | 0 | node3:19200
## 手动切换主节点
[root@node1 ~]# alluxio fsadmin journal quorum elect -address node3:19200
Initiating transfer of leadership to node3:19200
Successfully elected node3:19200 as the new leader
Resetting priorities of masters after successful transfer of leadership
Quorum priorities were reset to 1
## 管理命令获取元数据高可用信息,检查管理节点切换状态
[root@node1 ~]# alluxio fsadmin journal quorum info -domain MASTER
Journal domain : MASTER
Quorum size : 3
Quorum leader : node3:19200
STATE | PRIORITY | SERVER ADDRESS
AVAILABLE | 1 | node1:19200
AVAILABLE | 1 | node2:19200
AVAILABLE | 1 | node3:19200
[root@node1 ~]#3.4 Alluxio与HDFS集成
## HDFS数据查询
[root@node1 alluxio]# hdfs dfs -ls /test/
Found 1 items
-rw-r--r-- 1 root hdfsadmingroup 53136 2022-07-22 16:57 /test/pom.xml
## Alluxio数据挂载映射
[root@node1 alluxio]# alluxio fs mount /test/ hdfs://node1:9000/test
Mounted hdfs://node1:9000/test at /test
## Alluxio数据查询
[root@node1 alluxio]# alluxio fs ls -R /test
-rw-r--r-- root hdfsadmingroup 53136 PERSISTED 07-22-2022 16:57:23:651 0% /test/pom.xml
[root@node1 alluxio]#3.5 Alluxio与Hive集成
## 创建Hive表
hive> create table test.test(id int) location 'alluxio://node1:19998/test/test';
OK
Time taken: 0.116 seconds
hive>3.6 Alluxio基于ACL的权限控制
## 默认其他用户可以访问,禁止其他用户可以访问
[root@node1 ~]# alluxio fs setfacl -m user::--- /test
[root@node1 ~]# alluxio fs setfacl -m other::--- /test
## user1 用户访问失败
user1@node1 ~]$ alluxio fs ls /test
Permission denied: user=user1, access=r--, path=/test: failed at test, inode owner=root, inode group=root, inode mode=---r-x—
[user1@node1 ~]$
## user1 用户授权,访问成功
root@node1 ~]# alluxio fs setfacl -m user:user1:rwx /test
[user1@node1 ~]$ alluxio fs ls /test
-rw-r--r-- root root 1726 PERSISTED 07-25-2022 14:50:51:180 100% /test/run-presto.pl
[user1@node1 ~]$
## user2 用户未授权访问失败
[user2@node1 ~]$ alluxio fs ls /test
Permission denied: user=user2, access=r--, path=/test: failed at test, inode owner=root, inode group=root, inode mode=---r-x---
[user2@node1 ~]$
## 取消授权user1,访问失败
root@node1 ~]# alluxio fs setfacl -b /test
[user1@node1 ~]$ alluxio fs ls /test
Permission denied: user=user1, access=r--, path=/test: failed at test, inode owner=root, inode group=root, inode mode=---r-x---
[user1@node1 ~]$
## 查看目录权限
[root@node1 ~]# alluxio fs getfacl /test
# file: /test
# owner: root
# group: root
user::---
group::r-x
other::---
mask::rwx
[root@node1 ~]#4. 数据域联邦场景研究
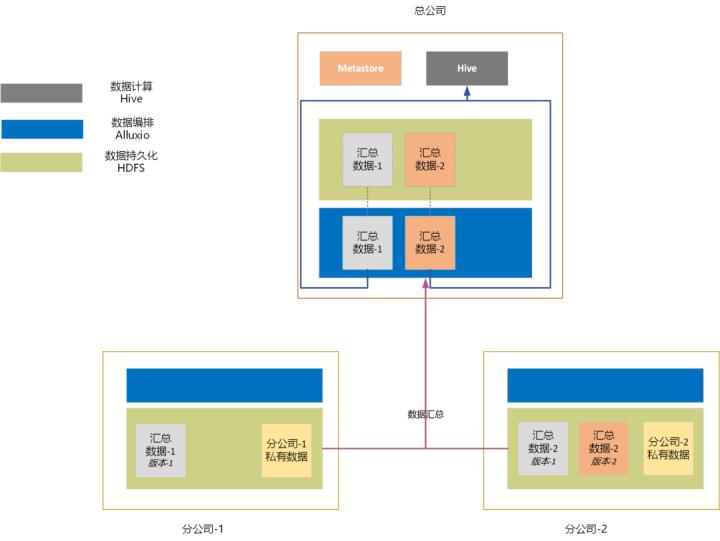
4.1 分公司数据汇总与总公司集中式分析
数据流验证:在总公司数据域,实现分公司数据联邦,允许总公司实现全域数据访问与分析:
√ 构建总公司分公司模拟环境;
√ 总公司基于Alluxio创建数据表T3,建立分区x, y, z;
√ 分公司-1将HDFS目录X映射到总公司Alluxio分区x,准备模拟数据;
√ 分公司-2将HDFS目录Y映射到总公司Alluxio分区y,准备模拟数据;
√ 总公司使用Hive读取T3数据,验证:访问分公司-1与分公司-2的所有数据正常;
√ 分公司-2将目录Y的数据进行更新;
√ 通知总公司数据表T3 y分区数据变更(元数据失效);
√ 总公司使用Hive读取T3数据,验证:访问分公司-1与分公司-2(更新后)的所有数据正常。
## 总公司创建t3 表
hive> create external table group_company.t3(value string)
> partitioned by (part string)
> location 'alluxio://node1:19998/group_company/t3';
OK
Time taken: 0.069 seconds
hive>
## 分公司1 分区x挂载到总公司 alluxio
[root@node1 ~]# hdfs dfs -put part\\=x/ hdfs://node3:9000/regional_company_1/t3
[root@node1 ~]# hdfs dfs -put part\\=y/ hdfs://node5:9000/regional_company_2/t3
[root@node1 ~]#
[root@node1 ~]# alluxio fs mount \\
> /group_company/t3/part=x \\
> hdfs://node3:9000/regional_company_1/t3/part=x
Mounted hdfs://node3:9000/regional_company_1/t3/part=x at /group_company/t3/part=x
[root@node1 ~]#
## 查询数据
hive> MSCK REPAIR TABLE group_company.t3;
OK
Partitions not in metastore: t3:part=x
Repair: Added partition to metastore t3:part=x
Time taken: 0.169 seconds, Fetched: 2 row(s)
hive> select * from group_company.t3;
OK
1abc x
Time taken: 0.108 seconds, Fetched: 1 row(s)
hive>
## 分公司2 分区y挂载到总公司 alluxio
[root@node1 ~]# alluxio fs mount \\
> /group_company/t3/part=y \\
> hdfs://node5:9000/regional_company_2/t3/part=y
Mounted hdfs://node5:9000/regional_company_2/t3/part=y at /group_company/t3/part=y
[root@node1 ~]#
## 查询数据
hive> MSCK REPAIR TABLE group_company.t3;
OK
Partitions not in metastore: t3:part=y
Repair: Added partition to metastore t3:part=y
Time taken: 0.153 seconds, Fetched: 2 row(s)
hive> select * from group_company.t3;
OK
1abc x
2def y
Time taken: 0.137 seconds, Fetched: 2 row(s)
hive>
## 更新分区y 数据
[root@node1 ~]# hdfs dfs -cat hdfs://node5:9000/regional_company_2/t3/part=y/000000_0
2def
[root@node1 ~]# hdfs dfs -get hdfs://node5:9000/regional_company_2/t3/part=y/000000_0
[root@node1 ~]# echo '1111' > 000000_0
[root@node1 ~]# hdfs dfs -rm hdfs://node5:9000/regional_company_2/t3/part=y/000000_0
Deleted hdfs://node5:9000/regional_company_2/t3/part=y/000000_0
[root@node1 ~]# hdfs dfs -put 000000_0 hdfs://node5:9000/regional_company_2/t3/part=y/
[root@node1 ~]# hdfs dfs -cat hdfs://node5:9000/regional_company_2/t3/part=y/000000_0
1111
[root@node1 ~]#
## 更新查询数据
hive> select * from group_company.t3;
OK
1abc x
2def y
Time taken: 0.112 seconds, Fetched: 2 row(s)
hive>
## 通知总公司更新数据
[root@node1 ~]# alluxio fs loadMetadata -F /group_company/t3
[root@node1 ~]#
## 总更新数据后查询
hive> select * from group_company.t3;
OK
1abc x
1111 y
Time taken: 0.1 seconds, Fetched: 2 row(s)
hive>4.2 总公司数据分发与分公司自助分析
数据流验证:在分公司数据域,合规访问总公司数据湖,并结合私有数据进行自助化分析:
√ 构建总公司分公司模拟环境;
√ 总公司基于HDFS创建数据表T1,建立分区a, b, c;
√ 分公司-1基于Alluxio使用数据表T1元数据创建相应表格T1’;
√ 总公司挂载分区a到分公司-1的Alluxio相关目录;
√ 分公司-1的Hive, 访问T1’,验证:访问分区a的数据正常;
√ 总公司挂载分区c到分公司-1的Alluxio相关目录;
√ 通过分公司-1的Hive, 访问T1’,验证:访问分区a/c的数据正常;
√ 总公司将挂载的分区c从分公司1撤回;
√ 通过分公司-1的Hive, 访问T1’,验证:仅能正常访问分区a的数据;
√ 分公司创建数据表T2,完成数据表之间的join类型SQL,验证:总公司数据与分公司自有数据联邦访问正常。
## 总公司创建 t1 表 三个分区 a b c
hive> create database group_company location '/user/hive/group_company.db';
OK
Time taken: 0.017 seconds
hive> create external table group_company.t1(value string) partitioned by (part string);
OK
Time taken: 0.144 seconds
hive> insert into table group_company.t1 partition(part='a') values('1abc');
hive> insert into table group_company.t1 partition(part='b') values('2def');
hive> insert into table group_company.t1 partition(part='c') values('3ghi');
hive> select * from group_company.t1;
OK
1abc a
2def b
3ghi c
Time taken: 0.142 seconds, Fetched: 3 row(s)
## 分公司1 挂载总表分区 a
[root@node3 alluxio]# bin/alluxio fs mkdir /regional_company_1/t1/
Successfully created directory /regional_company_1/t1
[root@node3 alluxio]#
[root@node3 alluxio]# bin/alluxio fs mount \\
> /regional_company_1/t1/part=a \\
> hdfs://node1:9000/user/hive/group_company.db/t1/part=a
Mounted hdfs://node1:9000/user/hive/group_company.db/t1/part=a at /regional_company_1/t1/part=a
[root@node3 alluxio]#
## 创建表查询数据
hive> create external table t1(value string)
> partitioned by (part string)
> location 'alluxio://node3:19998/regional_company_1/t1';
OK
Time taken: 0.972 seconds
hive> select * from t1;
OK
Time taken: 1.282 seconds
hive> MSCK REPAIR TABLE t1;
OK
Partitions not in metastore: t1:part=a
Repair: Added partition to metastore t1:part=a
Time taken: 0.235 seconds, Fetched: 2 row(s)
hive> select * from t1;
OK
1abc a
Time taken: 0.137 seconds, Fetched: 1 row(s)
hive>
## 分公司1 挂载总表分区 c
[root@node3 alluxio]# bin/alluxio fs mount \\
> /regional_company_1/t1/part=c \\
> hdfs://node1:9000/user/hive/group_company.db/t1/part=c
Mounted hdfs://node1:9000/user/hive/group_company.db/t1/part=c at /regional_company_1/t1/part=c
[root@node3 alluxio]#
## 查询数据
hive> MSCK REPAIR TABLE t1;
OK
Partitions not in metastore: t1:part=c
Repair: Added partition to metastore t1:part=c
Time taken: 0.244 seconds, Fetched: 2 row(s)
hive> select * from t1;
OK
1abc a
3ghi c
Time taken: 0.145 seconds, Fetched: 2 row(s)
hive>
## 撤回
[root@node3 alluxio]# bin/alluxio fs unmount /regional_company_1/t1/part=c
Unmounted /regional_company_1/t1/part=c
[root@node3 alluxio]#
hive> select * from t1;
OK
1abc a
Time taken: 2.281 seconds, Fetched: 1 row(s)
hive>
## join t2 表
hive> select * from t2;
OK
5678 a
1234 d
Time taken: 0.082 seconds, Fetched: 2 row(s)
hive>
hive> select * from (
> select * from t1
> ) t1
> join (
> select * from t2
> ) t2
> on t1.part = t2.part;
Query ID = root_20220720135305_c5730dc3-a46a-478a-a368-2e0343385700
Total jobs = 1
Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
2022-07-20 13:53:26,621 Stage-3 map = 0%, reduce = 0%
2022-07-20 13:53:31,775 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 2.42 sec
MapReduce Total cumulative CPU time: 2 seconds 420 msec
Ended Job = job_1658118353477_0009
MapReduce Jobs Launched:
Stage-Stage-3: Map: 1 Cumulative CPU: 2.42 sec HDFS Read: 8876 HDFS Write: 113 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 420 msec
OK
1abc a 5678 a
Time taken: 27.333 seconds, Fetched: 1 row(s)
hive>5. 总结
通过本次研究发现:
1 我们在国产化软硬件环境中(ARM+统信)对当前主流组件完成了适配和基本验证,Hive+Alluxio+HDFS的技术栈可以在国产化环境下正常运行;
2 通过Alluxio数据编排实现跨地域的数据联邦,实现总公司与分公司之间不同物理数据域的互联互通,提供企业内部完整的数据链路;
3 通过Alluxio自身的ACL控制,以及Alluxio与底层UFS(本次验证是HDFS)的挂载设定进行数据逻辑映射的控制;
在技术可行性方面的验证,也为我们日后的原型优化提供了更多的思路:
1 考虑新的数据合规要求,设定Alluxio中数据的TTL控制数据访问生命周期;
2 数据更新的机制,无论是利用UFS自身的变更通知还是外围的消息机制,更好地保障企业内部跨数据域的数据访问一致性;
3 更加细粒度的数据访问控制,通过更多的数据语义理解,提高对数据管理的灵活度;
想要获取更多有趣有料的【活动信息】【技术文章】【大咖观点】,请点击关注[Alluxio智库]:

以上是关于华能 + Alluxio | 数字化浪潮下跨地域数据联邦访问与分析的主要内容,如果未能解决你的问题,请参考以下文章