深入探讨!Batch 大小对训练的影响
Posted 红色石头Will
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入探讨!Batch 大小对训练的影响相关的知识,希望对你有一定的参考价值。

一、概要:
批训练(mini-batch)的训练方法几乎每一个深度学习的任务都在用,但是关于批训练的一些问题却仍然保留,本文通过对MNIST数据集的演示,详细讨论了batch_size对训练的影响,结果均通过colab(https://colab.research.google.com/drive/1ygbjyKZH2DPhMbAU7r2CUm3f59UHq7Iv?usp=sharing)跑出,开始时对数据进行了归一化处理,其他的与经典CNN代码无差,(单GPU:Telsa T4),对结果怀疑的可以去复现一下。
二、实验结果:
首先我选取了 Batch Size=64,Epochs=20,进行了18次实验,第一张图横坐标是训练次数,纵坐标是每一次单独所花时间,由图易得趋势是很不稳定的,这跟批训练的本质有关,这在第三节中有详细探讨。由此可以得出一个结论:
''任何时候几乎每一次的训练得到的结果都是互异的,当且仅当超参数一致和不同批之间的数据分布几乎无差情况下不满足。''
因而多数情况下,批训练出的结果不一定具有很强的代表性,之所以会比较它们的原因主要是为了比对不同配置(如超参数不一样)带来的相对变化,若以一次批训练的结果就开始信口开河就不免滑稽了。

下面两张图是不同的两次训练所呈现的精确度与Epochs的关系,不难发现,两者的平稳程度有很大差异,也符合前面的结论。


因为训练时较不稳定,因此在以下的对照实验中每一组均至少进行5次实验,选取较为接近的数据( ±3% )取平均,当然,可以发现 Batch Size=64 时的情况与上面又有一定差异。下表中的数据基于 Epochs=20 , Time 指的是跑完所有的Epochs所需的时间。

最慢的为 Batch Size=1 的情况,如果一开始数据经过了shuffle处理,这种情况可以近似为SGD。
不存在无条件batch越大,时间越短的情况,只是在一定范围内( [1, 1024] )该结论成立,虽然1024时时间慢于512,考虑到不稳定的情况,这里扩大了范围,当然,结论在 [1,512] 范围内应满足。
当 Batch Size>=1024 之后,尽管速度比64和128来得快,但是却较难收敛,所以较大batch和较小batch之间几乎没有可比性。
接下来我将后面不能完全收敛的组在 Epochs=80 的设置下继续进行实验,可以发现会有轻微提升但还是不能收敛,关于如何实现大batch加速在会在第四节讨论。

三、批训练的本质:
如果把训练类比成从山顶到山脚的过程,批训练就是每一次你选定一个方向(一个batch的数据)往下走,batch的大小可以类比成你打算每一次走多少步,当然,深度学习是实验型科学,这里的例子只是尝试解释一下intuition,例子有不妥之处,乐一乐也无妨。
若 Batch Size=1 ,小碎步往下走,谨小慎微,自然花的时间比较多
当 Batch Size 慢慢增大时,你思考的时间相对来讲会变少,但你每一次的遇到的路况不算多,因而你学习能力强,应对出现过的路况能较好应对,训练会一定程度提高
当 Batch Size 很大时,你一开始一个大跨步就直接来到了一个很平坦的地方,你误以为这边就是山脚,因而卡在了局部最优处,当然如果你运气好,每次都是有坡度的情况,你很快就到了山脚。或者可以这样想,你一下子走太多步,有些路况你给忘了,导致下一次走的时候做了错误的选择,导致走不出来,这也是大batch泛化能力差的原因吧。
训练时需要保证batch里面的数据与整个数据的差异不太大,如果当差异很大的时候,我们一开始遇到的路况跟后面的完全不一样,导致你直接懵逼,训练效果差。
四、保持准确率的大batch加速:
详见: Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
https://arxiv.org/abs/1706.02677
虽然是2017的论文,但是是篇有意思的论文,通过分布式训练可以在 Batch Size=8k 的时候保持准确率,时间为1hour,数据集为ImageNet,有多个GPU的可以去深挖一下,加速自己的训练,因我连GPU都是白嫖colab的,分布式更不可能了,这里只是简单叙述而已。
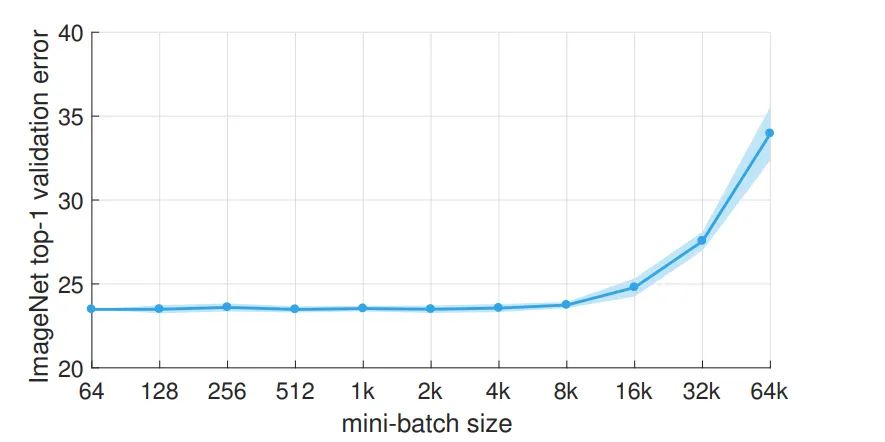
Linear Scaling Rule:当mini-batch的大小乘以k,则学习率也乘以k。
x 是从总的分布 X 中取样出来,w 代表一个网络的权重参数, l(x,w) 意味着损失,将它们加起来再除以总数据分布的大小便是总损失了。

mini-batch的SGD更新一次如下, B 是一个从 X 中取样出来的mini-batch, n=|B| 是mini-batch的大小。
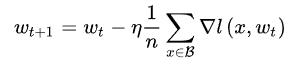
在时间步 t ,权重参数为 wt ,经过 k 次迭代更新后如下,这是一次一次叠加起来的
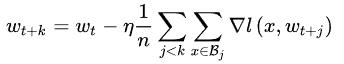


warm-up:一开始的学习率不那么高
脸书讨论了两种热身方式:恒定常数和循序渐进法进行热身。前者说的是在前5个Epochs保持学习率为 η ,之后再调为 kη ,在fine-tune目标识别和分割的任务中的模型大有裨益,可是当 k 很大后,错误急剧上升。循序渐进说的是一开始为 η,然后不断加上常数,要求是前5个训练结束后能达到 kη 。后者证明在训练ImageNet更有效。
技巧还有每一个分布式GPU训练的损失除以 kn 和对修改后的学习率进行momentum修正。还有一些分布式的细节这里不再详述。
五、讨论:
看了脸书的那篇论文,我也突发奇想,能不能设计一个自定义的学习率来试试呢?实验中 Batch Size=1024,Epochs=20 ,选取的自定义为每当经过了step size的optimizer.step()就给学习率乘上 γ ,当 Batch Size=1024 时,一共有59个batch,因而step的总次数为59 * 20 = 1180,同时考虑到模型在第6个Epoch卡在局部最优点,将step size设为100,当然也设置过200,400等,结果一样收敛不了。

推荐阅读
(点击标题可跳转阅读)
重磅!
AI有道年度技术文章电子版PDF来啦!

扫描下方二维码,添加 AI有道小助手微信,可申请入群,并获得2020完整技术文章合集PDF(一定要备注:入群 + 地点 + 学校/公司。例如:入群+上海+复旦。

长按扫码,申请入群
(添加人数较多,请耐心等待)
感谢你的分享,点赞,在看三连 
以上是关于深入探讨!Batch 大小对训练的影响的主要内容,如果未能解决你的问题,请参考以下文章