atlas 初体验
Posted scx_white
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了atlas 初体验相关的知识,希望对你有一定的参考价值。
介绍
最近由于内部需要做
spark sql的字段血缘关系,碰巧看到github有人提供了spark的atlas插件,准备调研一下看能否满足需求。
介绍:
Atlas是Hadoop的数据治理和元数据框架。
Atlas是一组可扩展和可扩展的核心基础治理服务,使企业能够有效,高效地满足Hadoop中的合规性要求,并允许与整个企业数据生态系统集成。
Apache Atlas为组织提供了开放的元数据管理和治理功能,以建立其数据资产的目录,对这些资产进行分类和治理,并为数据科学家,分析师和数据治理团队提供围绕这些数据资产的协作功能。
废话不多说,开始
下载和安装
在 Github 上提供了0.x,1.x,2.x 版本,其中 2.x 版本需要 hive 3.0 以上才能支持,否则安装 hive hook 时会出现异常
2020-08-27T06:11:21,978 ERROR [3cf21166-5613-4313-a607-d6b77d305de3 main] hook.HiveHook: HiveHook.run(): failed to proceoperation QUERY
java.lang.NoSuchMethodError: org.apache.hadoop.hive.metastore.api.Database.getCatalogName()Ljava/lang/String;
由于官网没有提示 atlas 版本和 hive 版本的对应,所以大家需要根据自己的 hive 版本选择合适的 atlas 版本,查看我们的 hive 版本为 2.3.5,所以直接下载 1.x 版本即可
[hadoop@172 ~]$ hive --version
Hive 2.3.5
Git git://compile73/cdisk/App/emr_release/hive -r 76595628ae13b95162e77bba365fe4d2c60b3f29
Compiled by root on Fri Feb 21 11:32:28 CST 2020
From source with checksum 3643e20917bddf360a9f7a5f57c37023
一、下载atlas-release-1.2.0-rc3.tar.gz 后上传到gateway机器
二、tar -zxvf 解压 atlas-release-1.2.0-rc3.tar.gz
三、 进入解压后的目录atlas-release-1.2.0-rc3
四、打包
由于 atlas 需要依赖 hbase+solr,并且我们目前是为了调研测试,无需搭建 hbase 和 solr 集群,直接执行 mvn clean -DskipTests package -Pdist ,该命令会在打包时内嵌 hbase+solr
此打包过程会持续十几个小时(需要下载 hbse、solr 等很多资源包,下的很慢),要耐心等待,我更建议使用 nohup mvn clean -DskipTests package -Pdist >exe.log & 来后台执行。
最好不要在本地有 vpn 的机器上打包,然后上传到远程机器,否则你要修改很多配置,因为一些默认配置在打包的时候生成,使用的是你打包时候的路径。
五、打包完成后进入 atlas-release-1.2.0-rc3/distro/target
六、在该目录下使用 tar -zxvf 解压 apache-atlas-1.2.0-server.tar.gz ,解压后的目录为 apache-atlas-1.2.0
七、进入 /data/atlas/atlas-release-1.2.0-rc3/distro/target/apache-atlas-1.2.0目录
八、然后执行 bin 目录的 atlas_start.py 脚本启动 atlas 默认端口是 21000
执行过程中需要看日志可以进入 logs 查看 atlas 的启动日志,hbase/logs 查看 hbase 的启动日志,有时候 hbase 可能启动有问题
测试
进入 http://ip:21000 端口,进入登陆界面,表示安装部署完成。默认账号密码:admin/admin

hive sql 解析支持
添加 hive hook
一、进入 $HIVE-HOME/conf 在 hive-site.xml 中添加 atlas 的 hive 钩子
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
二、在打包成功后的 atlas-release-1.2.0-rc3/distro/target 目录解压 apache-atlas-1.2.0-hive-hook.tar.gz 压缩包
三、解压后目录为 atlas-release-1.2.0-rc3/distro/target/apache-atlas-1.2.0-hive-hook/apache-atlas-hive-hook-1.2.0/
三、在 $HIVE-HOME/conf 目录中对 hive-env.sh 文件增加 export HIVE_AUX_JARS_PATH=atlas-release-1.2.0-rc3/distro/target/apache-atlas-1.2.0-hive-hook/apache-atlas-hive-hook-1.2.0/hook/hive 配置
四、复制 atlas-release-1.2.0-rc3/distro/target/apache-atlas-1.2.0/conf/atlas-application.properties 文件到 $HIVE-HOME/conf 目录
导入hive元数据
在 atlas-release-1.2.0-rc3/distro/target/apache-atlas-1.2.0-hive-hook/apache-atlas-hive-hook-1.2.0/hook-bin 目录有 import-hive.sh 脚本
直接通过 sh import-hive.sh 执行该脚本导入 hive 元数据,执行过程中会提示输入 atlas 的账号密码,默认为: admin/admin
启动过程中可能会报错,比如我遇见了
Exception in thread "main" java.lang.NoClassDefFoundError: com/fasterxml/jackson/jaxrs/json/JacksonJaxbJsonProvider
初步判断为 jackson 的 jar 冲突了,查看 import-hive.sh 脚本,发现会加载hook/hive/atlas-hive-plugin-impl 的 jar

hive 的 jar 与 atlas-hive-plugin-impl 的 jar 里面都包含 jackson 的相关 jar,于是我使用 rm jackson-* 删除了atlas-hive-plugin-impl 的相关jar解决了该冲突问题
导入 hive 元数据后可以登陆 atlas 界面查看相关元数据信息

并且表的建表血缘也已经导入
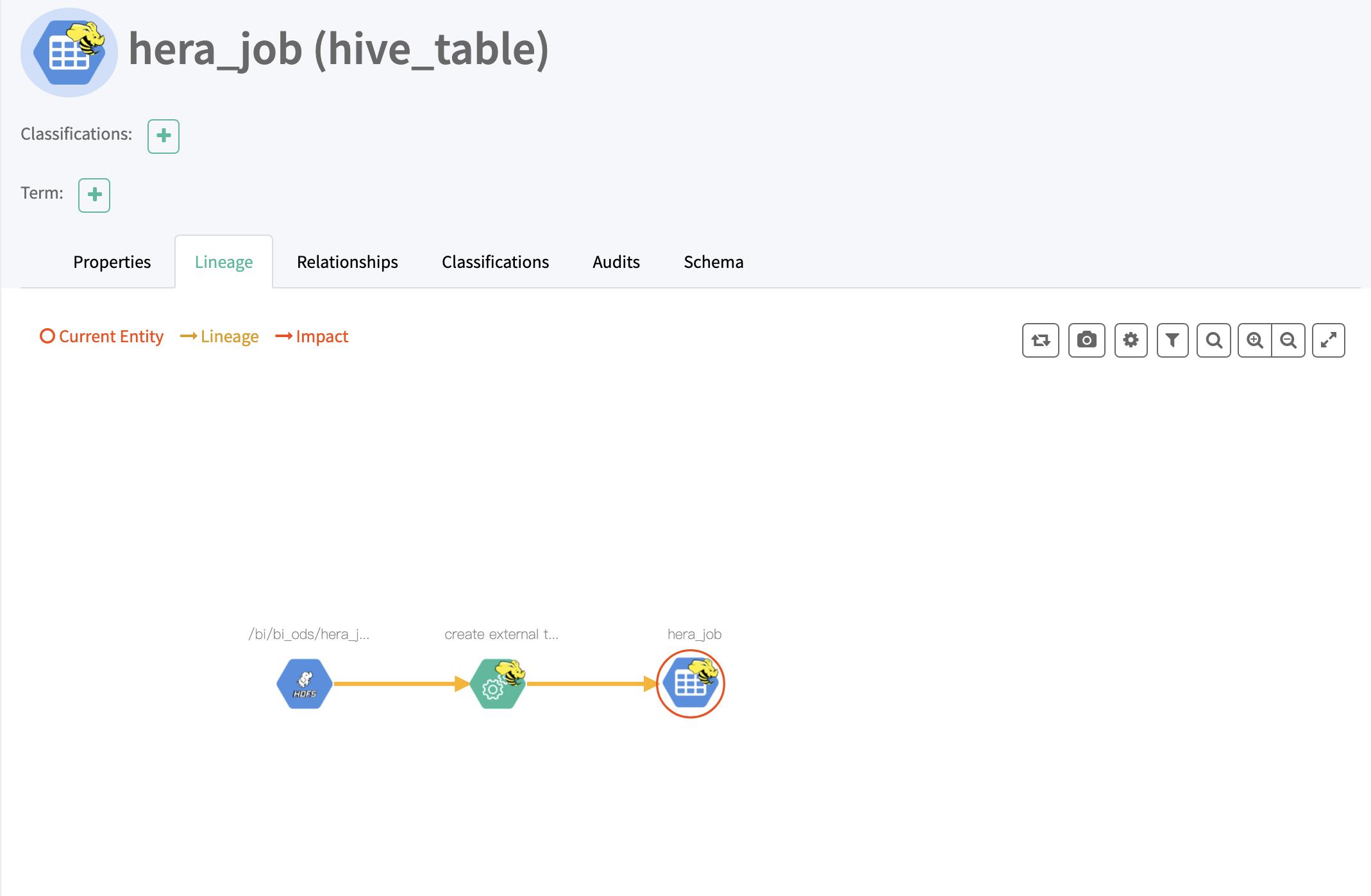
字段的信息也已经录入

测试hive hook
简单执行一个hera资源统计的hive脚本
use sucx_test
;
-- 昨日升级设备数
create table if not exists qs_tzl_ProductTag_result(
pid string
,category string
,category_code string
,tag_name string
,tag_value string
,other string
,update_time string
)
partitioned by (tag_id string)
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY')
;
insert overwrite table qs_tzl_ProductTag_result partition(tag_id='3014')
select
T1.product_id as pid
,T2.category
,cast(from_unixtime(unix_timestamp()) as string) as update_time
from (select
product_id
from COM_PRODUCT_UPGRADE_STAT_D where p_day='20200901'
) T1
left join (select category
from bi_ods.ods_smart_product where dt='20200901'
) T2
on T1.product_id=T2.id
;
执行后查看 qs_tzl_ProductTag_result 的表级血缘为
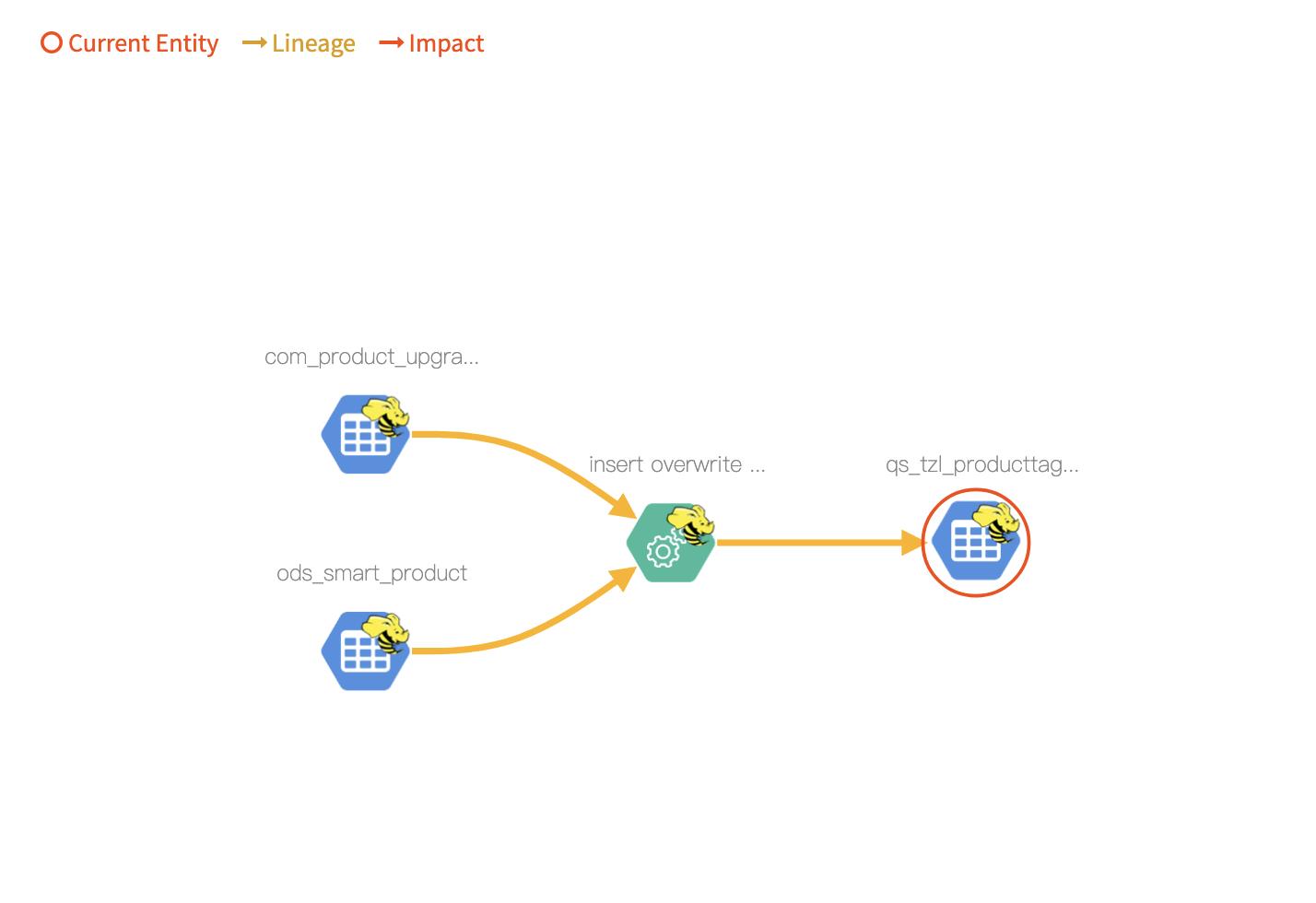
pid 的字段血缘为

spark sql解析支持
安装
atlas 官方文档中并不支持 spark sql 的解析,在 github 中找到了一个支持spark 解析的插件
地址: https://github.com/hortonworks-spark/spark-atlas-connector
一、git clone 后本地进行打包
mvn package -DskipTests
二、打包后在 spark-atlas-connector/spark-atlas-connector-assembly/target 目录有一个 spark-atlas-connector-assembly-$version.jar 的 jar,将该 jar 上传到服务器。
需要注意的是不要上传 spark-atlas-connector/spark-atlas-connector/target 这个目录内的 jar ,缺少相关依赖包

三、将 spark-atlas-connector-assembly-$version.jar 放到一个固定目录 比如/opt/resource
四、在 spark-atlas-connector/patch 目录,有一个 1100-spark_model.json 的文件,将该文件先上传到服务器

五、将 1100-spark_model.json 放到 atlas-release-1.2.0-rc3/distro/target/apache-atlas-1.2.0/models/1000-Hadoop 目录
六、重启 atlas
测试spark hook
首先进入spark-sql client
spark-sql --master yarn \\
--jars /opt/resource/spark-atlas-connector_2.11-0.1.0-SNAPSHOT.jar \\
--files /opt/resource/atlas-application.properties \\
--conf spark.extraListeners=com.hortonworks.spark.atlas.SparkAtlasEventTracker \\
--conf spark.sql.queryExecutionListeners=com.hortonworks.spark.atlas.SparkAtlasEventTracker \\
--conf spark.sql.streaming.streamingQueryListeners=com.hortonworks.spark.atlas.SparkAtlasStreamingQueryEventTracker
执行 hera 的一个资源统计任务
CREATE EXTERNAL TABLE IF NOT EXISTS sucx_hera.ads_hera_task_mem_top_10(
`job_id` BIGINT COMMENT '任务ID',
`user` STRING COMMENT '关注人',
`applicationId` STRING COMMENT 'yarn执行的app id',
`memorySeconds` BIGINT COMMENT '内存使用时间和',
`startedTime` BIGINT COMMENT '开始时间',
`finishedTime` BIGINT COMMENT '结束时间',
`elapsedTime` BIGINT COMMENT '运行时间',
`vcoreSeconds` BIGINT COMMENT 'vcore使用时间和')
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'field.delim'='\\t',
'serialization.format'='\\t')
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'cosn://sucx-big-data/bi//sucx_hera/ads_hera_task_mem_top_10';
insert overwrite table sucx_hera.ads_hera_task_mem_top_10
select
job_id,user,applicationId,memorySeconds,startedTime,finishedTime,elapsedTime,vcoreSeconds
from
(SELECT
top.job_id,
row_number() over(distribute by top.applicationId ORDER BY sso.id) as num,
case when sso.name is null then operator
else sso.name end as user,
top.applicationId,
top.memorySeconds,
top.startedTime,
top.finishedTime,
top.elapsedTime,
top.vcoreSeconds
FROM (
select * from sucx_hera.dws_hera_task_mem_top_10 where dt = '20200901' ) top
left join bi_ods.ods_hera_job_monitor monitor
on monitor.dt='20200901' and top.job_id=monitor.job_id
left join bi_ods.ods_hera_sso sso
on sso.dt='20200901' and find_in_set(sso.id,monitor.user_ids) >0 order by job_id ) temp
where temp.num = 1
执行后,查看 ads_hera_task_mem_top_10 表级血缘

查看 ads_hera_task_mem_top_10 字段血缘,找不到

查看 github issue,在 https://github.com/hortonworks-spark/spark-atlas-connector/issues/227 发现作者强制关闭了 spark 字段的支持,并删除了相关代码 https://github.com/hortonworks-spark/spark-atlas-connector/pull/228。
作者原话是:
It has been headache and troublesome to keep the logic to support table column but having flag to disable it. Even we have dirty workaround to remove column attribute from created entities, which incurred a bug I had to fix.
We don’t have any chance to turn it on, and once we support column entities I think it should be supported as default and shouldn’t be able to turn it off.
This patch proposes to discard the logic to supporting table column entities at all.
由于只有作者一个人维护,字段功能被废弃了。
结论
对于 hive sql 任务,我们可以完美的通过 atlas 的 hive hook 来实现表、以及字段的血缘,而对于 spark sql 任务,使用 spark-atlas-connector 只能实现表级别的血缘,目前字段的血缘还没发现开源的产品,难道又要自己开发了么。。。
关注我,随时获取最新文章哦

以上是关于atlas 初体验的主要内容,如果未能解决你的问题,请参考以下文章