基于 Apache Hudi 和 Apache Spark Sql 的近实时数仓架构分享
Posted scx_white
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于 Apache Hudi 和 Apache Spark Sql 的近实时数仓架构分享相关的知识,希望对你有一定的参考价值。
前言
在大数据的计算场景中,根据数据的延迟情况,数据的时效性一般分为离线、准实时、实时。离线计算一般是以天(T)为界限,比如离线场景最多的就是T-1 计算,也就是今天计算昨天产生的数据。准实时计算一般以小时(H)为界限,比如 H-1 的计算,即当前小时处理上个小时的数据,当然某些业务场景下也有(0.5H-1)计算的存在。而实时计算一般是以秒为界限,即数据的延迟最大粒度为秒级。对于离线和准实时计算,我们可以在调度系统中通过不同的调度周期实现,而实时计算通常需要一个常驻的任务来进行。对于相同业务,不同的时效要求下,任务计算所需要的资源成本通常为:离线 < 准实时 < 实时。 本文所说的近实时介于实时和准实时之间的一种实效要求,一般在 1 分钟至 30 分钟之间,在该时延的要求下,一般调度系统也能实现,但具体是使用常驻任务还是调度系统周期调度就看业务所能容忍的最大延迟时间与计算成本之间的权衡了。
近实时架构
在刚刚接触数据湖的概念以及深入了解其各种特性时,曾 yy 过一种如下的数仓架构。但是直到最近基础设施才满足以该方式实现。在之前,这套架构如果想让数仓/数开同学用起来,成本有些太高。对于离线数仓,为了代码的可读性和维护性,我们让数仓直接在调度平台的界面上使用 sql开发。而近实时数仓,由于一些框架的限制,还无法全部使用 sql 来实现,需要配合使用 java/scala 代码来进行开发,然后把 jar 包发布到集群上才能被调度执行。由于无法自动对 jar 包进行元数据的解析,任务上下游依赖配置时还需要人为选择,对代码的开发、维护和发布增加了困难。所以这种方法一直没有推广开来,只能由专业的几个人来做,直到最近,看到了曙光。
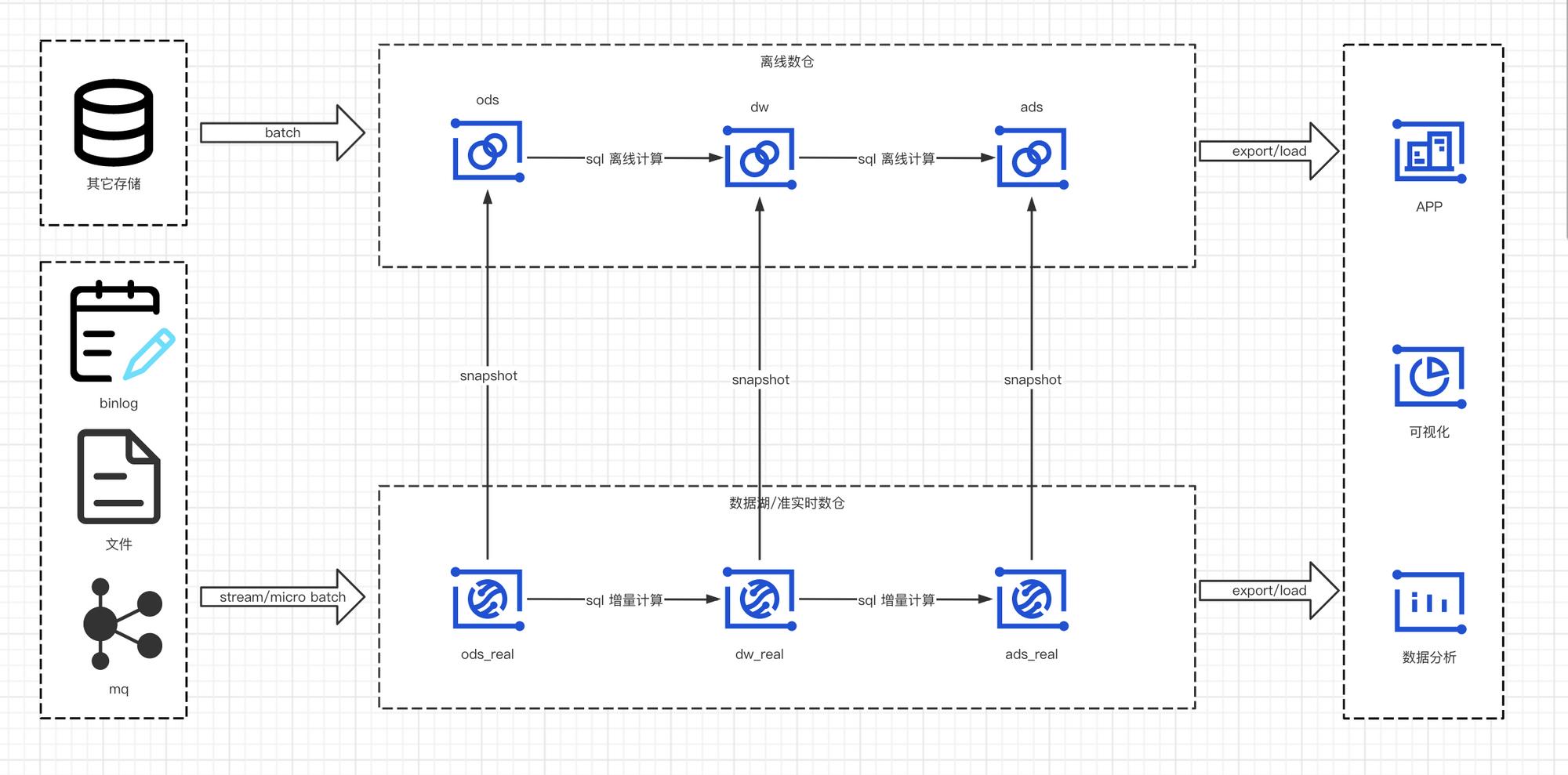
在数仓中,我们根据业务要求的数据时效性划分为离线数仓和近实时数仓,其中离线数仓(离线、准实时计算)由 spark sql 实现,近实时数仓由数据湖增量计算实现。在我们内部无论是增量计算还是离线计算,全部在 dag 离线调度平台 hera 上进行周期调度。
而对于不同层级,也有不同的计算方式
ods层- 近实时数仓:由一个
spark或者flink任务来微批同步binlog、日志文件、kafka等实时产生的数据,内部使用的是spark structured streaming来执行,结构化流支持Trigger once的触发方式,在调度系统周期调度时能自动从上次的checkpoint位置继续消费 - 离线数仓:为了降低对其它存储的压力,对于一些已经存在于近实时数仓的数据,每天零点以快照的方式存储一份数据到离线数仓,无需重复抽取。对于一些不在近实时数仓的数据直连相应数据源,使用
sqoop、dataX等方式离线同步即可
- 近实时数仓:由一个
dw层- 近实时数仓: 直接由近实时数仓
ods层增量计算得出 - 离线数仓:对于一些离线数仓需要的,近实时数仓存在的表每天零点仍然以快照的方式同步到离线数仓,一些只有离线需求的业务直接离线计算即可
- 近实时数仓: 直接由近实时数仓
ads层- 近实时数仓:和
dw层类似。 - 离线数仓:和
dw层类似。
- 近实时数仓:和
最终,无论是离线数仓还是近实时数仓的数据以直连、导出或者接口的方式提供给外部。
实际上这里有一个问题,为何不能所有的离线计算改为近实时计算呢?考虑主要有两个
一:在数据湖中,更新通常是以文件的变更来实现的,微批处理的时延越低,保存的时间越久,小文件的个数也就越多,无论是对文件管理服务如namenode 的压力,还是对读取数据的性能都会越来越低。一般我们数仓中的数据都是永久保存或者配置 TTL 只保存近几年的数据,如果在数据湖中数据的生命周期也保存如此久,小文件数量会暴增,产生其它意想不到的事故。 所以数据湖中保存近一周的数据变更即可,查询一周前的镜像数据可以到离线数仓查询。
二:基于成本的考虑,大家都知道,在相同业务下,通常时延要求越低的所消耗的资源成本越高即:实时>近实时>离线。对于一些离线计算就能满足的业务场景,直接进行离线计算即可,没必要进行实时或者近实时计算。
架构选型
该架构依赖以下几个数据库的特性
ACID:作为一个存储必须要有,无需多言- 增量查询 :既然要做增量计算,为了读取和写入的性能,那么不可能再像传统数仓那样,扫描所有数据文件再进行
insert overwrite - 高效
upsert:要实现近实时,对upsert性能要求比较高 - 时间旅行:为了保证离线数仓做snapshot的幂等,该功能需要支持
经过对 delta lake、iceberg 和 hudi 的对比,我们最终选择了 hudi,最新的对比可查看文末 onehouse 的对比。得益于 timeline 的 MVCC 设计,HUDI 实现了 ACID、增量查询、时间旅行。同时 mor、cow 两种不同的表格式来支持写多读少、和读多写少的场景。不同的索引类型(bucket index, bloom index, hbase index等)实现了高效的 upsert,恰当的解决了我们的所有痛点。
HUDI 表CRUD
建表
如下创建一个表类型为 merge on read,主键为 id,预合并字段为gmt_modified,并由 dt、hour 二级分区的建表语句
create table bi_dw.dim_test (
id bigint,
name string,
gmt_modified bigint,
dt string,
hour string
) using hudi
tblproperties (
type = 'mor',
primaryKey = 'id',
preCombineField = 'gmt_modified'
)
partitioned by (dt, hour)
location '/tmp/hudi/dim_test';
对于非 ods 层的 hudi 表我们通常以如上的方式建表。而对于 ods 层,由于需要读取其它存储的数据(binglog、file、mq),目前无法像 flink 那样创建一个 source 表来做,所以需要开发一个 spark/flink 程序来做 hudi的写入(也可以使用官方提供的 DeltaStreamer),然后周期调度即可。对于已经存在数据的 ods 表的建表语句:
create table bi_ods.ods_table using hudi location '/tmp/hudi/ods_table';
建表时,我们无须指定表的配置和 schema,hudi 会自动根据表 location下的元信息识别表的配置和schema.
数据读取
之前无法全部用 sql 来做的主要原因是无法通过 spark sql 来对 hudi 表进行增量读,快照读。但是在 HUDI-3161上,ForwardXu 大佬在 spark sql 上支持了 call 命令。通过 call 命令我们可以在 spark-sql console 来完成一些运维操作,比如执行 compact,执行 clean,查看提交记录等等。在这里我看到了读取 hudi 增量数据、快照数据的契机,于是新增了一个copy_to_table 命令,该命令可以把 hudi 表的数据以增量、快照、读优化等读取方式复制数据到 hive 表,于是于我们在 spark-sql 里面读取 hudi 表数据就变成了如下方式:
# read snapshot data from hudi table
call copy_to_table(table=>'$tableName',new_table=>'$viewName',query_type=>'snapshot',as_of_instant=>'20221018055647688')
select * from $viewName
# read incremental data from hudi table
call copy_to_table(table=>'$tableName',new_table=>'$viewName',query_type=>'incremental',begin_instance_time=>'20221018055647688')
select * from $viewName
# read read_optimized data from hudi table
call copy_to_table(table=>'$tableName',new_table=>'$viewName',query_type=>'read_optimized')
select * from $viewName
数据插入
如果能保证数据是新增的,那么直接执行 insert 语句即可。但是 hudi 表中如果已经存在相同主键的数据,将会导致数据重复,建议使用下面的 merge 语句插入。
插入数据到非分区表
insert into hudi_tbl select 1, 'a1', 20;
插入数据到动态分区
insert into hudi_tbl_part partition (dt, hh)
select 1 as id, 'a1' as name, 1000 as ts, '2021-12-09' as dt, '10' as hh;
插入数据到指定分区
insert into hudi_tbl_part partition(dt = '2021-12-09', hh='11') select 2, 'a2', 1000;
数据删除
hudi 允许删除用户指定的数据,语法如下:
DELETE FROM tableIdentifier [ WHERE BOOL_EXPRESSION]
delete from hudi_mor_tbl where id % 2 = 0;
数据更新
update hudi_mor_tbl set price = price * 2, gmt_modified = 1111 where id = 1;
update hudi_cow_pt_tbl set gmt_modified = 1001 where name = 'a1';
hudi 允许使用任意条件来进行数据的更新,但是要求预合并的字段(本文为gmt_modified)一定要更新,否则将会报错。
除了使用 update 语句外,hudi 还支持更强大的 merge 语句。该语句可以根据不同的条件对目标表数据进行更新、删除、和新增。
create table merge_source2 (id int, name string, flag string, dt string, hh string) using parquet;
insert into merge_source2 values (1, "new_a1", 'update', '2021-12-09', '10'), (2, "new_a2", 'delete', '2021-12-09', '11'), (3, "new_a3", 'insert', '2021-12-09', '12');
merge into hudi_cow_pt_tbl as target
using (
select id, name, '1000' as ts, flag, dt, hh from merge_source2
) as source
on target.id = source.id
when matched and flag != 'delete' then
update set id = source.id, name = source.name, ts = source.ts, dt = source.dt, hh = source.hh
when matched and flag = 'delete' then delete
when not matched then
insert (id, name, ts, dt, hh) values(source.id, source.name, source.ts, source.dt, source.hh)
;
其中 target 作为目标表,merge_source2 为增量数据,join 的条件为target.id = source.id.当满足条件时,判断 flag 如果不等于 delete,则进行数据的更新,flag 如果等于 delete 则删除数据。如果 target.id = source.id 条件不满足,即对于不存在目标表的增量数据直接新增即可
近实时调度
大数据离线调度平台基本都支持定时调度、依赖调度、自依赖调度等调度方式,除此之外在脚本开发时还支持一些内部时间表达式,比如 hera 调度系统的时间表达式为:
select * from xx_part where dt = $zdt.addDay(-1).format("yyyyMMdd")
select * from xx_part where dt = current_date();
表达式的 zdt 对象为当前任务的调度时间,该表达式的结果为调度时间减一天,并将日期格式化为 yyyyMMdd 格式,此表达式在数仓做 T-1 的离线计算时经常用到。而下面的 current_date 为任务运行时时间,在任务延迟执行的情况下会导致业务计算出错,谁用谁坑。
说到这里了,在这里就简单解释下调度时间,在调度系统中,一般分为业务时间、调度时间、触发时间。
- 调度时间:为调度实际应该被触发的时间,每天
0点的任务,会生成一个0点的调度时间,该任务会在0点进入任务队列,但是并不表示计算业务已经开始运行。即使任务的运行时间已经延迟,调度时间始终不变。 - 业务时间:计算的业务数据所在的时间,通常由调度时间计算而来,比如
T-1的计算,就是以调度时间减1天作为业务时间,计算业务时间指定的分区数据。 - 触发时间:任务实际开始运行的时间,大数据的离线计算对于调度时间的精确性的要求并没有那么高,也就是说即使我配置了一个
0点计算的任务,但是可能因为资源等问题导致任务阻塞10分钟后才运行也没有关系,而这里的00:10分就是触发时间。
正是调度时间这种不变的特性,所以在调度系统中,我们通常只使用调度时间进行业务时间的计算,而不是以触发时间。
在此贴一下近实时调度的依赖关系:
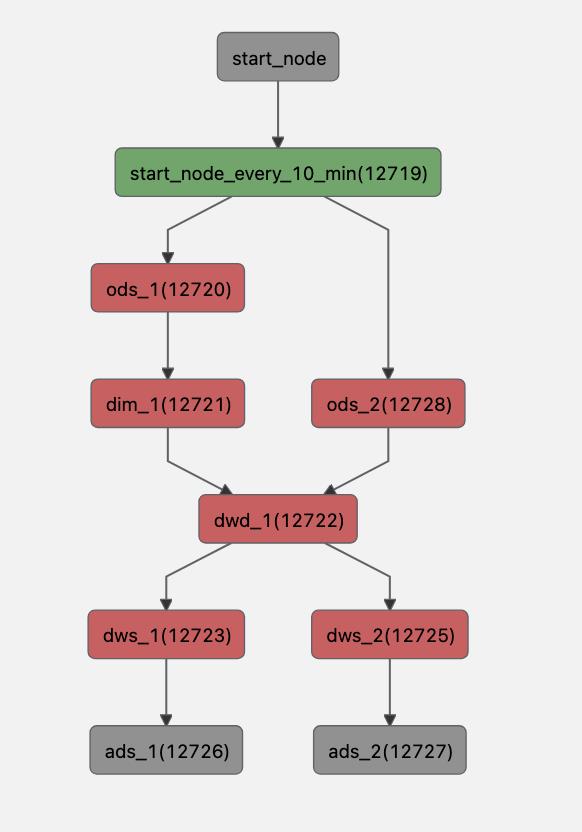
我们在离线调度平台上要实现近实时数仓的计算,任务的开始节点为一个每 1-30 分钟执行一次的定时任务,下游任务根据业务场景以依赖调度进行计算,最主要的就是如何通过调度的方式做增量计算。
近实时数仓的所有表均为 hudi 表,所有的计算均为增量计算,以上图的dwd_1 任务举例子,我们读取上游表的增量数据时可以通过以下表达式读取
call copy_to_table(table=>'dim_1',new_table=>'dim_1_view',query_type=>'snapshot',as_of_instant=>'$zdt.addMinutes(-10).format("yyyyMMddHHmmssSSS")')
call copy_to_table(table=>'ods_2',new_table=>'ods_2_view',query_type=>'incremental',begin_instance_time=>'$zdt.addMinutes(-10).format("yyyyMMddHHmmssSSS")')
with source as (
select id,name,price,gmt_modified from ods_2_view
left join dim_1_view
on dim_1_view.id = ods_2_view.id
)
merge into dwd_1 as target
using source on target.id=source.id
when matched then update set *
when not matched then insert *
$zdt.addMinutes(-10).format("yyyyMMddHHmmssSSS") 表达式将任务的调度时间减去 10 分钟并格式化为 yyyyMMddHHmmssSSS 格式作为其业务时间,表示 M-10 的计算。
所以前两行的含义为:分别复制 dim_1 十分钟前的快照数据和 ods_2 最近 10 分钟的增量数据到 dim_1_view 和 ods_2_view。
然后注册一个 source 视图,该试图由 ods_2_view 和 dim_1_view 通过 id 关联得到,然后将 source 视图的数据通过 merge into 语句写入到 dwd_1 表。该语法通过 source.id = target.id 进行关联,如果能够关联到,更新 dwd_1 表的该行数据。如果关联不到直接插入 source 视图的该行数据。
尾语
通过本篇文章叙述了使用 hudi、spark sql 实现近实时数仓的架构方式。还有很多不完美的地方,需要继续完善,抛砖引玉,为大家提供一份可以参考的方案。
实际上 copy_to_table 需要将 hudi 表数据 copy 一份落盘,是比较耗时的。所以我又新增了一个 copy_to_temp_view 的命令,该命令会将 hudi 表注册为 spark 的临时视图表,节省了落盘的时间,预计会在 0.13.0 版本能够使用。
注:以上使用的 hudi 版本为 0.12.1, spark 版本为 3.2.2
本文引用的链接:
[1]: Apache Hudi 文档 https://hudi.apache.org
[2]: hera 离线调度系统 https://github.com/scxwhite/hera
[3]: Apache Hudi vs Delta Lake vs Apache Iceberg - Lakehouse Feature Comparison https://www.onehouse.ai/blog/apache-hudi-vs-delta-lake-vs-apache-iceberg-lakehouse-feature-comparison
[4]: HUDI-3161 call produce command pr https://github.com/apache/hudi/pull/4535
[5]: HUDI-4367 copyToTable pr https://github.com/apache/hudi/pull/6054
[6]: HUDI-5048 copy_to_temp_view pr https://github.com/apache/hudi/pull/6990
以上是关于基于 Apache Hudi 和 Apache Spark Sql 的近实时数仓架构分享的主要内容,如果未能解决你的问题,请参考以下文章