GraphX迭代的瓶颈与分析
Posted 张包峰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GraphX迭代的瓶颈与分析相关的知识,希望对你有一定的参考价值。
背景
测试了一个case,用GraphX 1.6跑标准的LPA算法,使用的是内置的LabelPropagation算法包。数据集是Google web graph,(忽略可能这个数据集不是很合适),资源情况是standalone模式,18个worker,每个worker起一个executor,50g内存,32核,数据加载成18个分区。
case里执行200轮迭代,代码:
import org.apache.spark._
import org.apache.spark.graphx._
import org.apache.spark.graphx.lib._
// load the graph
val google = GraphLoader.edgeListFile(sc, "/home/admin/benchmark/data/google/web-Google.txt", false, 18)
LabelPropagation.run(google, 200)GraphX的执行方式
graphx的LPA是使用自己封装的Pregel跑的,先说优点,问题在后面暴露后分析:
1. 包掉了使用VertexRDD和EdgeRDD做BSP的过程,api简单,泛型清晰
2. 某轮迭代完成后,本轮没有msg流动的话,判定早停,任务结束
3. 迭代开始前,graph自动cache,结束后,某些中间结果rdd自动uncache
代码如下:
def apply[VD: ClassTag, ED: ClassTag, A: ClassTag]
(graph: Graph[VD, ED],
initialMsg: A,
maxIterations: Int = Int.MaxValue,
activeDirection: EdgeDirection = EdgeDirection.Either)
(vprog: (VertexId, VD, A) => VD,
sendMsg: EdgeTriplet[VD, ED] => Iterator[(VertexId, A)],
mergeMsg: (A, A) => A)
: Graph[VD, ED] =
var g = graph.mapVertices((vid, vdata) => vprog(vid, vdata, initialMsg)).cache()
// compute the messages
var messages = g.mapReduceTriplets(sendMsg, mergeMsg)
var activeMessages = messages.count()
// Loop
var prevG: Graph[VD, ED] = null
var i = 0
while (activeMessages > 0 && i < maxIterations)
// Receive the messages and update the vertices.
prevG = g
g = g.joinVertices(messages)(vprog).cache()
val oldMessages = messages
// Send new messages, skipping edges where neither side received a message. We must cache
// messages so it can be materialized on the next line, allowing us to uncache the previous
// iteration.
messages = g.mapReduceTriplets(
sendMsg, mergeMsg, Some((oldMessages, activeDirection))).cache()
// The call to count() materializes `messages` and the vertices of `g`. This hides oldMessages
// (depended on by the vertices of g) and the vertices of prevG (depended on by oldMessages
// and the vertices of g).
activeMessages = messages.count()
logInfo("Pregel finished iteration " + i)
// Unpersist the RDDs hidden by newly-materialized RDDs
oldMessages.unpersist(blocking = false)
prevG.unpersistVertices(blocking = false)
prevG.edges.unpersist(blocking = false)
// count the iteration
i += 1
g
// end of applySparkDriver成为瓶颈
driver是提交任务的入口,但同时”监督”了本次DAG的执行过程。在默认1g内存的情况下,任务执行10min后,driver端抛了OOM异常,稳定复现,截取两次堆栈:
这一次发生于执行rdd checkpoint依赖链相关的操作。
Exception in thread "dag-scheduler-event-loop" java.lang.OutOfMemoryError: GC overhead limit exceeded
at org.apache.spark.rdd.RDD.checkpointRDD(RDD.scala:217)
at org.apache.spark.rdd.RDD.dependencies(RDD.scala:224)
at org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$visit$1(RDD.scala:283)
at org.apache.spark.rdd.RDD$$anonfun$org$apache$spark$rdd$RDD$$visit$1$1.apply(RDD.scala:288)
at org.apache.spark.rdd.RDD$$anonfun$org$apache$spark$rdd$RDD$$visit$1$1.apply(RDD.scala:286)
...这一次发生于创建ShuffleMapStage(即生成执行计划,提交出去之前)
Exception in thread "dag-scheduler-event-loop" java.lang.OutOfMemoryError: GC overhead limit exceeded
...
org.apache.spark.storage.RDDInfo$.fromRdd(RDDInfo.scala:58)
at org.apache.spark.scheduler.StageInfo$$anonfun$1.apply(StageInfo.scala:80)
at org.apache.spark.scheduler.StageInfo$$anonfun$1.apply(StageInfo.scala:80)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at org.apache.spark.scheduler.StageInfo$.fromStage(StageInfo.scala:80)
at org.apache.spark.scheduler.Stage.<init>(Stage.scala:99)
at org.apache.spark.scheduler.ShuffleMapStage.<init>(ShuffleMapStage.scala:36)
at org.apache.spark.scheduler.DAGScheduler.newShuffleMapStage(DAGScheduler.scala:317)
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$newOrUsedShuffleStage(DAGScheduler.scala:352)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$org$apache$spark$scheduler$DAGScheduler$$getShuffleMapStage$1.apply(DAGScheduler.scala:286)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$org$apache$spark$scheduler$DAGScheduler$$getShuffleMapStage$1.apply(DAGScheduler.scala:285)
...把spark.driver.memory设大10g后,截止此时,Pregel迭代到175轮,任务进行了29min,driver内存使用稳定在10g,gc情况如下:

ygc和fgc使得driver端成为整个迭代任务的瓶颈。
worker端,executor的内存使用和cpu压力是不大的,内存温度在16g,cpu最高的时候不超过250%

UI上job运行timeline:
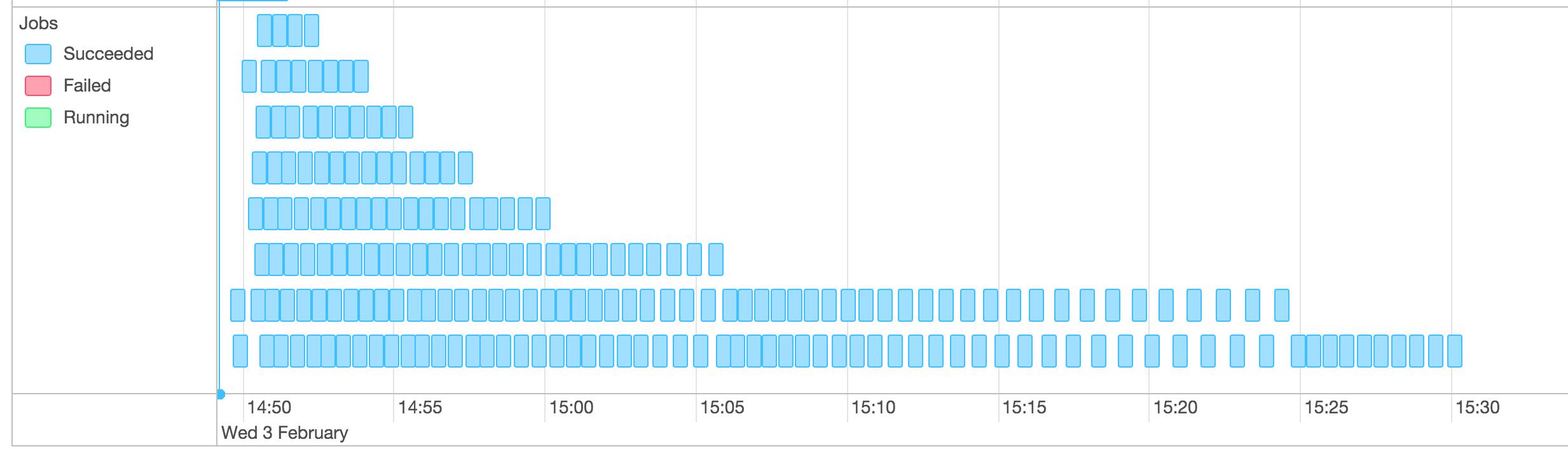
最终任务在45min左右结束,driver端在10g内存下ygc 760次,fgc 31次。
分析
GraphX跑迭代图算法的方式,相当于是提交n次spark job。第一,spark得把DAG的生成和提交做的很快,开销足够小;第二,stage执行过程中的事件传输和响应代价也需要足够小。
实际上,内存消耗的重头是图(rdd)之间的血缘(为failover做cp)。其他开销是接收和处理每次迭代每个stage的状态、起停等。
下图是跑了20min左右,10g内存已经吃完时候的histo:
num #instances #bytes class name
----------------------------------------------
1: 64438657 1546527768 scala.collection.immutable.$colon$colon
2: 15713541 1131374952 org.apache.spark.storage.RDDInfo
3: 32323255 517172080 java.lang.Integer
4: 1420435 363557008 [B
5: 4116166 328222184 [I
6: 2804579 316599136 [Ljava.lang.Object;
7: 6750506 314468944 [C
8: 9262969 296415008 scala.collection.mutable.ListBuffer
9: 6468190 155236560 java.lang.String
10: 4364012 69824192 org.apache.spark.rdd.RDD$$anonfun$checkpointRDD$1
11: 896697 64562184 java.util.regex.Pattern
12: 896648 57385472 java.util.regex.Matcher
13: 3484333 55749328 org.apache.spark.rdd.RDD$$anonfun$dependencies$1
14: 1742140 55748480 org.apache.spark.scheduler.DAGScheduler$$anonfun$visit$1$1
15: 896618 50210608 [Ljava.util.regex.Pattern$GroupHead;
16: 371868 46546816 [Lscala.collection.mutable.HashEntry;
17: 1728270 41478480 scala.collection.mutable.ArrayBuffer
18: 1670208 40084992 scala.collection.mutable.DefaultEntry
19: 2312219 36995504 scala.collection.generic.Growable$$anonfun$$plus$plus$eq$1
20: 1355395 32529480 org.apache.spark.ui.scope.RDDOperationEdge
21: 1309374 31424976 org.apache.spark.scheduler.CompressedMapStatus里面RDDInfo基本就是血缘依赖链的内存证据,其余包括checkpointRDD, RDD dependencies等
class RDDInfo(
val id: Int,
val name: String,
val numPartitions: Int,
var storageLevel: StorageLevel,
val parentIds: Seq[Int],
val callSite: String = "",
val scope: Option[RDDOperationScope] = None)
extends Ordered[RDDInfo] 同样这个任务,使用我们自己的计算框架以流式迭代的方式跑的结果是几百秒,没有什么优化,与小轮次跑出的时间基本上呈线性。GraphX在小轮次(driver不是瓶颈)的执行时间也比我们慢几倍,但是我觉得差距还不够大,所以待进一步提高后再说。
思考
这是一个典型的case,LPA在fn里的执行复杂度是很低的,基本上没什么计算复杂度和开销。数据量也并不大。但是迭代次数比较多,但也不夸张。shuffle过程中,带出去的点属性也只是一个Map,k和v都是原生类型(long和int),所以序列化和payload也不是问题。
这个case让我看到GraphX跑大迭代图算法时,driver会成为瓶颈。当然GraphX为每轮graph做了cp。但是设想一个上规模的spark集群,有很多人要来跑图任务,哪怕executor没有问题,driver要开掉多少资源?
如果GraphX要做大迭代的话,需要手动写成跑n轮cache一把图,再继续的方式跑。这种方式下的n过小,还是会因为血缘而OOM,n过大,除了cp问题,在我看来把DAG展开成几百个stage跑也是个问题。
如果往上线支持图业务的角度看的话,其实GraphX的loader也是个问题。GraphX的建模过程很简单也很快,但是建好的graph要更新的话,需要把增量部分先load一把,然后做类似两个graph的join。所以说GraphX让用户看到api写起来很简单很舒服,代价是不灵活的内置图建模过程,这倒不如计算和存储分开,计算只要存储的一份建模元信息就可以跑了。
这样看,首先,GraphX并不适合大迭代轮次的计算,qps几乎为0;其次,GraphX不适合图数据更新的场景,开发者可以加额外的工作和方法去做到,但其本身其实没有考虑这个问题。至于GraphX适不适合大图的计算先不说。
在我看来GraphX只适合做数据分析链中的一环,几乎没有单独做图业务上生产环境的可能性。
以上是关于GraphX迭代的瓶颈与分析的主要内容,如果未能解决你的问题,请参考以下文章